 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
ViSS-R1: Self-Supervised Reinforcement Video Reasoning
Nov 17, 2025Complex video reasoning remains a significant challenge for Multimodal Large Language Models (MLLMs), as current R1-based methodologies often prioritize text-centric reasoning derived from text-based and image-based developments. In video tasks, such strategies frequently underutilize rich visual information, leading to potential shortcut learning and increased susceptibility to hallucination. To foster a more robust, visual-centric video understanding, we start by introducing a novel self-supervised reinforcement learning GRPO algorithm (Pretext-GRPO) within the standard R1 pipeline, in which positive rewards are assigned for correctly solving pretext tasks on transformed visual inputs, which makes the model to non-trivially process the visual information. Building on the effectiveness of Pretext-GRPO, we further propose the ViSS-R1 framework, which streamlines and integrates pretext-task-based self-supervised learning directly into the MLLM's R1 post-training paradigm. Instead of relying solely on sparse visual cues, our framework compels models to reason about transformed visual input by simultaneously processing both pretext questions (concerning transformations) and true user queries. This necessitates identifying the applied transformation and reconstructing the original video to formulate accurate final answers. Comprehensive evaluations on six widely-used video reasoning and understanding benchmarks demonstrate the effectiveness and superiority of our Pretext-GRPO and ViSS-R1 for complex video reasoning. Our codes and models will be publicly available.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Mixture-of-Experts Meets In-Context Reinforcement Learning
Jun 05, 2025In-context reinforcement learning (ICRL) has emerged as a promising paradigm for adapting RL agents to downstream tasks through prompt conditioning. However, two notable challenges remain in fully harnessing in-context learning within RL domains: the intrinsic multi-modality of the state-action-reward data and the diverse, heterogeneous nature of decision tasks. To tackle these challenges, we propose \textbf{T2MIR} (\textbf{T}oken- and \textbf{T}ask-wise \textbf{M}oE for \textbf{I}n-context \textbf{R}L), an innovative framework that introduces architectural advances of mixture-of-experts (MoE) into transformer-based decision models. T2MIR substitutes the feedforward layer with two parallel layers: a token-wise MoE that captures distinct semantics of input tokens across multiple modalities, and a task-wise MoE that routes diverse tasks to specialized experts for managing a broad task distribution with alleviated gradient conflicts. To enhance task-wise routing, we introduce a contrastive learning method that maximizes the mutual information between the task and its router representation, enabling more precise capture of task-relevant information. The outputs of two MoE components are concatenated and fed into the next layer. Comprehensive experiments show that T2MIR significantly facilitates in-context learning capacity and outperforms various types of baselines. We bring the potential and promise of MoE to ICRL, offering a simple and scalable architectural enhancement to advance ICRL one step closer toward achievements in language and vision communities. Our code is available at https://github.com/NJU-RL/T2MIR.
Threading Keyframe with Narratives: MLLMs as Strong Long Video Comprehenders
May 30, 2025Employing Multimodal Large Language Models (MLLMs) for long video understanding remains a challenging problem due to the dilemma between the substantial number of video frames (i.e., visual tokens) versus the limited context length of language models. Traditional uniform sampling often leads to selection of irrelevant content, while post-training MLLMs on thousands of frames imposes a substantial computational burden. In this paper, we propose threading keyframes with narratives (Nar-KFC), a plug-and-play module to facilitate effective and efficient long video perception. Nar-KFC generally involves two collaborative steps. First, we formulate the keyframe selection process as an integer quadratic programming problem, jointly optimizing query-relevance and frame-diversity. To avoid its computational complexity, a customized greedy search strategy is designed as an efficient alternative. Second, to mitigate the temporal discontinuity caused by sparse keyframe sampling, we further introduce interleaved textual narratives generated from non-keyframes using off-the-shelf captioners. These narratives are inserted between keyframes based on their true temporal order, forming a coherent and compact representation. Nar-KFC thus serves as a temporal- and content-aware compression strategy that complements visual and textual modalities. Experimental results on multiple long-video benchmarks demonstrate that Nar-KFC significantly improves the performance of popular MLLMs. Code will be made publicly available.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
Text-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Apr 22, 2025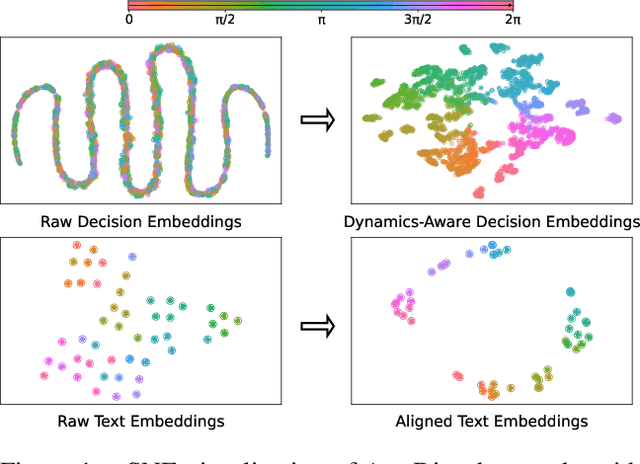

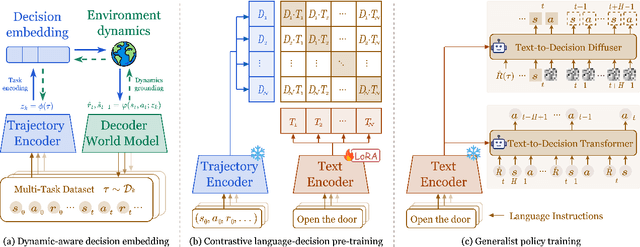
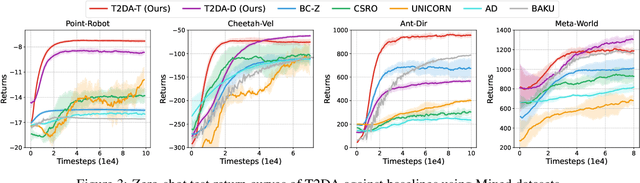
RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision
Feb 28, 2025



Recent advances in Large Language Models (LLMs) have highlighted the challenge of handling long-context tasks, where models need to reason over extensive input contexts to aggregate target information. While Chain-of-Thought (CoT) prompting has shown promise for multi-step reasoning, its effectiveness for long-context scenarios remains underexplored. Through systematic investigation across diverse tasks, we demonstrate that CoT's benefits generalize across most long-context scenarios and amplify with increasing context length. Motivated by this critical observation, we propose LongRePS, a process-supervised framework that teaches models to generate high-quality reasoning paths for enhanced long-context performance. Our framework incorporates a self-sampling mechanism to bootstrap reasoning paths and a novel quality assessment protocol specifically designed for long-context scenarios. Experimental results on various long-context benchmarks demonstrate the effectiveness of our approach, achieving significant improvements over outcome supervision baselines on both in-domain tasks (+13.6/+3.8 points for LLaMA/Qwen on MuSiQue) and cross-domain generalization (+9.3/+8.1 points on average across diverse QA tasks). Our code, data and trained models are made public to facilitate future research.
IU4Rec: Interest Unit-Based Product Organization and Recommendation for E-Commerce Platform
Feb 11, 2025Most recommendation systems typically follow a product-based paradigm utilizing user-product interactions to identify the most engaging items for users. However, this product-based paradigm has notable drawbacks for Xianyu~\footnote{Xianyu is China's largest online C2C e-commerce platform where a large portion of the product are post by individual sellers}. Most of the product on Xianyu posted from individual sellers often have limited stock available for distribution, and once the product is sold, it's no longer available for distribution. This result in most items distributed product on Xianyu having relatively few interactions, affecting the effectiveness of traditional recommendation depending on accumulating user-item interactions. To address these issues, we introduce \textbf{IU4Rec}, an \textbf{I}nterest \textbf{U}nit-based two-stage \textbf{Rec}ommendation system framework. We first group products into clusters based on attributes such as category, image, and semantics. These IUs are then integrated into the Recommendation system, delivering both product and technological innovations. IU4Rec begins by grouping products into clusters based on attributes such as category, image, and semantics, forming Interest Units (IUs). Then we redesign the recommendation process into two stages. In the first stage, the focus is on recommend these Interest Units, capturing broad-level interests. In the second stage, it guides users to find the best option among similar products within the selected Interest Unit. User-IU interactions are incorporated into our ranking models, offering the advantage of more persistent IU behaviors compared to item-specific interactions. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness and superiority of our proposed IU-centric recommendation approach.