 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotDirector: Robot Storytelling Across the Symmetrical Reality with Multi-modal Interactions
Jun 02, 2026Robot storytelling offers a unique blend of technological innovation and creative expression that engages children in unprecedented ways. However, the technical aspects are often too complicated for children. We propose an interactive system that facilitates robot storytelling with tangible and natural language interactions. Children arrange the playground with their own stuff and create narratives with an LLM agent. The created narratives are transformed into a motion sequence based on the map and characters, and the motions are executed by self-navigating swarm robots. This system enhances robot storytelling with flexible scenarios, enabling young children to create robot dramas with everyday objects.
TeachAnything: A Multimodal Crowdsourcing Platform for Training Embodied AI Agents in Symmetrical Reality
May 14, 2026Symmetrical Reality (SR) is emerging as a future trend for human-agent coexistence, placing higher demands on agents to acquire human-like intelligence. It calls for richer and more diverse human guidance. We introduce a three-stage demonstration paradigm integrating multimodal demonstration signals. Building on this paradigm, we developed TeachAnything, a cloud-based, crowdsourcing-oriented demonstration platform with physics simulation capable of collecting diverse demonstration data across varied scenes, tasks, and embodiments. By unifying virtual and physical interactions through both methodological design and physics simulation, the system serves as a practical foundation for developing embodied agents aligned with Symmetrical Reality.
SCOUT: Active Information Foraging for Long-Text Understanding with Decoupled Epistemic States
May 06, 2026Long-Text Understanding (LTU) at million-token scale requires balancing reasoning fidelity with computational efficiency. Frontier long-context LLMs can process millions of token contexts end-to-end, but they suffer from high token consumption and attention dilution. In parallel, specialized LTU agents often sacrifice fidelity through task-agnostic abstractions like graph construction or indexing. We identify a key insight for LTU: query-relevant information is typically sparse relative to the full document, so effective reasoning should rely on a query-sufficient subset rather than the entire context. To address this, we propose SCOUT, a new paradigm for LTU that shifts from passive processing to active information foraging. It treats the document as an explorable environment and answers from a compact, provenance-grounded epistemic state. Guided by state-level gap diagnosis, SCOUT adaptively alternates between coarse-to-fine exploration and anchored state updates that progressively contract its epistemic state toward query sufficiency. Experiments show that SCOUT matches state-of-the-art proprietary models while reducing token consumption by up to 8x. Moreover, SCOUT remains stable as context length scales, substantially alleviating the practical cost-performance trade-off.
Learning What Matters Now: Dynamic Preference Inference under Contextual Shifts
Mar 24, 2026Humans often juggle multiple, sometimes conflicting objectives and shift their priorities as circumstances change, rather than following a fixed objective function. In contrast, most computational decision-making and multi-objective RL methods assume static preference weights or a known scalar reward. In this work, we study sequential decision-making problem when these preference weights are unobserved latent variables that drift with context. Specifically, we propose Dynamic Preference Inference (DPI), a cognitively inspired framework in which an agent maintains a probabilistic belief over preference weights, updates this belief from recent interaction, and conditions its policy on inferred preferences. We instantiate DPI as a variational preference inference module trained jointly with a preference-conditioned actor-critic, using vector-valued returns as evidence about latent trade-offs. In queueing, maze, and multi-objective continuous-control environments with event-driven changes in objectives, DPI adapts its inferred preferences to new regimes and achieves higher post-shift performance than fixed-weight and heuristic envelope baselines.
Exploring Human-Machine Coexistence in Symmetrical Reality
Feb 25, 2026In the context of the evolution of artificial intelligence (AI), the interaction between humans and AI entities has become increasingly salient, challenging the conventional human-centric paradigms of human-machine interaction. To address this challenge, it is imperative to reassess the relationship between AI entities and humans. Through considering both the virtual and physical worlds, we can construct a novel descriptive framework for a world where humans and machines coexist symbiotically. This paper will introduce a fresh research direction engendered for studying harmonious human-machine coexistence across physical and virtual worlds, which has been termed "symmetrical reality". We will elucidate its key characteristics, offering innovative research insight for renovating human-machine interaction paradigms.
Automatic Cognitive Task Generation for In-Situ Evaluation of Embodied Agents
Feb 05, 2026As general intelligent agents are poised for widespread deployment in diverse households, evaluation tailored to each unique unseen 3D environment has become a critical prerequisite. However, existing benchmarks suffer from severe data contamination and a lack of scene specificity, inadequate for assessing agent capabilities in unseen settings. To address this, we propose a dynamic in-situ task generation method for unseen environments inspired by human cognition. We define tasks through a structured graph representation and construct a two-stage interaction-evolution task generation system for embodied agents (TEA). In the interaction stage, the agent actively interacts with the environment, creating a loop between task execution and generation that allows for continuous task generation. In the evolution stage, task graph modeling allows us to recombine and reuse existing tasks to generate new ones without external data. Experiments across 10 unseen scenes demonstrate that TEA automatically generated 87,876 tasks in two cycles, which human verification confirmed to be physically reasonable and encompassing essential daily cognitive capabilities. Benchmarking SOTA models against humans on our in-situ tasks reveals that models, despite excelling on public benchmarks, perform surprisingly poorly on basic perception tasks, severely lack 3D interaction awareness and show high sensitivity to task types in reasoning. These sobering findings highlight the necessity of in-situ evaluation before deploying agents into real-world human environments.
S$^3$IT: A Benchmark for Spatially Situated Social Intelligence Test
Dec 23, 2025
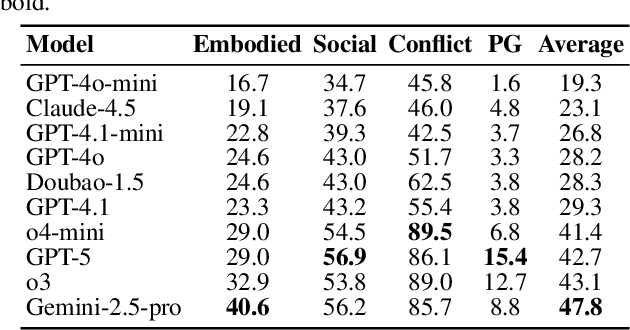
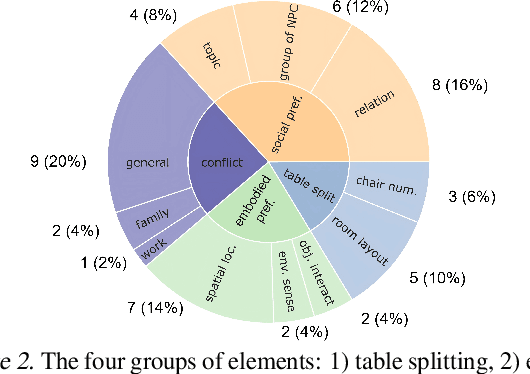

The integration of embodied agents into human environments demands embodied social intelligence: reasoning over both social norms and physical constraints. However, existing evaluations fail to address this integration, as they are limited to either disembodied social reasoning (e.g., in text) or socially-agnostic physical tasks. Both approaches fail to assess an agent's ability to integrate and trade off both physical and social constraints within a realistic, embodied context. To address this challenge, we introduce Spatially Situated Social Intelligence Test (S$^{3}$IT), a benchmark specifically designed to evaluate embodied social intelligence. It is centered on a novel and challenging seat-ordering task, requiring an agent to arrange seating in a 3D environment for a group of large language model-driven (LLM-driven) NPCs with diverse identities, preferences, and intricate interpersonal relationships. Our procedurally extensible framework generates a vast and diverse scenario space with controllable difficulty, compelling the agent to acquire preferences through active dialogue, perceive the environment via autonomous exploration, and perform multi-objective optimization within a complex constraint network. We evaluate state-of-the-art LLMs on S$^{3}$IT and found that they still struggle with this problem, showing an obvious gap compared with the human baseline. Results imply that LLMs have deficiencies in spatial intelligence, yet simultaneously demonstrate their ability to achieve near human-level competence in resolving conflicts that possess explicit textual cues.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
SCOPE: Intrinsic Semantic Space Control for Mitigating Copyright Infringement in LLMs
Nov 11, 2025Large language models sometimes inadvertently reproduce passages that are copyrighted, exposing downstream applications to legal risk. Most existing studies for inference-time defences focus on surface-level token matching and rely on external blocklists or filters, which add deployment complexity and may overlook semantically paraphrased leakage. In this work, we reframe copyright infringement mitigation as intrinsic semantic-space control and introduce SCOPE, an inference-time method that requires no parameter updates or auxiliary filters. Specifically, the sparse autoencoder (SAE) projects hidden states into a high-dimensional, near-monosemantic space; benefiting from this representation, we identify a copyright-sensitive subspace and clamp its activations during decoding. Experiments on widely recognized benchmarks show that SCOPE mitigates copyright infringement without degrading general utility. Further interpretability analyses confirm that the isolated subspace captures high-level semantics.
JointCQ: Improving Factual Hallucination Detection with Joint Claim and Query Generation
Oct 22, 2025Current large language models (LLMs) often suffer from hallucination issues, i,e, generating content that appears factual but is actually unreliable. A typical hallucination detection pipeline involves response decomposition (i.e., claim extraction), query generation, evidence collection (i.e., search or retrieval), and claim verification. However, existing methods exhibit limitations in the first two stages, such as context loss during claim extraction and low specificity in query generation, resulting in degraded performance across the hallucination detection pipeline. In this work, we introduce JointCQ https://github.com/pku0xff/JointCQ, a joint claim-and-query generation framework designed to construct an effective and efficient claim-query generator. Our framework leverages elaborately designed evaluation criteria to filter synthesized training data, and finetunes a language model for joint claim extraction and query generation, providing reliable and informative inputs for downstream search and verification. Experimental results demonstrate that our method outperforms previous methods on multiple open-domain QA hallucination detection benchmarks, advancing the goal of more trustworthy and transparent language model systems.