 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyondSWE: Can Current Code Agent Survive Beyond Single-Repo Bug Fixing?
Mar 03, 2026Current benchmarks for code agents primarily assess narrow, repository-specific fixes, overlooking critical real-world challenges such as cross-repository reasoning, domain-specialized problem solving, dependency-driven migration, and full-repository generation. To address this gap, we introduce BeyondSWE, a comprehensive benchmark that broadens existing evaluations along two axes - resolution scope and knowledge scope - using 500 real-world instances across four distinct settings. Experimental results reveal a significant capability gap: even frontier models plateau below 45% success, and no single model performs consistently across task types. To systematically investigate the role of external knowledge, we develop SearchSWE, a framework that integrates deep search with coding abilities. Our experiments show that search augmentation yields inconsistent gains and can in some cases degrade performance, highlighting the difficulty of emulating developer-like workflows that interleave search and reasoning during coding tasks. This work offers both a realistic, challenging evaluation benchmark and a flexible framework to advance research toward more capable code agents.
Generative Pseudo-Labeling for Pre-Ranking with LLMs
Feb 24, 2026Pre-ranking is a critical stage in industrial recommendation systems, tasked with efficiently scoring thousands of recalled items for downstream ranking. A key challenge is the train-serving discrepancy: pre-ranking models are trained only on exposed interactions, yet must score all recalled candidates -- including unexposed items -- during online serving. This mismatch not only induces severe sample selection bias but also degrades generalization, especially for long-tail content. Existing debiasing approaches typically rely on heuristics (e.g., negative sampling) or distillation from biased rankers, which either mislabel plausible unexposed items as negatives or propagate exposure bias into pseudo-labels. In this work, we propose Generative Pseudo-Labeling (GPL), a framework that leverages large language models (LLMs) to generate unbiased, content-aware pseudo-labels for unexposed items, explicitly aligning the training distribution with the online serving space. By offline generating user-specific interest anchors and matching them with candidates in a frozen semantic space, GPL provides high-quality supervision without adding online latency. Deployed in a large-scale production system, GPL improves click-through rate by 3.07%, while significantly enhancing recommendation diversity and long-tail item discovery.
HiSAC: Hierarchical Sparse Activation Compression for Ultra-long Sequence Modeling in Recommenders
Feb 24, 2026Modern recommender systems leverage ultra-long user behavior sequences to capture dynamic preferences, but end-to-end modeling is infeasible in production due to latency and memory constraints. While summarizing history via interest centers offers a practical alternative, existing methods struggle to (1) identify user-specific centers at appropriate granularity and (2) accurately assign behaviors, leading to quantization errors and loss of long-tail preferences. To alleviate these issues, we propose Hierarchical Sparse Activation Compression (HiSAC), an efficient framework for personalized sequence modeling. HiSAC encodes interactions into multi-level semantic IDs and constructs a global hierarchical codebook. A hierarchical voting mechanism sparsely activates personalized interest-agents as fine-grained preference centers. Guided by these agents, Soft-Routing Attention aggregates historical signals in semantic space, weighting by similarity to minimize quantization error and retain long-tail behaviors. Deployed on Taobao's "Guess What You Like" homepage, HiSAC achieves significant compression and cost reduction, with online A/B tests showing a consistent 1.65% CTR uplift -- demonstrating its scalability and real-world effectiveness.
SWE-Master: Unleashing the Potential of Software Engineering Agents via Post-Training
Feb 03, 2026In this technical report, we present SWE-Master, an open-source and fully reproducible post-training framework for building effective software engineering agents. SWE-Master systematically explores the complete agent development pipeline, including teacher-trajectory synthesis and data curation, long-horizon SFT, RL with real execution feedback, and inference framework design. Starting from an open-source base model with limited initial SWE capability, SWE-Master demonstrates how systematical optimization method can elicit strong long-horizon SWE task solving abilities. We evaluate SWE-Master on SWE-bench Verified, a standard benchmark for realistic software engineering tasks. Under identical experimental settings, our approach achieves a resolve rate of 61.4\% with Qwen2.5-Coder-32B, substantially outperforming existing open-source baselines. By further incorporating test-time scaling~(TTS) with LLM-based environment feedback, SWE-Master reaches 70.8\% at TTS@8, demonstrating a strong performance potential. SWE-Master provides a practical and transparent foundation for advancing reproducible research on software engineering agents. The code is available at https://github.com/RUCAIBox/SWE-Master.
LLM-in-Sandbox Elicits General Agentic Intelligence
Jan 22, 2026We introduce LLM-in-Sandbox, enabling LLMs to explore within a code sandbox (i.e., a virtual computer), to elicit general intelligence in non-code domains. We first demonstrate that strong LLMs, without additional training, exhibit generalization capabilities to leverage the code sandbox for non-code tasks. For example, LLMs spontaneously access external resources to acquire new knowledge, leverage the file system to handle long contexts, and execute scripts to satisfy formatting requirements. We further show that these agentic capabilities can be enhanced through LLM-in-Sandbox Reinforcement Learning (LLM-in-Sandbox-RL), which uses only non-agentic data to train models for sandbox exploration. Experiments demonstrate that LLM-in-Sandbox, in both training-free and post-trained settings, achieves robust generalization spanning mathematics, physics, chemistry, biomedicine, long-context understanding, and instruction following. Finally, we analyze LLM-in-Sandbox's efficiency from computational and system perspectives, and open-source it as a Python package to facilitate real-world deployment.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
From Trial-and-Error to Improvement: A Systematic Analysis of LLM Exploration Mechanisms in RLVR
Aug 11, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). Unlike traditional RL approaches, RLVR leverages rule-based feedback to guide LLMs in generating and refining complex reasoning chains -- a process critically dependent on effective exploration strategies. While prior work has demonstrated RLVR's empirical success, the fundamental mechanisms governing LLMs' exploration behaviors remain underexplored. This technical report presents a systematic investigation of exploration capacities in RLVR, covering four main aspects: (1) exploration space shaping, where we develop quantitative metrics to characterize LLMs' capability boundaries; (2) entropy-performance exchange, analyzed across training stages, individual instances, and token-level patterns; and (3) RL performance optimization, examining methods to effectively translate exploration gains into measurable improvements. By unifying previously identified insights with new empirical evidence, this work aims to provide a foundational framework for advancing RLVR systems.
Reasoning with Exploration: An Entropy Perspective
Jun 17, 2025Balancing exploration and exploitation is a central goal in reinforcement learning (RL). Despite recent advances in enhancing language model (LM) reasoning, most methods lean toward exploitation, and increasingly encounter performance plateaus. In this work, we revisit entropy -- a signal of exploration in RL -- and examine its relationship to exploratory reasoning in LMs. Through empirical analysis, we uncover strong positive correlations between high-entropy regions and three types of exploratory reasoning actions: (1) pivotal tokens that determine or connect logical steps, (2) reflective actions such as self-verification and correction, and (3) rare behaviors under-explored by the base LMs. Motivated by this, we introduce a minimal modification to standard RL with only one line of code: augmenting the advantage function with an entropy-based term. Unlike traditional maximum-entropy methods which encourage exploration by promoting uncertainty, we encourage exploration by promoting longer and deeper reasoning chains. Notably, our method achieves significant gains on the Pass@K metric -- an upper-bound estimator of LM reasoning capabilities -- even when evaluated with extremely large K values, pushing the boundaries of LM reasoning.
An Empirical Study on Eliciting and Improving R1-like Reasoning Models
Mar 06, 2025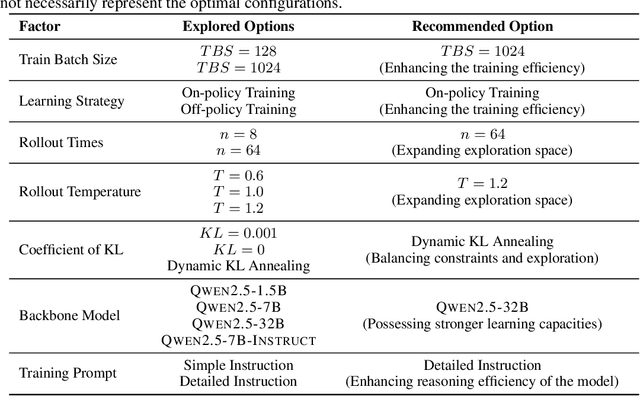
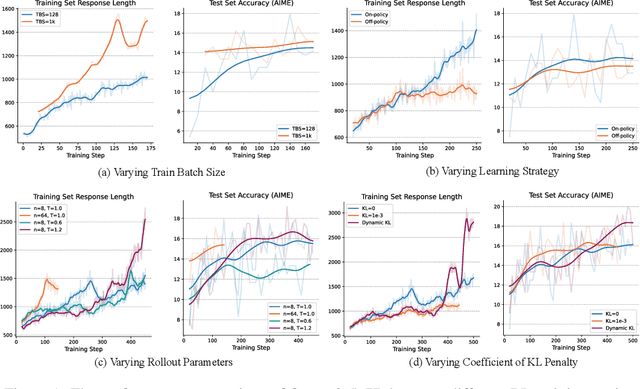
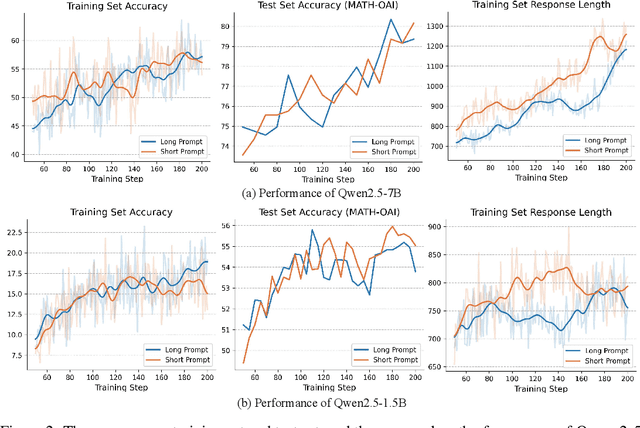

In this report, we present the third technical report on the development of slow-thinking models as part of the STILL project. As the technical pathway becomes clearer, scaling RL training has become a central technique for implementing such reasoning models. We systematically experiment with and document the effects of various factors influencing RL training, conducting experiments on both base models and fine-tuned models. Specifically, we demonstrate that our RL training approach consistently improves the Qwen2.5-32B base models, enhancing both response length and test accuracy. Furthermore, we show that even when a model like DeepSeek-R1-Distill-Qwen-1.5B has already achieved a high performance level, it can be further refined through RL training, reaching an accuracy of 39.33% on AIME 2024. Beyond RL training, we also explore the use of tool manipulation, finding that it significantly boosts the reasoning performance of large reasoning models. This approach achieves a remarkable accuracy of 86.67% with greedy search on AIME 2024, underscoring its effectiveness in enhancing model capabilities. We release our resources at the STILL project website: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
How to Synthesize Text Data without Model Collapse?
Dec 19, 2024

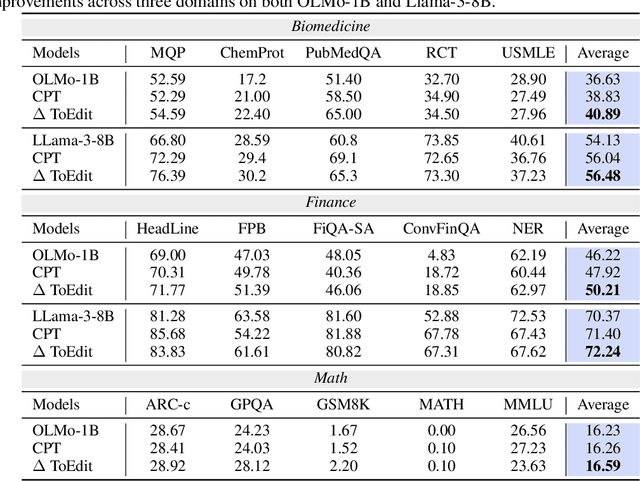
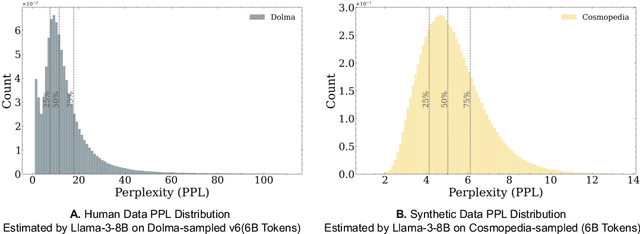
Model collapse in synthetic data indicates that iterative training on self-generated data leads to a gradual decline in performance. With the proliferation of AI models, synthetic data will fundamentally reshape the web data ecosystem. Future GPT-$\{n\}$ models will inevitably be trained on a blend of synthetic and human-produced data. In this paper, we focus on two questions: what is the impact of synthetic data on language model training, and how to synthesize data without model collapse? We first pre-train language models across different proportions of synthetic data, revealing a negative correlation between the proportion of synthetic data and model performance. We further conduct statistical analysis on synthetic data to uncover distributional shift phenomenon and over-concentration of n-gram features. Inspired by the above findings, we propose token editing on human-produced data to obtain semi-synthetic data. As a proof of concept, we theoretically demonstrate that token-level editing can prevent model collapse, as the test error is constrained by a finite upper bound. We conduct extensive experiments on pre-training from scratch, continual pre-training, and supervised fine-tuning. The results validate our theoretical proof that token-level editing improves data quality and enhances model performance.