 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
A Novel Wasserstein Quaternion Generative Adversarial Network for Color Image Generation
Dec 09, 2025Color image generation has a wide range of applications, but the existing generation models ignore the correlation among color channels, which may lead to chromatic aberration problems. In addition, the data distribution problem of color images has not been systematically elaborated and explained, so that there is still the lack of the theory about measuring different color images datasets. In this paper, we define a new quaternion Wasserstein distance and develop its dual theory. To deal with the quaternion linear programming problem, we derive the strong duality form with helps of quaternion convex set separation theorem and quaternion Farkas lemma. With using quaternion Wasserstein distance, we propose a novel Wasserstein quaternion generative adversarial network. Experiments demonstrate that this novel model surpasses both the (quaternion) generative adversarial networks and the Wasserstein generative adversarial network in terms of generation efficiency and image quality.
Body Discovery of Embodied AI
Mar 25, 2025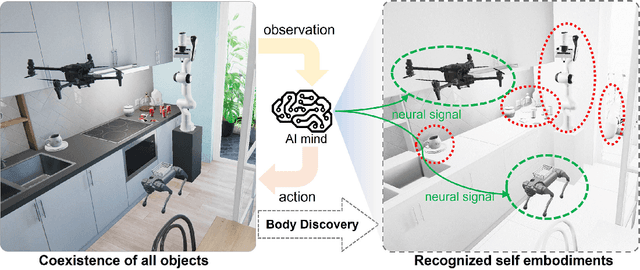

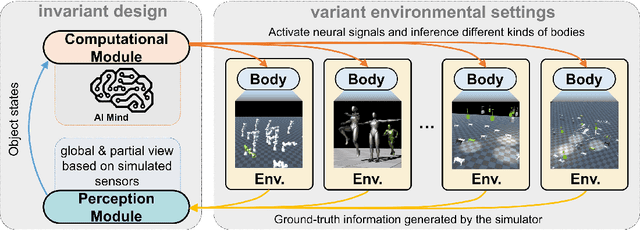
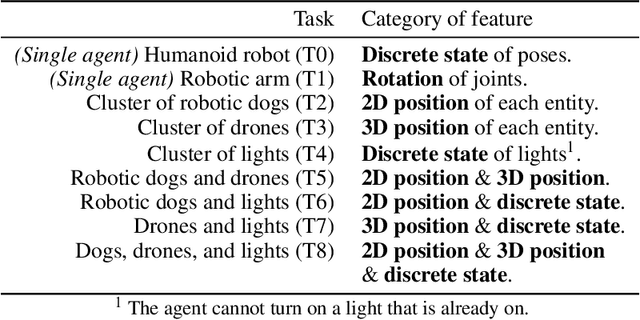
In the pursuit of realizing artificial general intelligence (AGI), the importance of embodied artificial intelligence (AI) becomes increasingly apparent. Following this trend, research integrating robots with AGI has become prominent. As various kinds of embodiments have been designed, adaptability to diverse embodiments will become important to AGI. We introduce a new challenge, termed "Body Discovery of Embodied AI", focusing on tasks of recognizing embodiments and summarizing neural signal functionality. The challenge encompasses the precise definition of an AI body and the intricate task of identifying embodiments in dynamic environments, where conventional approaches often prove inadequate. To address these challenges, we apply causal inference method and evaluate it by developing a simulator tailored for testing algorithms with virtual environments. Finally, we validate the efficacy of our algorithms through empirical testing, demonstrating their robust performance in various scenarios based on virtual environments.
EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
Oct 16, 2024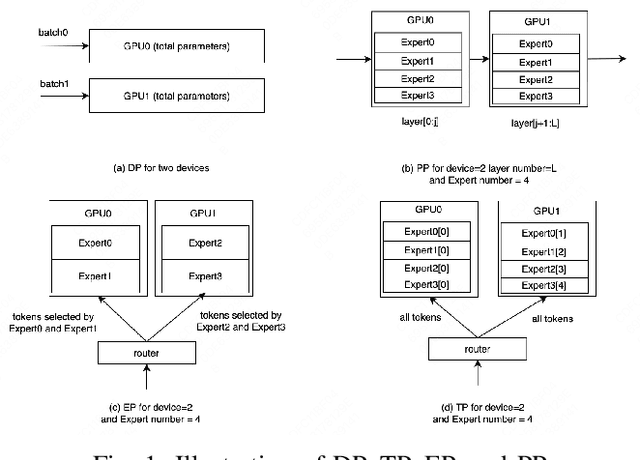
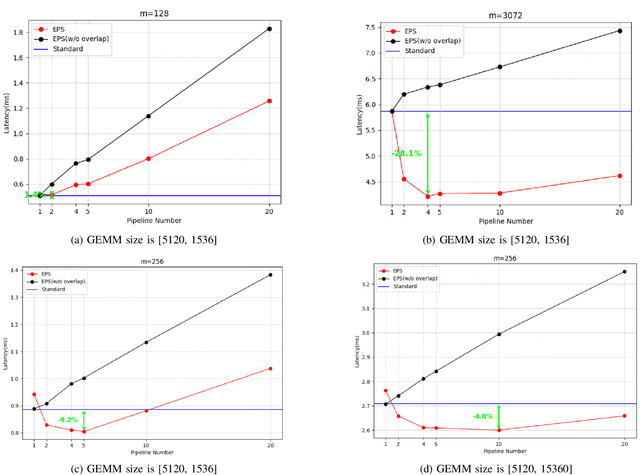
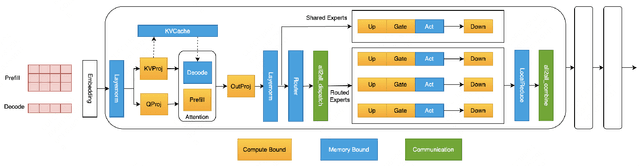
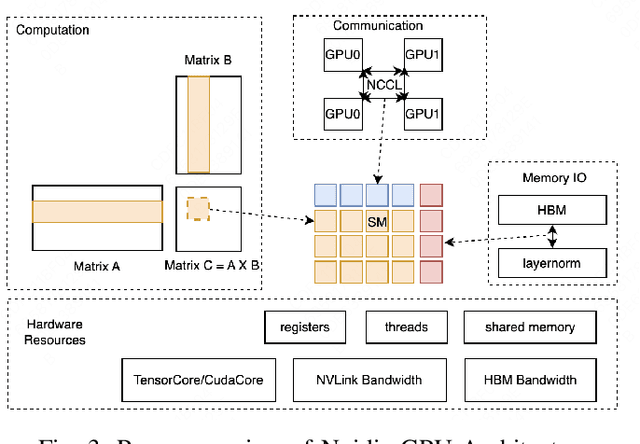
Large Language Model (LLM) has revolutionized the field of artificial intelligence, with their capabilities expanding rapidly due to advances in deep learning and increased computational resources. The mixture-of-experts (MoE) model has emerged as a prominent architecture in the field of LLM, better balancing the model performance and computational efficiency. MoE architecture allows for effective scaling and efficient parallel processing, but the GEMM (General Matrix Multiply) of MoE and the large parameters introduce challenges in terms of computation efficiency and communication overhead, which becomes the throughput bottleneck during inference. Applying a single parallelism strategy like EP, DP, PP, etc. to MoE architecture usually achieves sub-optimal inference throughput, the straightforward combinations of existing different parallelisms on MoE can not obtain optimal inference throughput yet. This paper introduces EPS-MoE, a novel expert pipeline scheduler for MoE that goes beyond the existing inference parallelism schemes. Our approach focuses on optimizing the computation of MoE FFN (FeedForward Network) modules by dynamically selecting the best kernel implementation of GroupGemm and DenseGemm for different loads and adaptively overlapping these computations with \textit{all2all} communication, leading to a substantial increase in throughput. Our experimental results demonstrate an average 21% improvement in prefill throughput over existing parallel inference methods. Specifically, we validated our method on DeepSeekV2, a highly optimized model claimed to achieve a prefill throughput of 100K tokens per second. By applying EPS-MoE, we further accelerated it to at least 120K tokens per second.
Multi-fidelity prediction of fluid flow and temperature field based on transfer learning using Fourier Neural Operator
Apr 14, 2023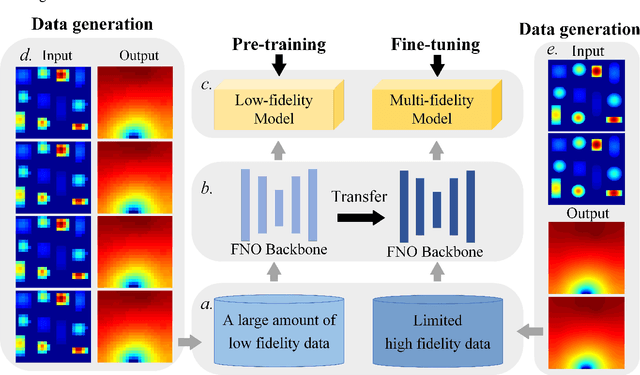
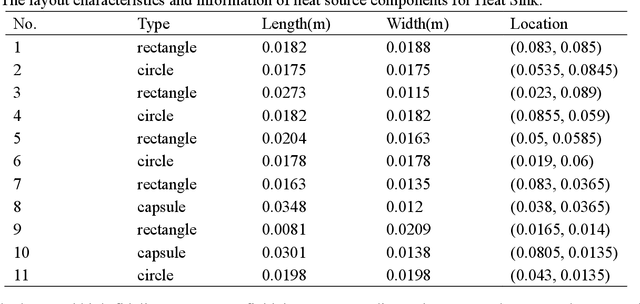
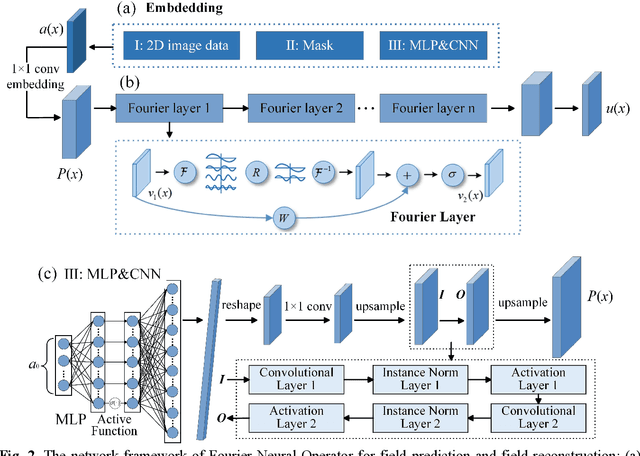
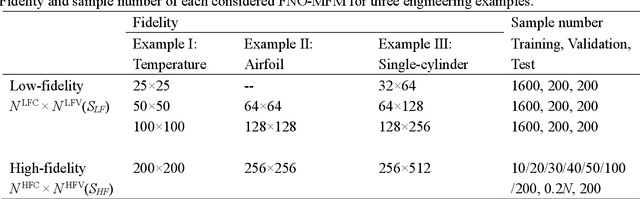
Data-driven prediction of fluid flow and temperature distribution in marine and aerospace engineering has received extensive research and demonstrated its potential in real-time prediction recently. However, usually large amounts of high-fidelity data are required to describe and accurately predict the complex physical information, while in reality, only limited high-fidelity data is available due to the high experiment/computational cost. Therefore, this work proposes a novel multi-fidelity learning method based on the Fourier Neural Operator by jointing abundant low-fidelity data and limited high-fidelity data under transfer learning paradigm. First, as a resolution-invariant operator, the Fourier Neural Operator is first and gainfully applied to integrate multi-fidelity data directly, which can utilize the scarce high-fidelity data and abundant low-fidelity data simultaneously. Then, the transfer learning framework is developed for the current task by extracting the rich low-fidelity data knowledge to assist high-fidelity modeling training, to further improve data-driven prediction accuracy. Finally, three typical fluid and temperature prediction problems are chosen to validate the accuracy of the proposed multi-fidelity model. The results demonstrate that our proposed method has high effectiveness when compared with other high-fidelity models, and has the high modeling accuracy of 99% for all the selected physical field problems. Significantly, the proposed multi-fidelity learning method has the potential of a simple structure with high precision, which can provide a reference for the construction of the subsequent model.
SportsMOT: A Large Multi-Object Tracking Dataset in Multiple Sports Scenes
Apr 13, 2023Multi-object tracking in sports scenes plays a critical role in gathering players statistics, supporting further analysis, such as automatic tactical analysis. Yet existing MOT benchmarks cast little attention on the domain, limiting its development. In this work, we present a new large-scale multi-object tracking dataset in diverse sports scenes, coined as \emph{SportsMOT}, where all players on the court are supposed to be tracked. It consists of 240 video sequences, over 150K frames (almost 15\times MOT17) and over 1.6M bounding boxes (3\times MOT17) collected from 3 sports categories, including basketball, volleyball and football. Our dataset is characterized with two key properties: 1) fast and variable-speed motion and 2) similar yet distinguishable appearance. We expect SportsMOT to encourage the MOT trackers to promote in both motion-based association and appearance-based association. We benchmark several state-of-the-art trackers and reveal the key challenge of SportsMOT lies in object association. To alleviate the issue, we further propose a new multi-object tracking framework, termed as \emph{MixSort}, introducing a MixFormer-like structure as an auxiliary association model to prevailing tracking-by-detection trackers. By integrating the customized appearance-based association with the original motion-based association, MixSort achieves state-of-the-art performance on SportsMOT and MOT17. Based on MixSort, we give an in-depth analysis and provide some profound insights into SportsMOT. The dataset and code will be available at https://deeperaction.github.io/datasets/sportsmot.html.
Uncertainty Guided Ensemble Self-Training for Semi-Supervised Global Field Reconstruction
Feb 23, 2023



Recovering a globally accurate complex physics field from limited sensor is critical to the measurement and control in the aerospace engineering. General reconstruction methods for recovering the field, especially the deep learning with more parameters and better representational ability, usually require large amounts of labeled data which is unaffordable. To solve the problem, this paper proposes Uncertainty Guided Ensemble Self-Training (UGE-ST), using plentiful unlabeled data to improve reconstruction performance. A novel self-training framework with the ensemble teacher and pretraining student designed to improve the accuracy of the pseudo-label and remedy the impact of noise is first proposed. On the other hand, uncertainty-guided learning is proposed to encourage the model to focus on the highly confident regions of pseudo-labels and mitigate the effects of wrong pseudo-labeling in self-training, improving the performance of the reconstruction model. Experiments include the pressure velocity field reconstruction of airfoil and the temperature field reconstruction of aircraft system indicate that our UGE-ST can save up to 90% of the data with the same accuracy as supervised learning.
RecFNO: a resolution-invariant flow and heat field reconstruction method from sparse observations via Fourier neural operator
Feb 20, 2023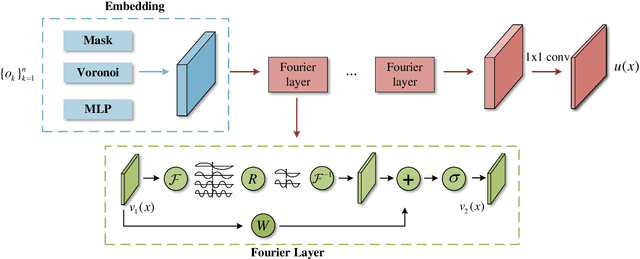
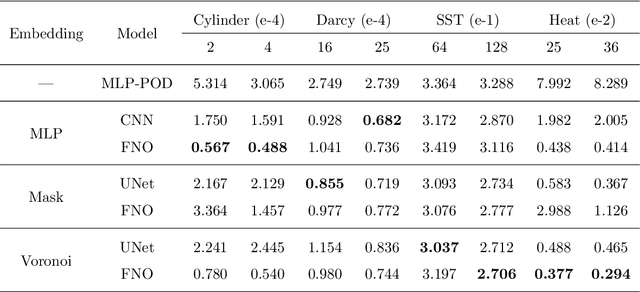

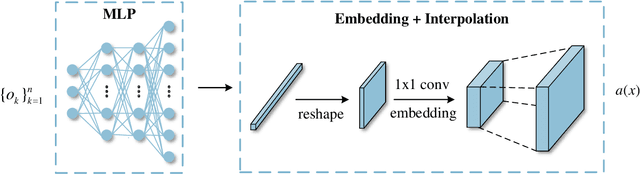
Perception of the full state is an essential technology to support the monitoring, analysis, and design of physical systems, one of whose challenges is to recover global field from sparse observations. Well-known for brilliant approximation ability, deep neural networks have been attractive to data-driven flow and heat field reconstruction studies. However, limited by network structure, existing researches mostly learn the reconstruction mapping in finite-dimensional space and has poor transferability to variable resolution of outputs. In this paper, we extend the new paradigm of neural operator and propose an end-to-end physical field reconstruction method with both excellent performance and mesh transferability named RecFNO. The proposed method aims to learn the mapping from sparse observations to flow and heat field in infinite-dimensional space, contributing to a more powerful nonlinear fitting capacity and resolution-invariant characteristic. Firstly, according to different usage scenarios, we develop three types of embeddings to model the sparse observation inputs: MLP, mask, and Voronoi embedding. The MLP embedding is propitious to more sparse input, while the others benefit from spatial information preservation and perform better with the increase of observation data. Then, we adopt stacked Fourier layers to reconstruct physical field in Fourier space that regularizes the overall recovered field by Fourier modes superposition. Benefiting from the operator in infinite-dimensional space, the proposed method obtains remarkable accuracy and better resolution transferability among meshes. The experiments conducted on fluid mechanics and thermology problems show that the proposed method outperforms existing POD-based and CNN-based methods in most cases and has the capacity to achieve zero-shot super-resolution.
FR-LIO: Fast and Robust Lidar-Inertial Odometry by Tightly-Coupled Iterated Kalman Smoother and Robocentric Voxels
Feb 08, 2023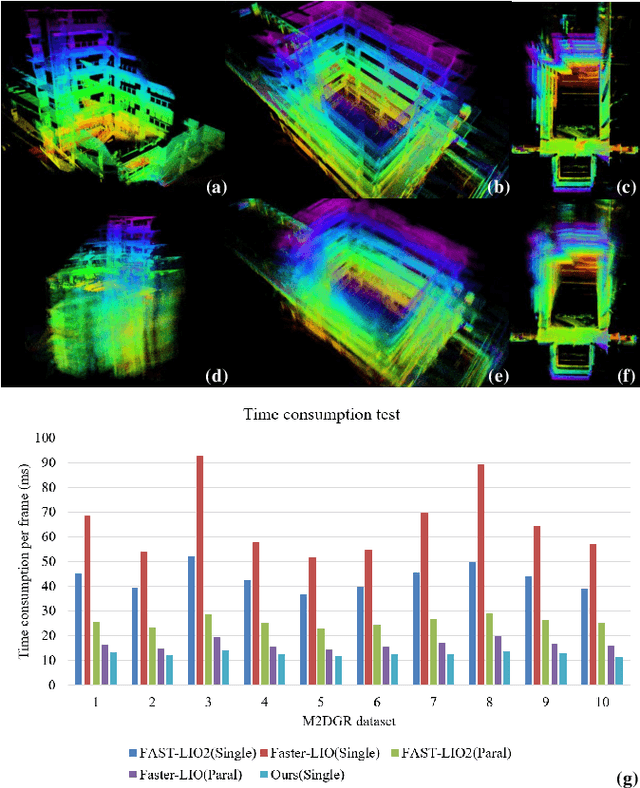
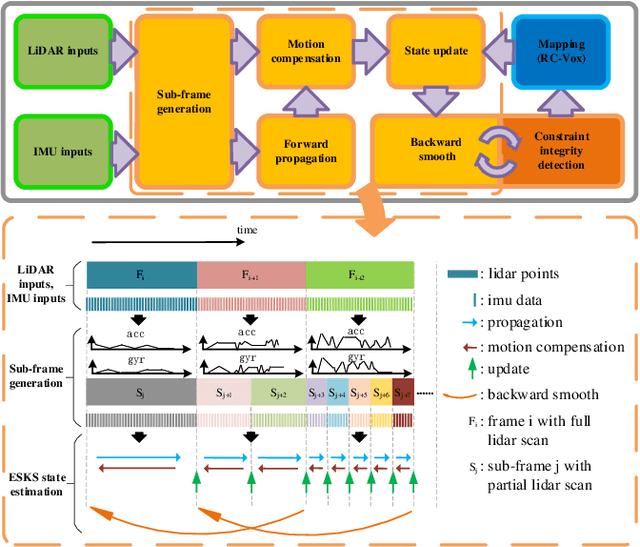
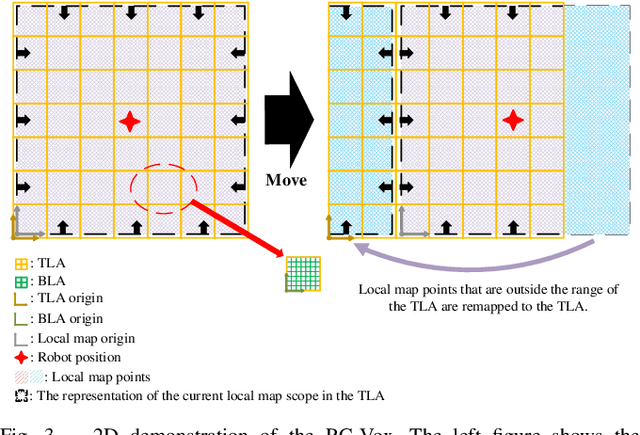
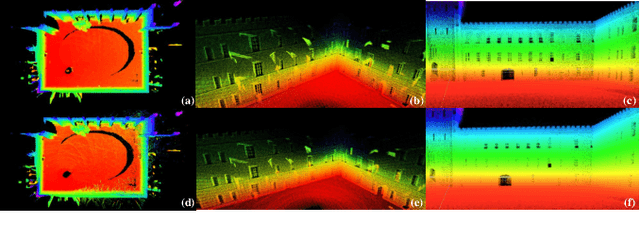
This paper presents a fast lidar-inertial odometry (LIO) system that is robust to aggressive motion. To achieve robust tracking in aggressive motion scenes, we exploit the continuous scanning property of lidar to adaptively divide the full scan into multiple partial scans (named sub-frames) according to the motion intensity. And to avoid the degradation of sub-frames resulting from insufficient constraints, we propose a robust state estimation method based on a tightly-coupled iterated error state Kalman smoother (ESKS) framework. Furthermore, we propose a robocentric voxel map (RC-Vox) to improve the system's efficiency. The RC-Vox allows efficient maintenance of map points and k nearest neighbor (k-NN) queries by mapping local map points into a fixed-size, two-layer 3D array structure. Extensive experiments were conducted on 27 sequences from 4 public datasets and our own dataset. The results show that our system can achieve stable tracking in aggressive motion scenes that cannot be handled by other state-of-the-art methods, while our system can achieve competitive performance with these methods in general scenes. In terms of efficiency, the RC-Vox allows our system to achieve the fastest speed compared with the current advanced LIO systems.
Multi-fidelity surrogate modeling for temperature field prediction using deep convolution neural network
Jan 17, 2023



Temperature field prediction is of great importance in the thermal design of systems engineering, and building the surrogate model is an effective way for the task. Generally, large amounts of labeled data are required to guarantee a good prediction performance of the surrogate model, especially the deep learning model, which have more parameters and better representational ability. However, labeled data, especially high-fidelity labeled data, are usually expensive to obtain and sometimes even impossible. To solve this problem, this paper proposes a pithy deep multi-fidelity model (DMFM) for temperature field prediction, which takes advantage of low-fidelity data to boost the performance with less high-fidelity data. First, a pre-train and fine-tune paradigm are developed in DMFM to train the low-fidelity and high-fidelity data, which significantly reduces the complexity of the deep surrogate model. Then, a self-supervised learning method for training the physics-driven deep multi-fidelity model (PD-DMFM) is proposed, which fully utilizes the physics characteristics of the engineering systems and reduces the dependence on large amounts of labeled low-fidelity data in the training process. Two diverse temperature field prediction problems are constructed to validate the effectiveness of DMFM and PD-DMFM, and the result shows that the proposed method can greatly reduce the dependence of the model on high-fidelity data.