 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
SimpleMatch: A Simple and Strong Baseline for Semantic Correspondence
Jan 18, 2026Recent advances in semantic correspondence have been largely driven by the use of pre-trained large-scale models. However, a limitation of these approaches is their dependence on high-resolution input images to achieve optimal performance, which results in considerable computational overhead. In this work, we address a fundamental limitation in current methods: the irreversible fusion of adjacent keypoint features caused by deep downsampling operations. This issue is triggered when semantically distinct keypoints fall within the same downsampled receptive field (e.g., 16x16 patches). To address this issue, we present SimpleMatch, a simple yet effective framework for semantic correspondence that delivers strong performance even at low resolutions. We propose a lightweight upsample decoder that progressively recovers spatial detail by upsampling deep features to 1/4 resolution, and a multi-scale supervised loss that ensures the upsampled features retain discriminative features across different spatial scales. In addition, we introduce sparse matching and window-based localization to optimize training memory usage and reduce it by 51%. At a resolution of 252x252 (3.3x smaller than current SOTA methods), SimpleMatch achieves superior performance with 84.1% PCK@0.1 on the SPair-71k benchmark. We believe this framework provides a practical and efficient baseline for future research in semantic correspondence. Code is available at: https://github.com/hailong23-jin/SimpleMatch.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
CollabVLA: Self-Reflective Vision-Language-Action Model Dreaming Together with Human
Sep 18, 2025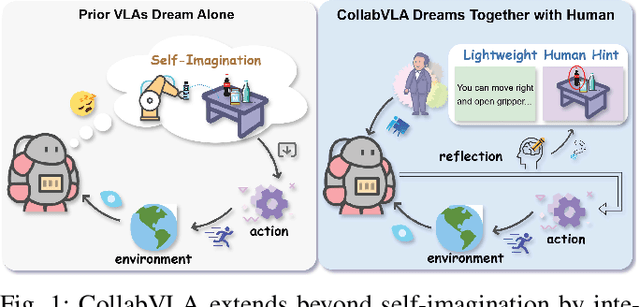
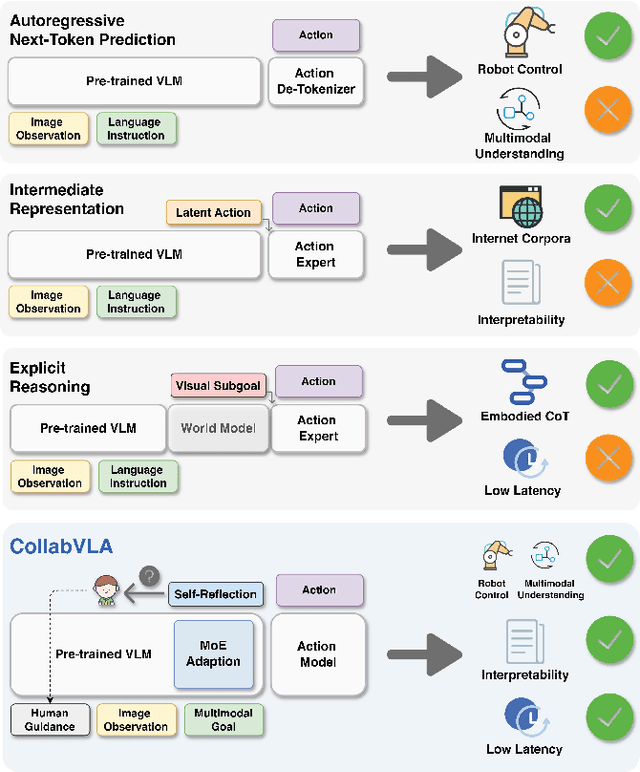

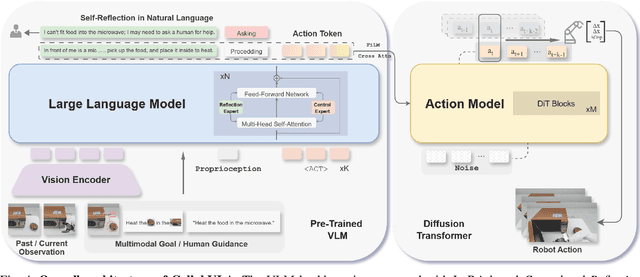
In this work, we present CollabVLA, a self-reflective vision-language-action framework that transforms a standard visuomotor policy into a collaborative assistant. CollabVLA tackles key limitations of prior VLAs, including domain overfitting, non-interpretable reasoning, and the high latency of auxiliary generative models, by integrating VLM-based reflective reasoning with diffusion-based action generation under a mixture-of-experts design. Through a two-stage training recipe of action grounding and reflection tuning, it supports explicit self-reflection and proactively solicits human guidance when confronted with uncertainty or repeated failure. It cuts normalized Time by ~2x and Dream counts by ~4x vs. generative agents, achieving higher success rates, improved interpretability, and balanced low latency compared with existing methods. This work takes a pioneering step toward shifting VLAs from opaque controllers to genuinely assistive agents capable of reasoning, acting, and collaborating with humans.
Body Discovery of Embodied AI
Mar 25, 2025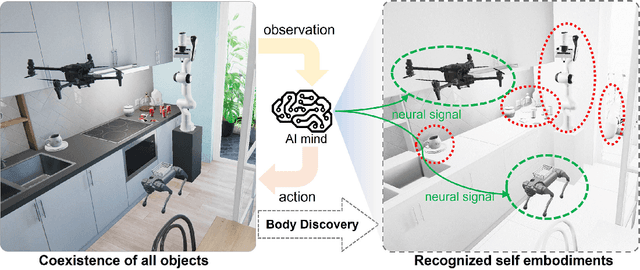

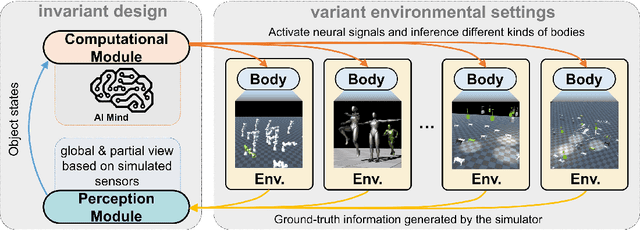
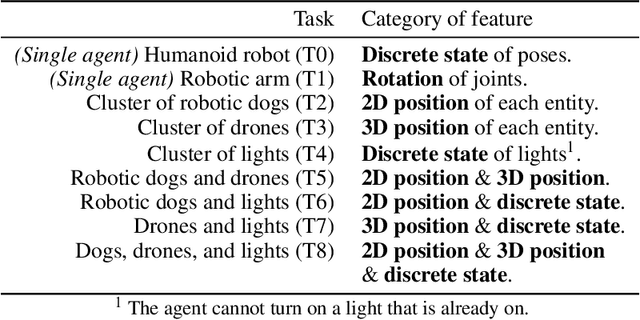
In the pursuit of realizing artificial general intelligence (AGI), the importance of embodied artificial intelligence (AI) becomes increasingly apparent. Following this trend, research integrating robots with AGI has become prominent. As various kinds of embodiments have been designed, adaptability to diverse embodiments will become important to AGI. We introduce a new challenge, termed "Body Discovery of Embodied AI", focusing on tasks of recognizing embodiments and summarizing neural signal functionality. The challenge encompasses the precise definition of an AI body and the intricate task of identifying embodiments in dynamic environments, where conventional approaches often prove inadequate. To address these challenges, we apply causal inference method and evaluate it by developing a simulator tailored for testing algorithms with virtual environments. Finally, we validate the efficacy of our algorithms through empirical testing, demonstrating their robust performance in various scenarios based on virtual environments.
Bounding-Box Inference for Error-Aware Model-Based Reinforcement Learning
Jun 23, 2024



In model-based reinforcement learning, simulated experiences from the learned model are often treated as equivalent to experience from the real environment. However, when the model is inaccurate, it can catastrophically interfere with policy learning. Alternatively, the agent might learn about the model's accuracy and selectively use it only when it can provide reliable predictions. We empirically explore model uncertainty measures for selective planning and show that best results require distribution insensitive inference to estimate the uncertainty over model-based updates. To that end, we propose and evaluate bounding-box inference, which operates on bounding-boxes around sets of possible states and other quantities. We find that bounding-box inference can reliably support effective selective planning.
Independently Keypoint Learning for Small Object Semantic Correspondence
Apr 03, 2024Semantic correspondence remains a challenging task for establishing correspondences between a pair of images with the same category or similar scenes due to the large intra-class appearance. In this paper, we introduce a novel problem called 'Small Object Semantic Correspondence (SOSC).' This problem is challenging due to the close proximity of keypoints associated with small objects, which results in the fusion of these respective features. It is difficult to identify the corresponding key points of the fused features, and it is also difficult to be recognized. To address this challenge, we propose the Keypoint Bounding box-centered Cropping (KBC) method, which aims to increase the spatial separation between keypoints of small objects, thereby facilitating independent learning of these keypoints. The KBC method is seamlessly integrated into our proposed inference pipeline and can be easily incorporated into other methodologies, resulting in significant performance enhancements. Additionally, we introduce a novel framework, named KBCNet, which serves as our baseline model. KBCNet comprises a Cross-Scale Feature Alignment (CSFA) module and an efficient 4D convolutional decoder. The CSFA module is designed to align multi-scale features, enriching keypoint representations by integrating fine-grained features and deep semantic features. Meanwhile, the 4D convolutional decoder, based on efficient 4D convolution, ensures efficiency and rapid convergence. To empirically validate the effectiveness of our proposed methodology, extensive experiments are conducted on three widely used benchmarks: PF-PASCAL, PF-WILLOW, and SPair-71k. Our KBC method demonstrates a substantial performance improvement of 7.5\% on the SPair-71K dataset, providing compelling evidence of its efficacy.
Question Answering Over Spatio-Temporal Knowledge Graph
Feb 18, 2024



Spatio-temporal knowledge graphs (STKGs) extend the concept of knowledge graphs (KGs) by incorporating time and location information. While the research community's focus on Knowledge Graph Question Answering (KGQA), the field of answering questions incorporating both spatio-temporal information based on STKGs remains largely unexplored. Furthermore, a lack of comprehensive datasets also has hindered progress in this area. To address this issue, we present STQAD, a dataset comprising 10,000 natural language questions for spatio-temporal knowledge graph question answering (STKGQA). Unfortunately, various state-of-the-art KGQA approaches fall far short of achieving satisfactory performance on our dataset. In response, we propose STCQA, a new spatio-temporal KGQA approach that utilizes a novel STKG embedding method named STComplEx. By extracting temporal and spatial information from a question, our QA model can better comprehend the question and retrieve accurate answers from the STKG. Through extensive experiments, we demonstrate the quality of our dataset and the effectiveness of our STKGQA method.
Can Backdoor Attacks Survive Time-Varying Models?
Jun 08, 2022
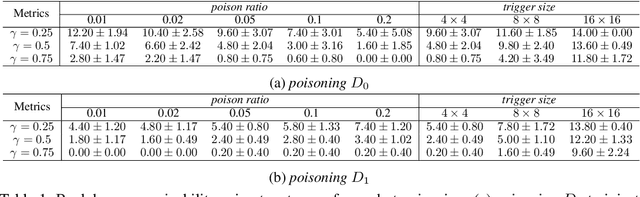
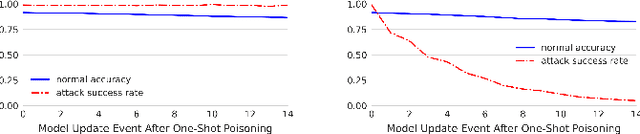

Backdoors are powerful attacks against deep neural networks (DNNs). By poisoning training data, attackers can inject hidden rules (backdoors) into DNNs, which only activate on inputs containing attack-specific triggers. While existing work has studied backdoor attacks on a variety of DNN models, they only consider static models, which remain unchanged after initial deployment. In this paper, we study the impact of backdoor attacks on a more realistic scenario of time-varying DNN models, where model weights are updated periodically to handle drifts in data distribution over time. Specifically, we empirically quantify the "survivability" of a backdoor against model updates, and examine how attack parameters, data drift behaviors, and model update strategies affect backdoor survivability. Our results show that one-shot backdoor attacks (i.e., only poisoning training data once) do not survive past a few model updates, even when attackers aggressively increase trigger size and poison ratio. To stay unaffected by model update, attackers must continuously introduce corrupted data into the training pipeline. Together, these results indicate that when models are updated to learn new data, they also "forget" backdoors as hidden, malicious features. The larger the distribution shift between old and new training data, the faster backdoors are forgotten. Leveraging these insights, we apply a smart learning rate scheduler to further accelerate backdoor forgetting during model updates, which prevents one-shot backdoors from surviving past a single model update.
Outlining and Filling: Hierarchical Query Graph Generation for Answering Complex Questions over Knowledge Graph
Nov 01, 2021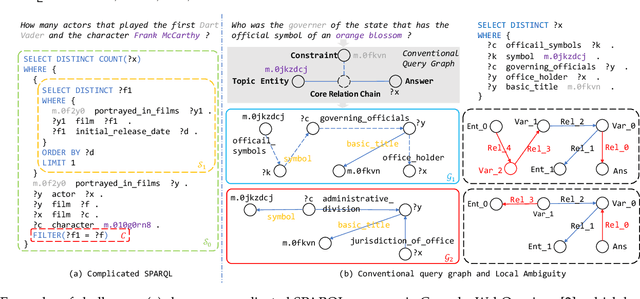
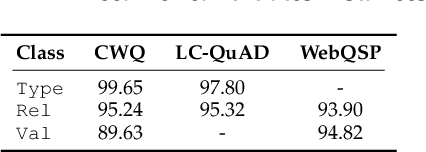
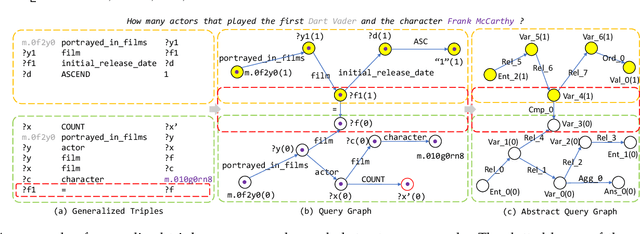
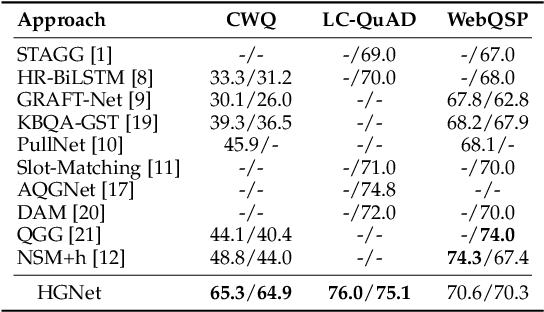
Query graph building aims to build correct executable SPARQL over the knowledge graph for answering natural language questions. Although recent approaches perform well by NN-based query graph ranking, more complex questions bring three new challenges: complicated SPARQL syntax, huge search space for ranking, and noisy query graphs with local ambiguity. This paper handles these challenges. Initially, we regard common complicated SPARQL syntax as the sub-graphs comprising of vertices and edges and propose a new unified query graph grammar to adapt them. Subsequently, we propose a new two-stage approach to build query graphs. In the first stage, the top-$k$ related instances (entities, relations, etc.) are collected by simple strategies, as the candidate instances. In the second stage, a graph generation model performs hierarchical generation. It first outlines a graph structure whose vertices and edges are empty slots, and then fills the appropriate instances into the slots, thereby completing the query graph. Our approach decomposes the unbearable search space of entire query graphs into affordable sub-spaces of operations, meanwhile, leverages the global structural information to eliminate local ambiguity. The experimental results demonstrate that our approach greatly improves state-of-the-art on the hardest KGQA benchmarks and has an excellent performance on complex questions.