 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Eliciting and Improving R1-like Reasoning Models
Mar 06, 2025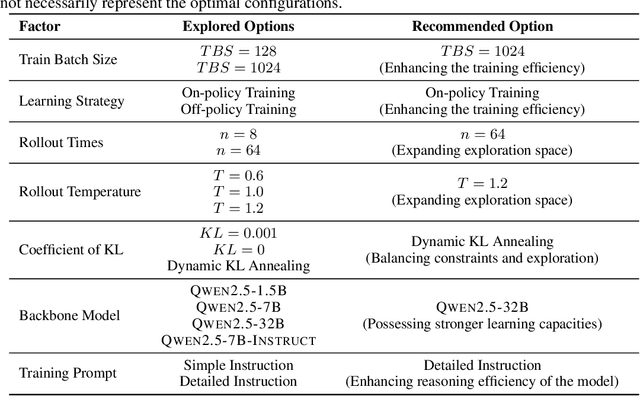
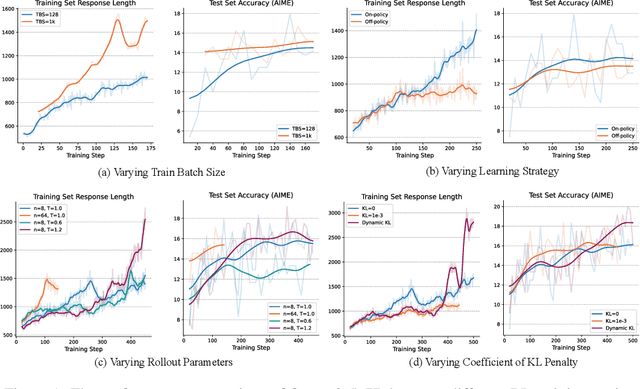
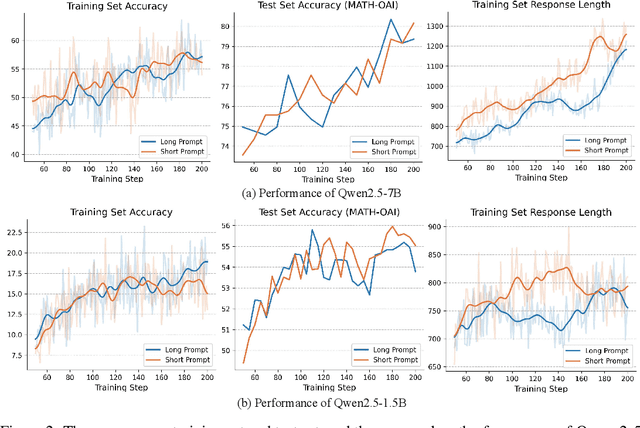

In this report, we present the third technical report on the development of slow-thinking models as part of the STILL project. As the technical pathway becomes clearer, scaling RL training has become a central technique for implementing such reasoning models. We systematically experiment with and document the effects of various factors influencing RL training, conducting experiments on both base models and fine-tuned models. Specifically, we demonstrate that our RL training approach consistently improves the Qwen2.5-32B base models, enhancing both response length and test accuracy. Furthermore, we show that even when a model like DeepSeek-R1-Distill-Qwen-1.5B has already achieved a high performance level, it can be further refined through RL training, reaching an accuracy of 39.33% on AIME 2024. Beyond RL training, we also explore the use of tool manipulation, finding that it significantly boosts the reasoning performance of large reasoning models. This approach achieves a remarkable accuracy of 86.67% with greedy search on AIME 2024, underscoring its effectiveness in enhancing model capabilities. We release our resources at the STILL project website: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
Large Margin Boltzmann Machines and Large Margin Sigmoid Belief Networks
Mar 25, 2010

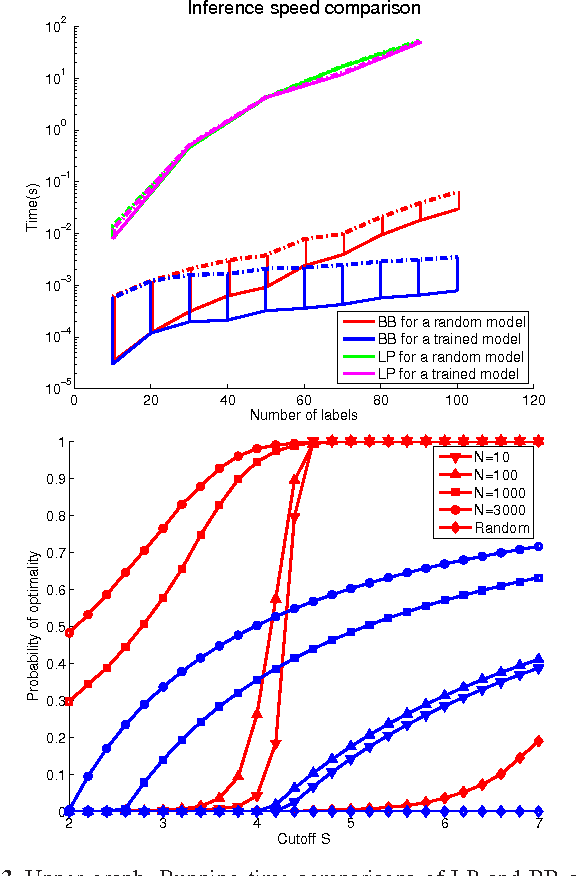

Current statistical models for structured prediction make simplifying assumptions about the underlying output graph structure, such as assuming a low-order Markov chain, because exact inference becomes intractable as the tree-width of the underlying graph increases. Approximate inference algorithms, on the other hand, force one to trade off representational power with computational efficiency. In this paper, we propose two new types of probabilistic graphical models, large margin Boltzmann machines (LMBMs) and large margin sigmoid belief networks (LMSBNs), for structured prediction. LMSBNs in particular allow a very fast inference algorithm for arbitrary graph structures that runs in polynomial time with a high probability. This probability is data-distribution dependent and is maximized in learning. The new approach overcomes the representation-efficiency trade-off in previous models and allows fast structured prediction with complicated graph structures. We present results from applying a fully connected model to multi-label scene classification and demonstrate that the proposed approach can yield significant performance gains over current state-of-the-art methods.