 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAIR: Improving Safety Alignment with Introspective Reasoning
Feb 04, 2025



Ensuring the safety and harmlessness of Large Language Models (LLMs) has become equally critical as their performance in applications. However, existing safety alignment methods typically suffer from safety-performance trade-offs and the susceptibility to jailbreak attacks, primarily due to their reliance on direct refusals for malicious queries. In this paper, we propose STAIR, a novel framework that integrates SafeTy Alignment with Itrospective Reasoning. We enable LLMs to identify safety risks through step-by-step analysis by self-improving chain-of-thought (CoT) reasoning with safety awareness. STAIR first equips the model with a structured reasoning capability and then advances safety alignment via iterative preference optimization on step-level reasoning data generated using our newly proposed Safety-Informed Monte Carlo Tree Search (SI-MCTS). We further train a process reward model on this data to guide test-time searches for improved responses. Extensive experiments show that STAIR effectively mitigates harmful outputs while better preserving helpfulness, compared to instinctive alignment strategies. With test-time scaling, STAIR achieves a safety performance comparable to Claude-3.5 against popular jailbreak attacks. Relevant resources in this work are available at https://github.com/thu-ml/STAIR.
Baichuan4-Finance Technical Report
Dec 17, 2024



Large language models (LLMs) have demonstrated strong capabilities in language understanding, generation, and reasoning, yet their potential in finance remains underexplored due to the complexity and specialization of financial knowledge. In this work, we report the development of the Baichuan4-Finance series, including a comprehensive suite of foundational Baichuan4-Finance-Base and an aligned language model Baichuan4-Finance, which are built upon Baichuan4-Turbo base model and tailored for finance domain. Firstly, we have dedicated significant effort to building a detailed pipeline for improving data quality. Moreover, in the continual pre-training phase, we propose a novel domain self-constraint training strategy, which enables Baichuan4-Finance-Base to acquire financial knowledge without losing general capabilities. After Supervised Fine-tuning and Reinforcement Learning from Human Feedback and AI Feedback, the chat model Baichuan4-Finance is able to tackle various financial certification questions and real-world scenario applications. We evaluate Baichuan4-Finance on many widely used general datasets and two holistic financial benchmarks. The evaluation results show that Baichuan4-Finance-Base surpasses almost all competitive baselines on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. At the same time, Baichuan4-Finance demonstrates even more impressive performance on financial application scenarios, showcasing its potential to foster community innovation in the financial LLM field.
Technical Report: Enhancing LLM Reasoning with Reward-guided Tree Search
Nov 18, 2024



Recently, test-time scaling has garnered significant attention from the research community, largely due to the substantial advancements of the o1 model released by OpenAI. By allocating more computational resources during the inference phase, large language models~(LLMs) can extensively explore the solution space by generating more thought tokens or diverse solutions, thereby producing more accurate responses. However, developing an o1-like reasoning approach is challenging, and researchers have been making various attempts to advance this open area of research. In this paper, we present a preliminary exploration into enhancing the reasoning abilities of LLMs through reward-guided tree search algorithms. This framework is implemented by integrating the policy model, reward model, and search algorithm. It is primarily constructed around a tree search algorithm, where the policy model navigates a dynamically expanding tree guided by a specially trained reward model. We thoroughly explore various design considerations necessary for implementing this framework and provide a detailed report of the technical aspects. To assess the effectiveness of our approach, we focus on mathematical reasoning tasks and conduct extensive evaluations on four challenging datasets, significantly enhancing the reasoning abilities of LLMs.
Boosting Deductive Reasoning with Step Signals In RLHF
Oct 12, 2024Logical reasoning is a crucial task for Large Language Models (LLMs), enabling them to tackle complex problems. Among reasoning tasks, multi-step reasoning poses a particular challenge. Grounded in the theory of formal logic, we have developed an automated method, Multi-step Deduction (MuseD), for deductive reasoning data. MuseD has allowed us to create training and testing datasets for multi-step reasoning. Our generation method enables control over the complexity of the generated instructions, facilitating training and evaluation of models across different difficulty levels. Through RLHF training, our training data has demonstrated significant improvements in logical capabilities for both in-domain of out-of-domain reasoning tasks. Additionally, we have conducted tests to assess the multi-step reasoning abilities of various models.
Uncertainty-aware Reward Model: Teaching Reward Models to Know What is Unknown
Oct 01, 2024Reward models (RM) play a critical role in aligning generations of large language models (LLM) to human expectations. However, prevailing RMs fail to capture the stochasticity within human preferences and cannot effectively evaluate the reliability of reward predictions. To address these issues, we propose Uncertain-aware RM (URM) and Uncertain-aware RM Ensemble (URME) to incorporate and manage uncertainty in reward modeling. URM can model the distribution of disentangled attributes within human preferences, while URME quantifies uncertainty through discrepancies in the ensemble, thereby identifying potential lack of knowledge during reward evaluation. Experiment results indicate that the proposed URM achieves state-of-the-art performance compared to models with the same size, demonstrating the effectiveness of modeling uncertainty within human preferences. Furthermore, empirical results show that through uncertainty quantification, URM and URME can identify unreliable predictions to improve the quality of reward evaluations.
3D-Properties: Identifying Challenges in DPO and Charting a Path Forward
Jun 11, 2024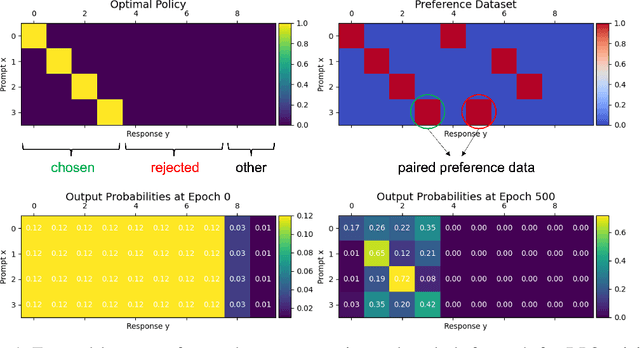
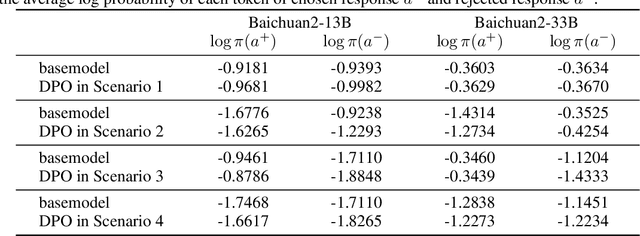
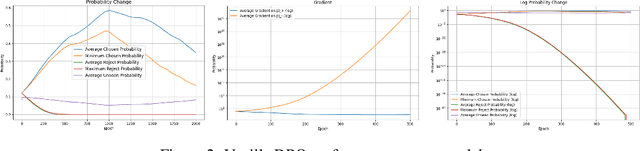
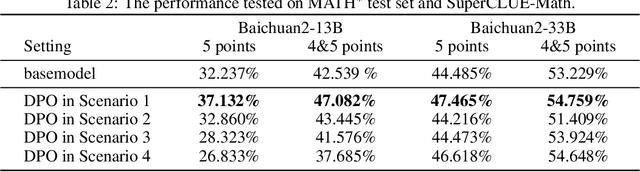
Aligning large language models (LLMs) with human preference has recently gained tremendous attention, with the canonical yet costly RLHF-PPO and the simple and straightforward Direct Preference Optimization (DPO) as two examples. Despite the efficiency, DPO has rarely be used in the state-of-the-art production-level LLMs, implying its potential pathologies. In this work, we revisit DPO with a comprehensive examination of its empirical efficacy and a systematic comparison with RLHF-PPO. We identify the \textbf{3D}-properties of DPO's learning outcomes: the \textbf{D}rastic drop in the likelihood of rejected responses, the \textbf{D}egradation into LLM unlearning, and the \textbf{D}ispersion effect on unseen responses through experiments with both a carefully designed toy model and practical LLMs on tasks including mathematical problem-solving and instruction following. These findings inherently connect to some observations made by related works and we additionally contribute a plausible theoretical explanation for them. Accordingly, we propose easy regularization methods to mitigate the issues caused by \textbf{3D}-properties, improving the training stability and final performance of DPO. Our contributions also include an investigation into how the distribution of the paired preference data impacts the effectiveness of DPO. We hope this work could offer research directions to narrow the gap between reward-free preference learning methods and reward-based ones.
Exploring the LLM Journey from Cognition to Expression with Linear Representations
May 27, 2024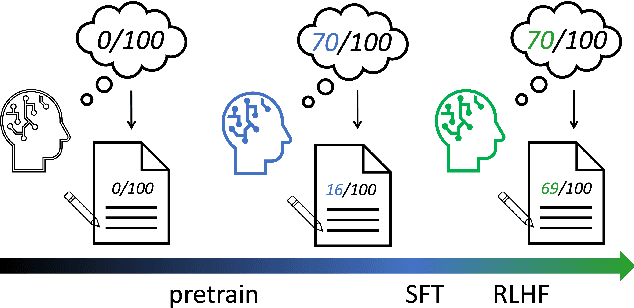

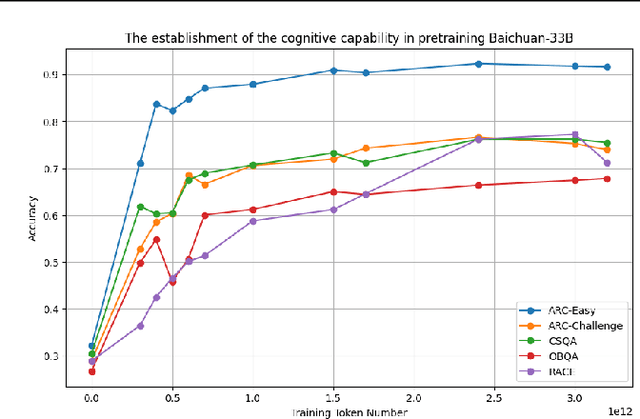

This paper presents an in-depth examination of the evolution and interplay of cognitive and expressive capabilities in large language models (LLMs), with a specific focus on Baichuan-7B and Baichuan-33B, an advanced bilingual (Chinese and English) LLM series. We define and explore the model's cognitive and expressive capabilities through linear representations across three critical phases: Pretraining, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). Cognitive capability is defined as the quantity and quality of information conveyed by the neuron output vectors within the network, similar to the neural signal processing in human cognition. Expressive capability is defined as the model's capability to produce word-level output. Our findings unveil a sequential development pattern, where cognitive abilities are largely established during Pretraining, whereas expressive abilities predominantly advance during SFT and RLHF. Statistical analyses confirm a significant correlation between the two capabilities, suggesting that cognitive capacity may limit expressive potential. The paper also explores the theoretical underpinnings of these divergent developmental trajectories and their connection to the LLMs' architectural design. Moreover, we evaluate various optimization-independent strategies, such as few-shot learning and repeated sampling, which bridge the gap between cognitive and expressive capabilities. This research reveals the potential connection between the hidden space and the output space, contributing valuable insights into the interpretability and controllability of their training processes.
SPO: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling
May 21, 2024



Human preference alignment is critical in building powerful and reliable large language models (LLMs). However, current methods either ignore the multi-dimensionality of human preferences (e.g. helpfulness and harmlessness) or struggle with the complexity of managing multiple reward models. To address these issues, we propose Sequential Preference Optimization (SPO), a method that sequentially fine-tunes LLMs to align with multiple dimensions of human preferences. SPO avoids explicit reward modeling, directly optimizing the models to align with nuanced human preferences. We theoretically derive closed-form optimal SPO policy and loss function. Gradient analysis is conducted to show how SPO manages to fine-tune the LLMs while maintaining alignment on previously optimized dimensions. Empirical results on LLMs of different size and multiple evaluation datasets demonstrate that SPO successfully aligns LLMs across multiple dimensions of human preferences and significantly outperforms the baselines.
Rethinking Information Structures in RLHF: Reward Generalization from a Graph Theory Perspective
Feb 20, 2024There is a trilemma in reinforcement learning from human feedback (RLHF): the incompatibility between highly diverse contexts, low labeling cost, and reliable alignment performance. Here we aim to mitigate such incompatibility through the design of dataset information structures during reward modeling, and meanwhile propose new, generalizable methods of analysis that have wider applications, including potentially shedding light on goal misgeneralization. Specifically, we first reexamine the RLHF process and propose a theoretical framework portraying it as an autoencoding process over text distributions. Our framework formalizes the RLHF objective of ensuring distributional consistency between human preference and large language model (LLM) behavior. Based on this framework, we introduce a new method to model generalization in the reward modeling stage of RLHF, the induced Bayesian network (IBN). Drawing from random graph theory and causal analysis, it enables empirically grounded derivation of generalization error bounds, a key improvement over classical methods of generalization analysis. An insight from our analysis is the superiority of the tree-based information structure in reward modeling, compared to chain-based baselines in conventional RLHF methods. We derive that in complex contexts with limited data, the tree-based reward model (RM) induces up to $\Theta(\log n/\log\log n)$ times less variance than chain-based RM where $n$ is the dataset size. As validation, we demonstrate that on three NLP tasks, the tree-based RM achieves 65% win rate on average against chain-based baselines. Looking ahead, we hope to extend the IBN analysis to help understand the phenomenon of goal misgeneralization.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.