 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP-TransientBench: A Real-Captured Single Photon Perception Benchmark
Jun 16, 2026Single-photon LiDAR (SPL) based on single-photon avalanche diode (SPAD) sensing enables time-resolved photon measurements with extreme sensitivity, offering unique potential for active 3D perception in photon-starved scenarios.However, real-world single photon perception remains fundamentally challenging due to unique measurement noise and complex multi-return transient phenomena, which jointly complicate geometric reconstruction and semantic scene understanding. Despite growing interest in SPAD-based sensing, existing studies are largely limited to simulated data or small-scale controlled captures. As a result, systematic evaluation of real-world single photon perception across depth estimation, multi-view reconstruction, and 3D semantic understanding remains underexplored. To bridge this gap, we introduce SP-TransientBench (STB), a real-captured multi-task benchmark for single photon perception. SP-TransientBenc comprises 10 diverse scenes and 10,297 views captured using a solid-state single-photon LiDAR at $256\times192$ resolution. Each view provides full time-of-flight histograms with multi-return behavior,standardized metadata, and calibrated camera poses for multi-view evaluation. We further provide 13-class 3D semantic annotations for selected scenes. By providing dedicated data splits and evaluation protocols for each task, STB enables consistent and reproducible benchmarking of real-world single photon perception across multiple 3D vision problems. The dataset and code will be released upon acceptance.
CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation
Jan 23, 2026Large Audio Language Models (LALMs) have garnered significant research interest. Despite being built upon text-based large language models (LLMs), LALMs frequently exhibit a degradation in knowledge and reasoning capabilities. We hypothesize that this limitation stems from the failure of current training paradigms to effectively bridge the acoustic-semantic gap within the feature representation space. To address this challenge, we propose CORD, a unified alignment framework that performs online cross-modal self-distillation. Specifically, it aligns audio-conditioned reasoning with its text-conditioned counterpart within a unified model. Leveraging the text modality as an internal teacher, CORD performs multi-granularity alignment throughout the audio rollout process. At the token level, it employs on-policy reverse KL divergence with importance-aware weighting to prioritize early and semantically critical tokens. At the sequence level, CORD introduces a judge-based global reward to optimize complete reasoning trajectories via Group Relative Policy Optimization (GRPO). Empirical results across multiple benchmarks demonstrate that CORD consistently enhances audio-conditioned reasoning and substantially bridges the audio-text performance gap with only 80k synthetic training samples, validating the efficacy and data efficiency of our on-policy, multi-level cross-modal alignment approach.
IRSC: A Zero-shot Evaluation Benchmark for Information Retrieval through Semantic Comprehension in Retrieval-Augmented Generation Scenarios
Sep 26, 2024



In Retrieval-Augmented Generation (RAG) tasks using Large Language Models (LLMs), the quality of retrieved information is critical to the final output. This paper introduces the IRSC benchmark for evaluating the performance of embedding models in multilingual RAG tasks. The benchmark encompasses five retrieval tasks: query retrieval, title retrieval, part-of-paragraph retrieval, keyword retrieval, and summary retrieval. Our research addresses the current lack of comprehensive testing and effective comparison methods for embedding models in RAG scenarios. We introduced new metrics: the Similarity of Semantic Comprehension Index (SSCI) and the Retrieval Capability Contest Index (RCCI), and evaluated models such as Snowflake-Arctic, BGE, GTE, and M3E. Our contributions include: 1) the IRSC benchmark, 2) the SSCI and RCCI metrics, and 3) insights into the cross-lingual limitations of embedding models. The IRSC benchmark aims to enhance the understanding and development of accurate retrieval systems in RAG tasks. All code and datasets are available at: https://github.com/Jasaxion/IRSC_Benchmark
Disrupting Style Mimicry Attacks on Video Imagery
May 11, 2024



Generative AI models are often used to perform mimicry attacks, where a pretrained model is fine-tuned on a small sample of images to learn to mimic a specific artist of interest. While researchers have introduced multiple anti-mimicry protection tools (Mist, Glaze, Anti-Dreambooth), recent evidence points to a growing trend of mimicry models using videos as sources of training data. This paper presents our experiences exploring techniques to disrupt style mimicry on video imagery. We first validate that mimicry attacks can succeed by training on individual frames extracted from videos. We show that while anti-mimicry tools can offer protection when applied to individual frames, this approach is vulnerable to an adaptive countermeasure that removes protection by exploiting randomness in optimization results of consecutive (nearly-identical) frames. We develop a new, tool-agnostic framework that segments videos into short scenes based on frame-level similarity, and use a per-scene optimization baseline to remove inter-frame randomization while reducing computational cost. We show via both image level metrics and an end-to-end user study that the resulting protection restores protection against mimicry (including the countermeasure). Finally, we develop another adaptive countermeasure and find that it falls short against our framework.
Organic or Diffused: Can We Distinguish Human Art from AI-generated Images?
Feb 06, 2024
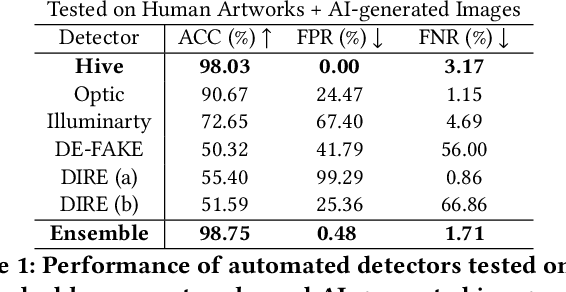
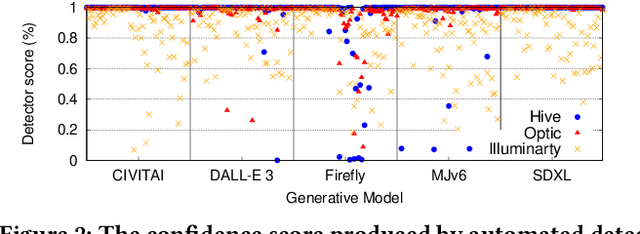
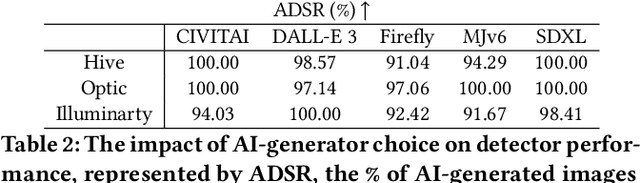
The advent of generative AI images has completely disrupted the art world. Distinguishing AI generated images from human art is a challenging problem whose impact is growing over time. A failure to address this problem allows bad actors to defraud individuals paying a premium for human art and companies whose stated policies forbid AI imagery. It is also critical for content owners to establish copyright, and for model trainers interested in curating training data in order to avoid potential model collapse. There are several different approaches to distinguishing human art from AI images, including classifiers trained by supervised learning, research tools targeting diffusion models, and identification by professional artists using their knowledge of artistic techniques. In this paper, we seek to understand how well these approaches can perform against today's modern generative models in both benign and adversarial settings. We curate real human art across 7 styles, generate matching images from 5 generative models, and apply 8 detectors (5 automated detectors and 3 different human groups including 180 crowdworkers, 4000+ professional artists, and 13 expert artists experienced at detecting AI). Both Hive and expert artists do very well, but make mistakes in different ways (Hive is weaker against adversarial perturbations while Expert artists produce higher false positives). We believe these weaknesses will remain as models continue to evolve, and use our data to demonstrate why a combined team of human and automated detectors provides the best combination of accuracy and robustness.
Towards Scalable and Robust Model Versioning
Jan 17, 2024As the deployment of deep learning models continues to expand across industries, the threat of malicious incursions aimed at gaining access to these deployed models is on the rise. Should an attacker gain access to a deployed model, whether through server breaches, insider attacks, or model inversion techniques, they can then construct white-box adversarial attacks to manipulate the model's classification outcomes, thereby posing significant risks to organizations that rely on these models for critical tasks. Model owners need mechanisms to protect themselves against such losses without the necessity of acquiring fresh training data - a process that typically demands substantial investments in time and capital. In this paper, we explore the feasibility of generating multiple versions of a model that possess different attack properties, without acquiring new training data or changing model architecture. The model owner can deploy one version at a time and replace a leaked version immediately with a new version. The newly deployed model version can resist adversarial attacks generated leveraging white-box access to one or all previously leaked versions. We show theoretically that this can be accomplished by incorporating parameterized hidden distributions into the model training data, forcing the model to learn task-irrelevant features uniquely defined by the chosen data. Additionally, optimal choices of hidden distributions can produce a sequence of model versions capable of resisting compound transferability attacks over time. Leveraging our analytical insights, we design and implement a practical model versioning method for DNN classifiers, which leads to significant robustness improvements over existing methods. We believe our work presents a promising direction for safeguarding DNN services beyond their initial deployment.
Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
Oct 20, 2023Data poisoning attacks manipulate training data to introduce unexpected behaviors into machine learning models at training time. For text-to-image generative models with massive training datasets, current understanding of poisoning attacks suggests that a successful attack would require injecting millions of poison samples into their training pipeline. In this paper, we show that poisoning attacks can be successful on generative models. We observe that training data per concept can be quite limited in these models, making them vulnerable to prompt-specific poisoning attacks, which target a model's ability to respond to individual prompts. We introduce Nightshade, an optimized prompt-specific poisoning attack where poison samples look visually identical to benign images with matching text prompts. Nightshade poison samples are also optimized for potency and can corrupt an Stable Diffusion SDXL prompt in <100 poison samples. Nightshade poison effects "bleed through" to related concepts, and multiple attacks can composed together in a single prompt. Surprisingly, we show that a moderate number of Nightshade attacks can destabilize general features in a text-to-image generative model, effectively disabling its ability to generate meaningful images. Finally, we propose the use of Nightshade` and similar tools as a last defense for content creators against web scrapers that ignore opt-out/do-not-crawl directives, and discuss possible implications for model trainers and content creators.
Investigating Graph Structure Information for Entity Alignment with Dangling Cases
Apr 10, 2023Entity alignment (EA) aims to discover the equivalent entities in different knowledge graphs (KGs), which play an important role in knowledge engineering. Recently, EA with dangling entities has been proposed as a more realistic setting, which assumes that not all entities have corresponding equivalent entities. In this paper, we focus on this setting. Some work has explored this problem by leveraging translation API, pre-trained word embeddings, and other off-the-shelf tools. However, these approaches over-rely on the side information (e.g., entity names), and fail to work when the side information is absent. On the contrary, they still insufficiently exploit the most fundamental graph structure information in KG. To improve the exploitation of the structural information, we propose a novel entity alignment framework called Weakly-Optimal Graph Contrastive Learning (WOGCL), which is refined on three dimensions : (i) Model. We propose a novel Gated Graph Attention Network to capture local and global graph structure similarity. (ii) Training. Two learning objectives: contrastive learning and optimal transport learning are designed to obtain distinguishable entity representations via the optimal transport plan. (iii) Inference. In the inference phase, a PageRank-based method is proposed to calculate higher-order structural similarity. Extensive experiments on two dangling benchmarks demonstrate that our WOGCL outperforms the current state-of-the-art methods with pure structural information in both traditional (relaxed) and dangling (consolidated) settings. The code will be public soon.
Characterizing the Optimal 0-1 Loss for Multi-class Classification with a Test-time Attacker
Feb 21, 2023



Finding classifiers robust to adversarial examples is critical for their safe deployment. Determining the robustness of the best possible classifier under a given threat model for a given data distribution and comparing it to that achieved by state-of-the-art training methods is thus an important diagnostic tool. In this paper, we find achievable information-theoretic lower bounds on loss in the presence of a test-time attacker for multi-class classifiers on any discrete dataset. We provide a general framework for finding the optimal 0-1 loss that revolves around the construction of a conflict hypergraph from the data and adversarial constraints. We further define other variants of the attacker-classifier game that determine the range of the optimal loss more efficiently than the full-fledged hypergraph construction. Our evaluation shows, for the first time, an analysis of the gap to optimal robustness for classifiers in the multi-class setting on benchmark datasets.
Visually Grounded Commonsense Knowledge Acquisition
Nov 22, 2022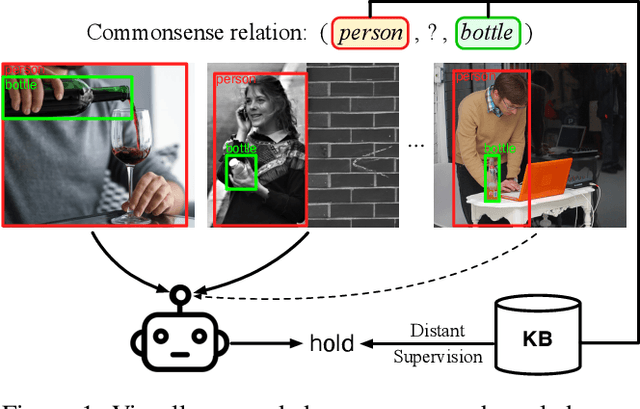
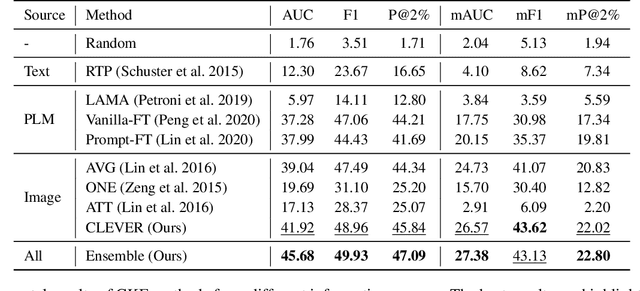
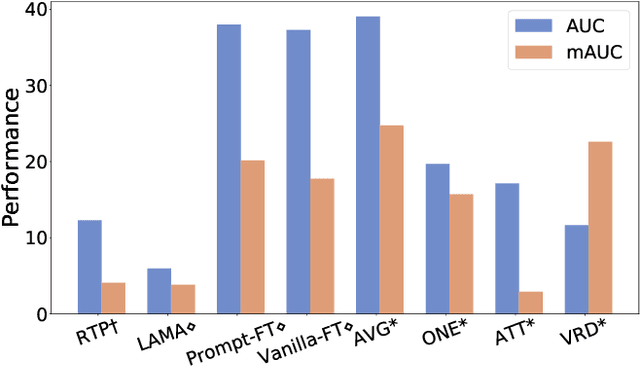
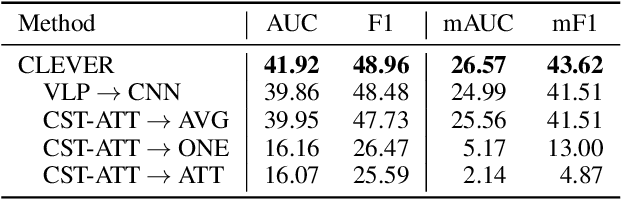
Large-scale commonsense knowledge bases empower a broad range of AI applications, where the automatic extraction of commonsense knowledge (CKE) is a fundamental and challenging problem. CKE from text is known for suffering from the inherent sparsity and reporting bias of commonsense in text. Visual perception, on the other hand, contains rich commonsense knowledge about real-world entities, e.g., (person, can_hold, bottle), which can serve as promising sources for acquiring grounded commonsense knowledge. In this work, we present CLEVER, which formulates CKE as a distantly supervised multi-instance learning problem, where models learn to summarize commonsense relations from a bag of images about an entity pair without any human annotation on image instances. To address the problem, CLEVER leverages vision-language pre-training models for deep understanding of each image in the bag, and selects informative instances from the bag to summarize commonsense entity relations via a novel contrastive attention mechanism. Comprehensive experimental results in held-out and human evaluation show that CLEVER can extract commonsense knowledge in promising quality, outperforming pre-trained language model-based methods by 3.9 AUC and 6.4 mAUC points. The predicted commonsense scores show strong correlation with human judgment with a 0.78 Spearman coefficient. Moreover, the extracted commonsense can also be grounded into images with reasonable interpretability. The data and codes can be obtained at https://github.com/thunlp/CLEVER.