 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective and Efficient Continual Pre-training of Large Language Models
Paper and Code
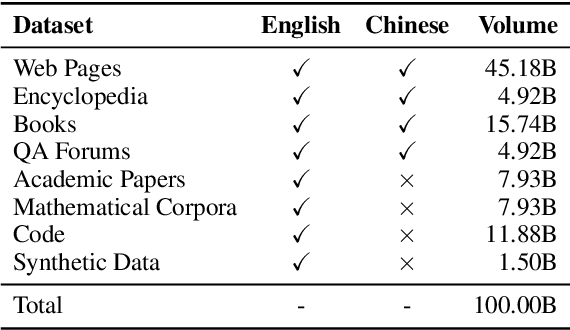
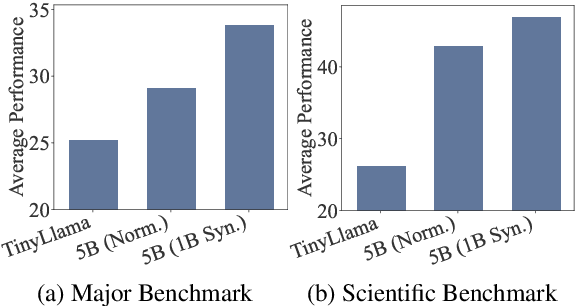

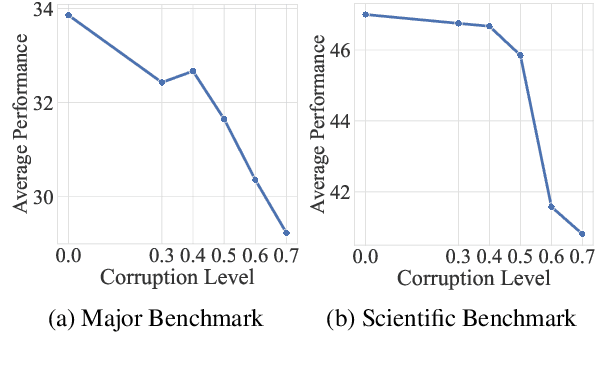
Continual pre-training (CPT) has been an important approach for adapting language models to specific domains or tasks. To make the CPT approach more traceable, this paper presents a technical report for continually pre-training Llama-3 (8B), which significantly enhances the Chinese language ability and scientific reasoning ability of the backbone model. To enhance the new abilities while retaining the original abilities, we design specific data mixture and curriculum strategies by utilizing existing datasets and synthesizing high-quality datasets. Specifically, we synthesize multidisciplinary scientific question and answer (QA) pairs based on related web pages, and subsequently incorporate these synthetic data to improve the scientific reasoning ability of Llama-3. We refer to the model after CPT as Llama-3-SynE (Synthetic data Enhanced Llama-3). We also present the tuning experiments with a relatively small model -- TinyLlama, and employ the derived findings to train the backbone model. Extensive experiments on a number of evaluation benchmarks show that our approach can largely improve the performance of the backbone models, including both the general abilities (+8.81 on C-Eval and +6.31 on CMMLU) and the scientific reasoning abilities (+12.00 on MATH and +4.13 on SciEval), without hurting the original capacities. Our model, data, and codes are available at https://github.com/RUC-GSAI/Llama-3-SynE.