 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Vision-language Models with Perception-centric Process Reward Models
Apr 27, 2026Recent advancements in reinforcement learning with verifiable rewards (RLVR) have significantly improved the complex reasoning ability of vision-language models (VLMs). However, its outcome-level supervision is too coarse to diagnose and correct errors within the reasoning chain. To this end, we propose Perceval, a process reward model (PRM) that enables token-level error grounding, which can extract image-related claims from the response and compare them one by one with the visual evidence in the image, ultimately returning claims that contain perceptual errors. Perceval is trained with perception-intensive supervised training data. We then integrate Perceval into the RL training process to train the policy models. Specifically, compared to traditional GRPO, which applies sequence-level advantages, we apply token-level advantages by targeting penalties on hallucinated spans identified by Perceval, thus enabling fine-grained supervision signals. In addition to augmenting the training process, Perceval can also assist VLMs during the inference stage. Using Perceval, we can truncate the erroneous portions of the model's response, and then either have the model regenerate the response directly or induce the model to reflect on its previous output. This process can be repeated multiple times to achieve test-time scaling. Experiments show significant improvements on benchmarks from various domains across multiple reasoning VLMs trained with RL, highlighting the promise of perception-centric supervision as a general-purpose strategy. For test-time scaling, it also demonstrates consistent performance gains over other strategies, such as major voting. Our code and data will be publicly released at https://github.com/RUCAIBox/Perceval.
VIPER: Process-aware Evaluation for Generative Video Reasoning
Dec 31, 2025Recent breakthroughs in video generation have demonstrated an emerging capability termed Chain-of-Frames (CoF) reasoning, where models resolve complex tasks through the generation of continuous frames. While these models show promise for Generative Video Reasoning (GVR), existing evaluation frameworks often rely on single-frame assessments, which can lead to outcome-hacking, where a model reaches a correct conclusion through an erroneous process. To address this, we propose a process-aware evaluation paradigm. We introduce VIPER, a comprehensive benchmark spanning 16 tasks across temporal, structural, symbolic, spatial, physics, and planning reasoning. Furthermore, we propose Process-outcome Consistency (POC@r), a new metric that utilizes VLM-as-Judge with a hierarchical rubric to evaluate both the validity of the intermediate steps and the final result. Our experiments reveal that state-of-the-art video models achieve only about 20% POC@1.0 and exhibit a significant outcome-hacking. We further explore the impact of test-time scaling and sampling robustness, highlighting a substantial gap between current video generation and true generalized visual reasoning. Our benchmark will be publicly released.
Sticker-TTS: Learn to Utilize Historical Experience with a Sticker-driven Test-Time Scaling Framework
Sep 05, 2025Large reasoning models (LRMs) have exhibited strong performance on complex reasoning tasks, with further gains achievable through increased computational budgets at inference. However, current test-time scaling methods predominantly rely on redundant sampling, ignoring the historical experience utilization, thereby limiting computational efficiency. To overcome this limitation, we propose Sticker-TTS, a novel test-time scaling framework that coordinates three collaborative LRMs to iteratively explore and refine solutions guided by historical attempts. At the core of our framework are distilled key conditions-termed stickers-which drive the extraction, refinement, and reuse of critical information across multiple rounds of reasoning. To further enhance the efficiency and performance of our framework, we introduce a two-stage optimization strategy that combines imitation learning with self-improvement, enabling progressive refinement. Extensive evaluations on three challenging mathematical reasoning benchmarks, including AIME-24, AIME-25, and OlymMATH, demonstrate that Sticker-TTS consistently surpasses strong baselines, including self-consistency and advanced reinforcement learning approaches, under comparable inference budgets. These results highlight the effectiveness of sticker-guided historical experience utilization. Our code and data are available at https://github.com/RUCAIBox/Sticker-TTS.
ICPC-Eval: Probing the Frontiers of LLM Reasoning with Competitive Programming Contests
Jun 05, 2025With the significant progress of large reasoning models in complex coding and reasoning tasks, existing benchmarks, like LiveCodeBench and CodeElo, are insufficient to evaluate the coding capabilities of large language models (LLMs) in real competition environments. Moreover, current evaluation metrics such as Pass@K fail to capture the reflective abilities of reasoning models. To address these challenges, we propose \textbf{ICPC-Eval}, a top-level competitive coding benchmark designed to probing the frontiers of LLM reasoning. ICPC-Eval includes 118 carefully curated problems from 11 recent ICPC contests held in various regions of the world, offering three key contributions: 1) A challenging realistic ICPC competition scenario, featuring a problem type and difficulty distribution consistent with actual contests. 2) A robust test case generation method and a corresponding local evaluation toolkit, enabling efficient and accurate local evaluation. 3) An effective test-time scaling evaluation metric, Refine@K, which allows iterative repair of solutions based on execution feedback. The results underscore the significant challenge in evaluating complex reasoning abilities: top-tier reasoning models like DeepSeek-R1 often rely on multi-turn code feedback to fully unlock their in-context reasoning potential when compared to non-reasoning counterparts. Furthermore, despite recent advancements in code generation, these models still lag behind top-performing human teams. We release the benchmark at: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs
Towards Effective Code-Integrated Reasoning
May 30, 2025In this paper, we investigate code-integrated reasoning, where models generate code when necessary and integrate feedback by executing it through a code interpreter. To acquire this capability, models must learn when and how to use external code tools effectively, which is supported by tool-augmented reinforcement learning (RL) through interactive learning. Despite its benefits, tool-augmented RL can still suffer from potential instability in the learning dynamics. In light of this challenge, we present a systematic approach to improving the training effectiveness and stability of tool-augmented RL for code-integrated reasoning. Specifically, we develop enhanced training strategies that balance exploration and stability, progressively building tool-use capabilities while improving reasoning performance. Through extensive experiments on five mainstream mathematical reasoning benchmarks, our model demonstrates significant performance improvements over multiple competitive baselines. Furthermore, we conduct an in-depth analysis of the mechanism and effect of code-integrated reasoning, revealing several key insights, such as the extension of model's capability boundaries and the simultaneous improvement of reasoning efficiency through code integration. All data and code for reproducing this work are available at: https://github.com/RUCAIBox/CIR.
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
May 22, 2025Large Language Models (LLMs) are powerful but prone to hallucinations due to static knowledge. Retrieval-Augmented Generation (RAG) helps by injecting external information, but current methods often are costly, generalize poorly, or ignore the internal knowledge of the model. In this paper, we introduce R1-Searcher++, a novel framework designed to train LLMs to adaptively leverage both internal and external knowledge sources. R1-Searcher++ employs a two-stage training strategy: an initial SFT Cold-start phase for preliminary format learning, followed by RL for Dynamic Knowledge Acquisition. The RL stage uses outcome-supervision to encourage exploration, incorporates a reward mechanism for internal knowledge utilization, and integrates a memorization mechanism to continuously assimilate retrieved information, thereby enriching the model's internal knowledge. By leveraging internal knowledge and external search engine, the model continuously improves its capabilities, enabling efficient retrieval-augmented reasoning. Our experiments demonstrate that R1-Searcher++ outperforms previous RAG and reasoning methods and achieves efficient retrieval. The code is available at https://github.com/RUCAIBox/R1-Searcher-plus.
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Mar 27, 2025



In recent years, the rapid development of large reasoning models has resulted in the saturation of existing benchmarks for evaluating mathematical reasoning, highlighting the urgent need for more challenging and rigorous evaluation frameworks. To address this gap, we introduce OlymMATH, a novel Olympiad-level mathematical benchmark, designed to rigorously test the complex reasoning capabilities of LLMs. OlymMATH features 200 meticulously curated problems, each manually verified and available in parallel English and Chinese versions. The problems are systematically organized into two distinct difficulty tiers: (1) AIME-level problems (easy) that establish a baseline for mathematical reasoning assessment, and (2) significantly more challenging problems (hard) designed to push the boundaries of current state-of-the-art models. In our benchmark, these problems span four core mathematical fields, each including a verifiable numerical solution to enable objective, rule-based evaluation. Empirical results underscore the significant challenge presented by OlymMATH, with state-of-the-art models including DeepSeek-R1 and OpenAI's o3-mini demonstrating notably limited accuracy on the hard subset. Furthermore, the benchmark facilitates comprehensive bilingual assessment of mathematical reasoning abilities-a critical dimension that remains largely unaddressed in mainstream mathematical reasoning benchmarks. We release the OlymMATH benchmark at the STILL project: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
Unlocking General Long Chain-of-Thought Reasoning Capabilities of Large Language Models via Representation Engineering
Mar 14, 2025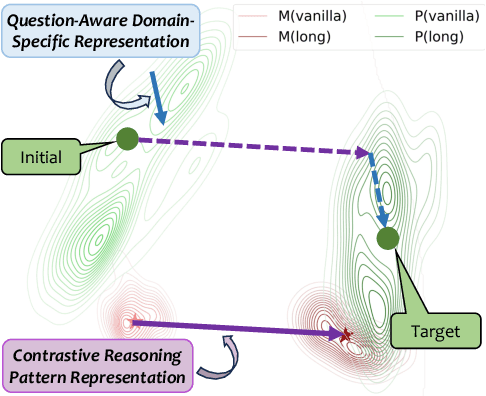



Recent advancements in long chain-of-thoughts(long CoTs) have significantly improved the reasoning capabilities of large language models(LLMs). Existing work finds that the capability of long CoT reasoning can be efficiently elicited by tuning on only a few examples and can easily transfer to other tasks. This motivates us to investigate whether long CoT reasoning is a general capability for LLMs. In this work, we conduct an empirical analysis for this question from the perspective of representation. We find that LLMs do encode long CoT reasoning as a general capability, with a clear distinction from vanilla CoTs. Furthermore, domain-specific representations are also required for the effective transfer of long CoT reasoning. Inspired by these findings, we propose GLoRE, a novel representation engineering method to unleash the general long CoT reasoning capabilities of LLMs. Extensive experiments demonstrate the effectiveness and efficiency of GLoRE in both in-domain and cross-domain scenarios.
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Mar 07, 2025



Existing Large Reasoning Models (LRMs) have shown the potential of reinforcement learning (RL) to enhance the complex reasoning capabilities of Large Language Models~(LLMs). While they achieve remarkable performance on challenging tasks such as mathematics and coding, they often rely on their internal knowledge to solve problems, which can be inadequate for time-sensitive or knowledge-intensive questions, leading to inaccuracies and hallucinations. To address this, we propose \textbf{R1-Searcher}, a novel two-stage outcome-based RL approach designed to enhance the search capabilities of LLMs. This method allows LLMs to autonomously invoke external search systems to access additional knowledge during the reasoning process. Our framework relies exclusively on RL, without requiring process rewards or distillation for a cold start. % effectively generalizing to out-of-domain datasets and supporting both Base and Instruct models. Our experiments demonstrate that our method significantly outperforms previous strong RAG methods, even when compared to the closed-source GPT-4o-mini.
An Empirical Study on Eliciting and Improving R1-like Reasoning Models
Mar 06, 2025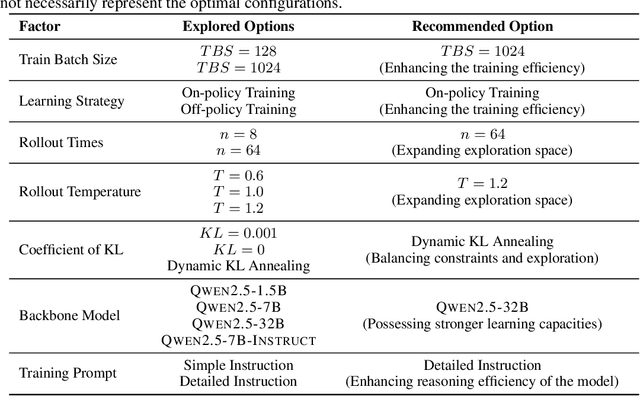
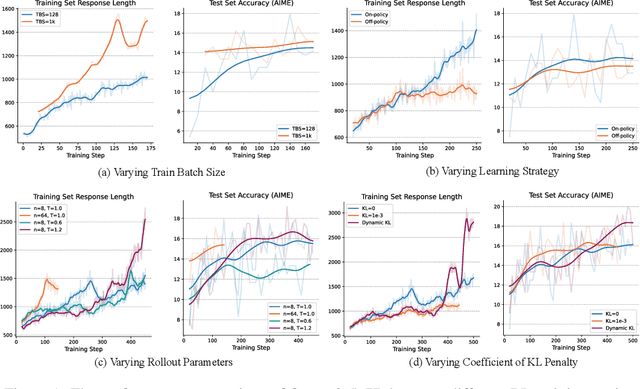
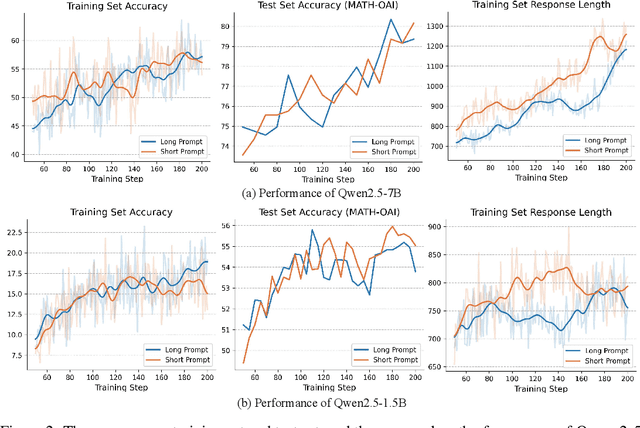

In this report, we present the third technical report on the development of slow-thinking models as part of the STILL project. As the technical pathway becomes clearer, scaling RL training has become a central technique for implementing such reasoning models. We systematically experiment with and document the effects of various factors influencing RL training, conducting experiments on both base models and fine-tuned models. Specifically, we demonstrate that our RL training approach consistently improves the Qwen2.5-32B base models, enhancing both response length and test accuracy. Furthermore, we show that even when a model like DeepSeek-R1-Distill-Qwen-1.5B has already achieved a high performance level, it can be further refined through RL training, reaching an accuracy of 39.33% on AIME 2024. Beyond RL training, we also explore the use of tool manipulation, finding that it significantly boosts the reasoning performance of large reasoning models. This approach achieves a remarkable accuracy of 86.67% with greedy search on AIME 2024, underscoring its effectiveness in enhancing model capabilities. We release our resources at the STILL project website: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.