 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftmax Linear Attention: Reclaiming Global Competition
Feb 02, 2026While linear attention reduces the quadratic complexity of standard Transformers to linear time, it often lags behind in expressivity due to the removal of softmax normalization. This omission eliminates \emph{global competition}, a critical mechanism that enables models to sharply focus on relevant information amidst long-context noise. In this work, we propose \textbf{Softmax Linear Attention (SLA)}, a framework designed to restore this competitive selection without sacrificing efficiency. By lifting the softmax operation from the token level to the head level, SLA leverages attention heads as coarse semantic slots, applying a competitive gating mechanism to dynamically select the most relevant subspaces. This reintroduces the ``winner-take-all'' dynamics essential for precise retrieval and robust long-context understanding. Distinct from prior methods that focus on refining local kernel functions, SLA adopts a broader perspective by exploiting the higher-level multi-head aggregation structure. Extensive experiments demonstrate that SLA consistently enhances state-of-the-art linear baselines (RetNet, GLA, GDN) across language modeling and long-context benchmarks, particularly in challenging retrieval scenarios where it significantly boosts robustness against noise, validating its capability to restore precise focus while maintaining linear complexity.
Parameterizing Context: Unleashing the Power of Parameter-Efficient Fine-Tuning and In-Context Tuning for Continual Table Semantic Parsing
Oct 07, 2023


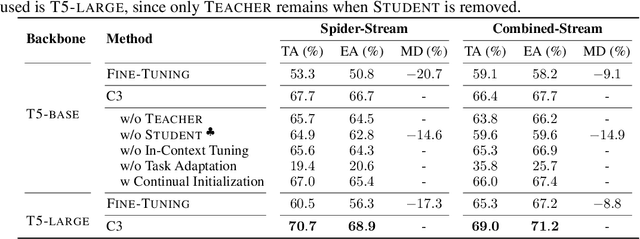
Continual table semantic parsing aims to train a parser on a sequence of tasks, where each task requires the parser to translate natural language into SQL based on task-specific tables but only offers limited training examples. Conventional methods tend to suffer from overfitting with limited supervision, as well as catastrophic forgetting due to parameter updates. Despite recent advancements that partially alleviate these issues through semi-supervised data augmentation and retention of a few past examples, the performance is still limited by the volume of unsupervised data and stored examples. To overcome these challenges, this paper introduces a novel method integrating \textit{parameter-efficient fine-tuning} (PEFT) and \textit{in-context tuning} (ICT) for training a continual table semantic parser. Initially, we present a task-adaptive PEFT framework capable of fully circumventing catastrophic forgetting, which is achieved by freezing the pre-trained model backbone and fine-tuning small-scale prompts. Building on this, we propose a teacher-student framework-based solution. The teacher addresses the few-shot problem using ICT, which procures contextual information by demonstrating a few training examples. In turn, the student leverages the proposed PEFT framework to learn from the teacher's output distribution, and subsequently compresses and saves the contextual information to the prompts, eliminating the need to store any training examples. Experimental evaluations on two benchmarks affirm the superiority of our method over prevalent few-shot and continual learning baselines across various metrics.
Learn from Yesterday: A Semi-Supervised Continual Learning Method for Supervision-Limited Text-to-SQL Task Streams
Nov 21, 2022



Conventional text-to-SQL studies are limited to a single task with a fixed-size training and test set. When confronted with a stream of tasks common in real-world applications, existing methods struggle with the problems of insufficient supervised data and high retraining costs. The former tends to cause overfitting on unseen databases for the new task, while the latter makes a full review of instances from past tasks impractical for the model, resulting in forgetting of learned SQL structures and database schemas. To address the problems, this paper proposes integrating semi-supervised learning (SSL) and continual learning (CL) in a stream of text-to-SQL tasks and offers two promising solutions in turn. The first solution Vanilla is to perform self-training, augmenting the supervised training data with predicted pseudo-labeled instances of the current task, while replacing the full volume retraining with episodic memory replay to balance the training efficiency with the performance of previous tasks. The improved solution SFNet takes advantage of the intrinsic connection between CL and SSL. It uses in-memory past information to help current SSL, while adding high-quality pseudo instances in memory to improve future replay. The experiments on two datasets shows that SFNet outperforms the widely-used SSL-only and CL-only baselines on multiple metrics.
Leveraging Table Content for Zero-shot Text-to-SQL with Meta-Learning
Sep 12, 2021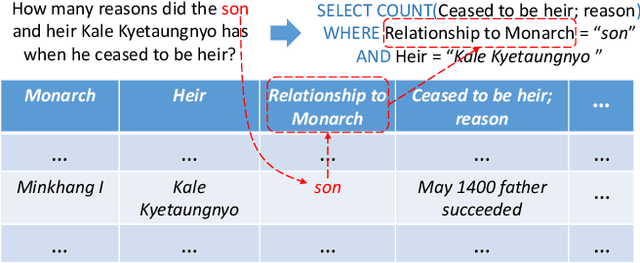
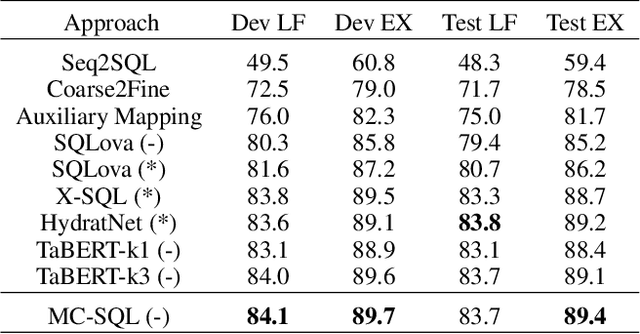
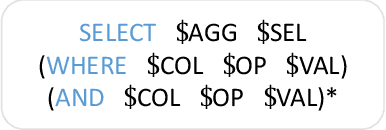
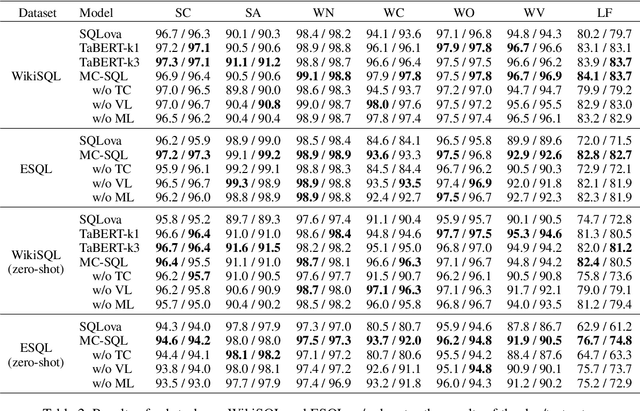
Single-table text-to-SQL aims to transform a natural language question into a SQL query according to one single table. Recent work has made promising progress on this task by pre-trained language models and a multi-submodule framework. However, zero-shot table, that is, the invisible table in the training set, is currently the most critical bottleneck restricting the application of existing approaches to real-world scenarios. Although some work has utilized auxiliary tasks to help handle zero-shot tables, expensive extra manual annotation limits their practicality. In this paper, we propose a new approach for the zero-shot text-to-SQL task which does not rely on any additional manual annotations. Our approach consists of two parts. First, we propose a new model that leverages the abundant information of table content to help establish the mapping between questions and zero-shot tables. Further, we propose a simple but efficient meta-learning strategy to train our model. The strategy utilizes the two-step gradient update to force the model to learn a generalization ability towards zero-shot tables. We conduct extensive experiments on a public open-domain text-to-SQL dataset WikiSQL and a domain-specific dataset ESQL. Compared to existing approaches using the same pre-trained model, our approach achieves significant improvements on both datasets. Compared to the larger pre-trained model and the tabular-specific pre-trained model, our approach is still competitive. More importantly, on the zero-shot subsets of both the datasets, our approach further increases the improvements.