 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360-LLaMA-Factory: Plug & Play Sequence Parallelism for Long Post-Training
May 28, 2025Adding sequence parallelism into LLaMA-Factory, we open-sourced 360-LLaMA-Factory at https://github.com/Qihoo360/360-LLaMA-Factory. 360-LLaMA-Factory has received wide recognition and used in models such as Light-R1 arXiv:2503.10460, TinyR1 arXiv:2503.04872, Kaggle AIMO math models and also in large companies' training frameworks. This technical report delves deeper into the different sequence parallel modes behind 360-LLaMA-Factory and discusses our implementation insights.
Light-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
Mar 13, 2025This paper presents our work on the Light-R1 series, with models, data, and code all released. We first focus on training long COT models from scratch, specifically starting from models initially lacking long COT capabilities. Using a curriculum training recipe consisting of two-stage SFT and semi-on-policy DPO, we train our model Light-R1-32B from Qwen2.5-32B-Instruct, resulting in superior math performance compared to DeepSeek-R1-Distill-Qwen-32B. Despite being trained exclusively on math data, Light-R1-32B shows strong generalization across other domains. In the subsequent phase of this work, we highlight the significant benefit of the 3k dataset constructed for the second SFT stage on enhancing other models. By fine-tuning DeepSeek-R1-Distilled models using this dataset, we obtain new SOTA models in 7B and 14B, while the 32B model, Light-R1-32B-DS performed comparably to QwQ-32B and DeepSeek-R1. Furthermore, we extend our work by applying reinforcement learning, specifically GRPO, on long-COT models to further improve reasoning performance. We successfully train our final Light-R1-14B-DS with RL, achieving SOTA performance among 14B parameter models in math. With AIME24 & 25 scores of 74.0 and 60.2 respectively, Light-R1-14B-DS surpasses even many 32B models and DeepSeek-R1-Distill-Llama-70B. Its RL training also exhibits well expected behavior, showing simultaneous increase in response length and reward score. The Light-R1 series of work validates training long-COT models from scratch, showcases the art in SFT data and releases SOTA models from RL.
Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision
Feb 28, 2025



Recent advances in Large Language Models (LLMs) have highlighted the challenge of handling long-context tasks, where models need to reason over extensive input contexts to aggregate target information. While Chain-of-Thought (CoT) prompting has shown promise for multi-step reasoning, its effectiveness for long-context scenarios remains underexplored. Through systematic investigation across diverse tasks, we demonstrate that CoT's benefits generalize across most long-context scenarios and amplify with increasing context length. Motivated by this critical observation, we propose LongRePS, a process-supervised framework that teaches models to generate high-quality reasoning paths for enhanced long-context performance. Our framework incorporates a self-sampling mechanism to bootstrap reasoning paths and a novel quality assessment protocol specifically designed for long-context scenarios. Experimental results on various long-context benchmarks demonstrate the effectiveness of our approach, achieving significant improvements over outcome supervision baselines on both in-domain tasks (+13.6/+3.8 points for LLaMA/Qwen on MuSiQue) and cross-domain generalization (+9.3/+8.1 points on average across diverse QA tasks). Our code, data and trained models are made public to facilitate future research.
Reward Shaping via Meta-Learning
Jan 27, 2019
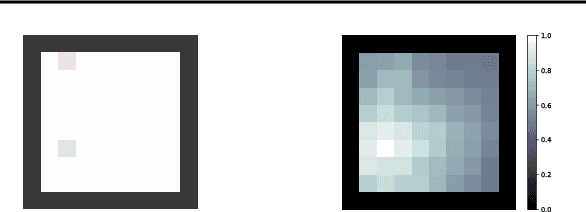
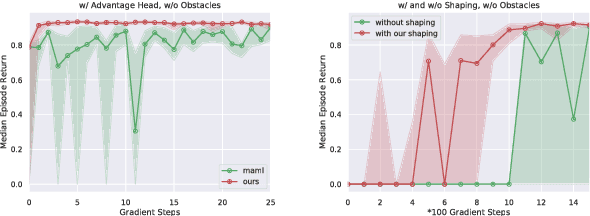

Reward shaping is one of the most effective methods to tackle the crucial yet challenging problem of credit assignment in Reinforcement Learning (RL). However, designing shaping functions usually requires much expert knowledge and hand-engineering, and the difficulties are further exacerbated given multiple similar tasks to solve. In this paper, we consider reward shaping on a distribution of tasks, and propose a general meta-learning framework to automatically learn the efficient reward shaping on newly sampled tasks, assuming only shared state space but not necessarily action space. We first derive the theoretically optimal reward shaping in terms of credit assignment in model-free RL. We then propose a value-based meta-learning algorithm to extract an effective prior over the optimal reward shaping. The prior can be applied directly to new tasks, or provably adapted to the task-posterior while solving the task within few gradient updates. We demonstrate the effectiveness of our shaping through significantly improved learning efficiency and interpretable visualizations across various settings, including notably a successful transfer from DQN to DDPG.
Understanding Human Behaviors in Crowds by Imitating the Decision-Making Process
Jan 25, 2018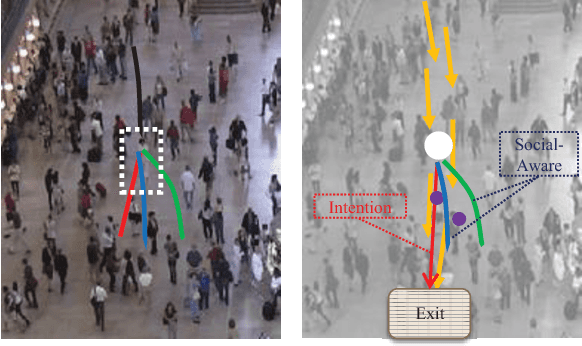
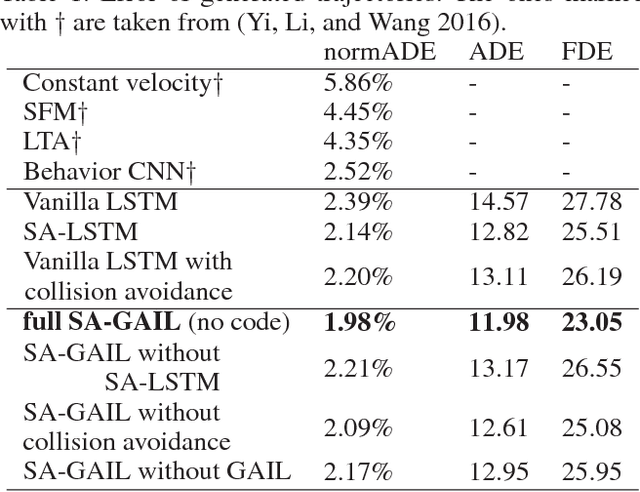
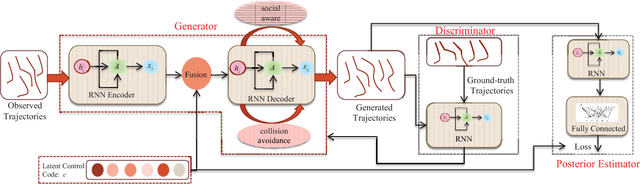
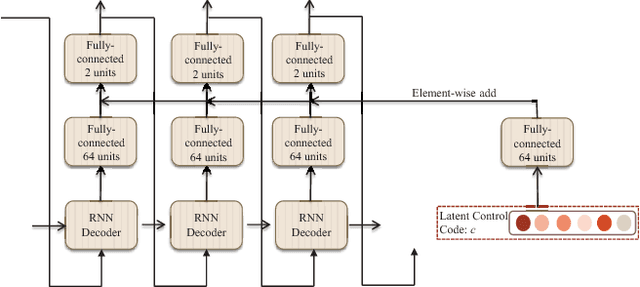
Crowd behavior understanding is crucial yet challenging across a wide range of applications, since crowd behavior is inherently determined by a sequential decision-making process based on various factors, such as the pedestrians' own destinations, interaction with nearby pedestrians and anticipation of upcoming events. In this paper, we propose a novel framework of Social-Aware Generative Adversarial Imitation Learning (SA-GAIL) to mimic the underlying decision-making process of pedestrians in crowds. Specifically, we infer the latent factors of human decision-making process in an unsupervised manner by extending the Generative Adversarial Imitation Learning framework to anticipate future paths of pedestrians. Different factors of human decision making are disentangled with mutual information maximization, with the process modeled by collision avoidance regularization and Social-Aware LSTMs. Experimental results demonstrate the potential of our framework in disentangling the latent decision-making factors of pedestrians and stronger abilities in predicting future trajectories.
The YouTube-8M Kaggle Competition: Challenges and Methods
Jul 13, 2017

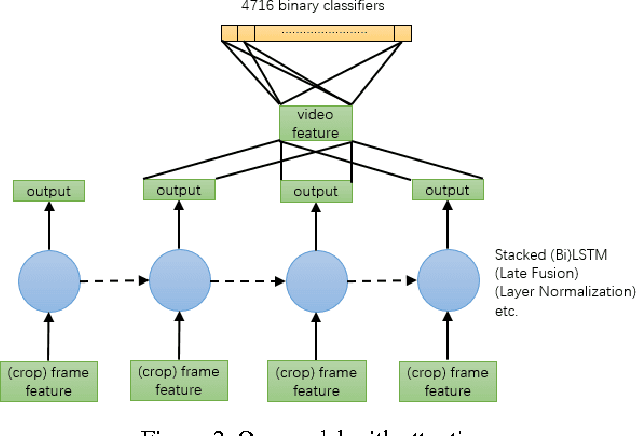

We took part in the YouTube-8M Video Understanding Challenge hosted on Kaggle, and achieved the 10th place within less than one month's time. In this paper, we present an extensive analysis and solution to the underlying machine-learning problem based on frame-level data, where major challenges are identified and corresponding preliminary methods are proposed. It's noteworthy that, with merely the proposed strategies and uniformly-averaging multi-crop ensemble was it sufficient for us to reach our ranking. We also report the methods we believe to be promising but didn't have enough time to train to convergence. We hope this paper could serve, to some extent, as a review and guideline of the YouTube-8M multi-label video classification benchmark, inspiring future attempts and research.