 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping via Meta-Learning
Paper and Code
Jan 27, 2019
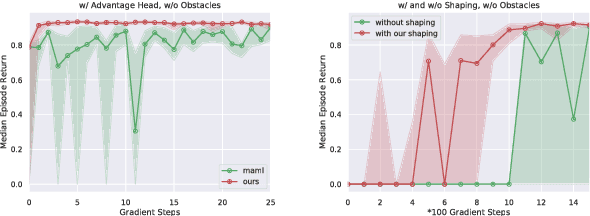

Reward shaping is one of the most effective methods to tackle the crucial yet challenging problem of credit assignment in Reinforcement Learning (RL). However, designing shaping functions usually requires much expert knowledge and hand-engineering, and the difficulties are further exacerbated given multiple similar tasks to solve. In this paper, we consider reward shaping on a distribution of tasks, and propose a general meta-learning framework to automatically learn the efficient reward shaping on newly sampled tasks, assuming only shared state space but not necessarily action space. We first derive the theoretically optimal reward shaping in terms of credit assignment in model-free RL. We then propose a value-based meta-learning algorithm to extract an effective prior over the optimal reward shaping. The prior can be applied directly to new tasks, or provably adapted to the task-posterior while solving the task within few gradient updates. We demonstrate the effectiveness of our shaping through significantly improved learning efficiency and interpretable visualizations across various settings, including notably a successful transfer from DQN to DDPG.