 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience-Driven Dynamic Exits for LLMs with Reinforcement Learning
Jun 02, 2026Large Language Models suffer from slow autoregressive inference. While self-speculative decoding accelerates this process, its efficiency is hampered by static configurations like fixed exit layers and speculation lengths. We reframe this optimization as a \textbf{Markov Decision Process} and propose \textbf{LEDE}, a framework that uses offline reinforcement learning. LEDE learns a policy to dynamically select the optimal exit layer and speculation length based on the local context of the generated sequence at each step, balancing computational cost and draft quality. Comprehensive evaluations on Llama-2 and Llama-3 models show LEDE achieves up to a $2.0\times$$\sim$$2.7\times$ speedup over autoregressive decoding and and provides an additional 17\% speedup over the static speculative baselines.
ARBOR: Online Process Rewards via a Reusable Rubric Buffer for Search Agents
Jun 02, 2026LLM-based search agents are trained predominantly with outcome-only reward, leaving the search process itself unsupervised. This signal degenerates on outcome-homogeneous groups where all sampled trajectories share the same correctness, yielding zero within-group advantage and no gradient. Existing process supervision either trains a costly verifier or generates per-query rubrics that are inconsistent across queries and discarded after one use. We propose ARBOR (Adaptive Rubric Buffer for Online Reward), a reusable process-reward framework that maintains a rubric memory shared across queries. Query-local drafts induced from contrastive trajectories are admitted, consolidated into cross-query common rubrics, and retired as the policy evolves. A small active subset of common rubrics scores trajectories via sparse pairwise judging, and the resulting scores are added to the base reward, providing process-level gradient even when outcome reward is uniform. ARBOR consistently outperforms GRPO and DAPO baselines on four multi-hop QA benchmarks, raising average LLM-judge accuracy by up to 4.2 points and converting up to 42% of otherwise-zero-gradient training groups into informative ones.
SemantiCache: Efficient KV Cache Compression via Semantic Chunking and Clustered Merging
Mar 15, 2026Existing KV cache compression methods generally operate on discrete tokens or non-semantic chunks. However, such approaches often lead to semantic fragmentation, where linguistically coherent units are disrupted, causing irreversible information loss and degradation in model performance. To address this, we introduce SemantiCache, a novel compression framework that preserves semantic integrity by aligning the compression process with the semantic hierarchical nature of language. Specifically, we first partition the cache into semantically coherent chunks by delimiters, which are natural semantic boundaries. Within each chunk, we introduce a computationally efficient Greedy Seed-Based Clustering (GSC) algorithm to group tokens into semantic clusters. These clusters are further merged into semantic cores, enhanced by a Proportional Attention mechanism that rebalances the reduced attention contributions of the merged tokens. Extensive experiments across diverse benchmarks and models demonstrate that SemantiCache accelerates the decoding stage of inference by up to 2.61 times and substantially reduces memory footprint, while maintaining performance comparable to the original model.
3ViewSense: Spatial and Mental Perspective Reasoning from Orthographic Views in Vision-Language Models
Mar 08, 2026Current Large Language Models have achieved Olympiad-level logic, yet Vision-Language Models paradoxically falter on elementary spatial tasks like block counting. This capability mismatch reveals a critical ``spatial intelligence gap,'' where models fail to construct coherent 3D mental representations from 2D observations. We uncover this gap via diagnostic analyses showing the bottleneck is a missing view-consistent spatial interface rather than insufficient visual features or weak reasoning. To bridge this, we introduce \textbf{3ViewSense}, a framework that grounds spatial reasoning in Orthographic Views. Drawing on engineering cognition, we propose a ``Simulate-and-Reason'' mechanism that decomposes complex scenes into canonical orthographic projections to resolve geometric ambiguities. By aligning egocentric perceptions with these allocentric references, our method facilitates explicit mental rotation and reconstruction. Empirical results on spatial reasoning benchmarks demonstrate that our method significantly outperforms existing baselines, with consistent gains on occlusion-heavy counting and view-consistent spatial reasoning. The framework also improves the stability and consistency of spatial descriptions, offering a scalable path toward stronger spatial intelligence in multimodal systems.
R-Align: Enhancing Generative Reward Models through Rationale-Centric Meta-Judging
Feb 06, 2026Reinforcement Learning from Human Feedback (RLHF) remains indispensable for aligning large language models (LLMs) in subjective domains. To enhance robustness, recent work shifts toward Generative Reward Models (GenRMs) that generate rationales before predicting preferences. Yet in GenRM training and evaluation, practice remains outcome-label-only, leaving reasoning quality unchecked. We show that reasoning fidelity-the consistency between a GenRM's preference decision and reference decision rationales-is highly predictive of downstream RLHF outcomes, beyond standard label accuracy. Specifically, we repurpose existing reward-model benchmarks to compute Spurious Correctness (S-Corr)-the fraction of label-correct decisions with rationales misaligned with golden judgments. Our empirical evaluation reveals substantial S-Corr even for competitive GenRMs, and higher S-Corr is associated with policy degeneration under optimization. To improve fidelity, we propose Rationale-Centric Alignment, R-Align, which augments training with gold judgments and explicitly supervises rationale alignment. R-Align reduces S-Corr on RM benchmarks and yields consistent gains in actor performance across STEM, coding, instruction following, and general tasks.
Intention Chain-of-Thought Prompting with Dynamic Routing for Code Generation
Dec 16, 2025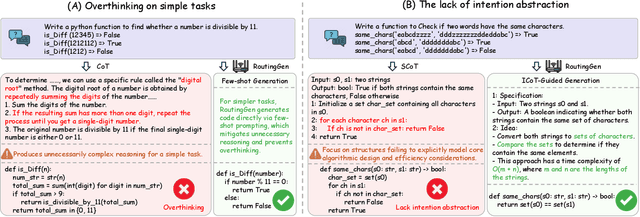
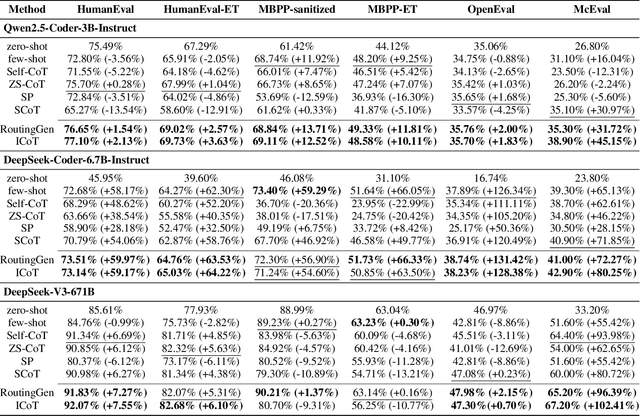
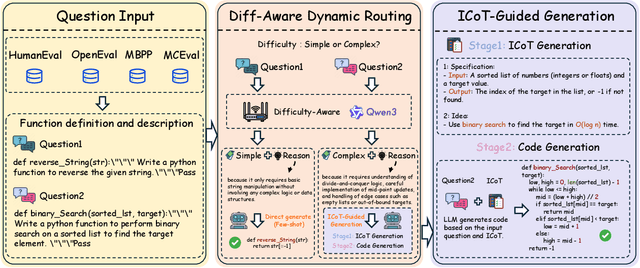
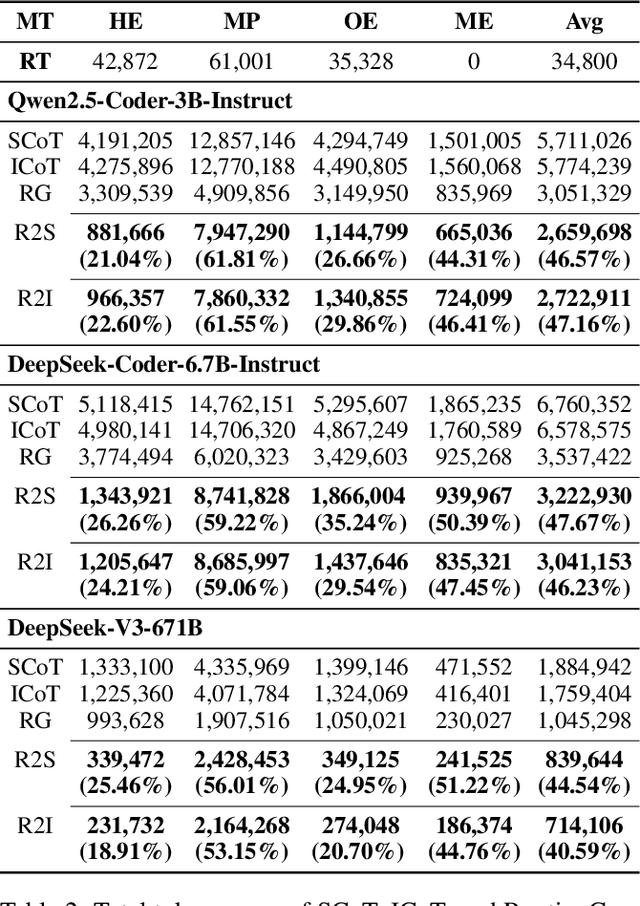
Large language models (LLMs) exhibit strong generative capabilities and have shown great potential in code generation. Existing chain-of-thought (CoT) prompting methods enhance model reasoning by eliciting intermediate steps, but suffer from two major limitations: First, their uniform application tends to induce overthinking on simple tasks. Second, they lack intention abstraction in code generation, such as explicitly modeling core algorithmic design and efficiency, leading models to focus on surface-level structures while neglecting the global problem objective. Inspired by the cognitive economy principle of engaging structured reasoning only when necessary to conserve cognitive resources, we propose RoutingGen, a novel difficulty-aware routing framework that dynamically adapts prompting strategies for code generation. For simple tasks, it adopts few-shot prompting; for more complex ones, it invokes a structured reasoning strategy, termed Intention Chain-of-Thought (ICoT), which we introduce to guide the model in capturing task intention, such as the core algorithmic logic and its time complexity. Experiments across three models and six standard code generation benchmarks show that RoutingGen achieves state-of-the-art performance in most settings, while reducing total token usage by 46.37% on average across settings. Furthermore, ICoT outperforms six existing prompting baselines on challenging benchmarks.
LexSemBridge: Fine-Grained Dense Representation Enhancement through Token-Aware Embedding Augmentation
Aug 25, 2025As queries in retrieval-augmented generation (RAG) pipelines powered by large language models (LLMs) become increasingly complex and diverse, dense retrieval models have demonstrated strong performance in semantic matching. Nevertheless, they often struggle with fine-grained retrieval tasks, where precise keyword alignment and span-level localization are required, even in cases with high lexical overlap that would intuitively suggest easier retrieval. To systematically evaluate this limitation, we introduce two targeted tasks, keyword retrieval and part-of-passage retrieval, designed to simulate practical fine-grained scenarios. Motivated by these observations, we propose LexSemBridge, a unified framework that enhances dense query representations through fine-grained, input-aware vector modulation. LexSemBridge constructs latent enhancement vectors from input tokens using three paradigms: Statistical (SLR), Learned (LLR), and Contextual (CLR), and integrates them with dense embeddings via element-wise interaction. Theoretically, we show that this modulation preserves the semantic direction while selectively amplifying discriminative dimensions. LexSemBridge operates as a plug-in without modifying the backbone encoder and naturally extends to both text and vision modalities. Extensive experiments across semantic and fine-grained retrieval tasks validate the effectiveness and generality of our approach. All code and models are publicly available at https://github.com/Jasaxion/LexSemBridge/
MathSmith: Towards Extremely Hard Mathematical Reasoning by Forging Synthetic Problems with a Reinforced Policy
Aug 07, 2025Large language models have achieved substantial progress in mathematical reasoning, yet their advancement is limited by the scarcity of high-quality, high-difficulty training data. Existing synthesis methods largely rely on transforming human-written templates, limiting both diversity and scalability. We propose MathSmith, a novel framework for synthesizing challenging mathematical problems to enhance LLM reasoning. Rather than modifying existing problems, MathSmith constructs new ones from scratch by randomly sampling concept-explanation pairs from PlanetMath, ensuring data independence and avoiding contamination. To increase difficulty, we design nine predefined strategies as soft constraints during rationales. We further adopts reinforcement learning to jointly optimize structural validity, reasoning complexity, and answer consistency. The length of the reasoning trace generated under autoregressive prompting is used to reflect cognitive complexity, encouraging the creation of more demanding problems aligned with long-chain-of-thought reasoning. Experiments across five benchmarks, categorized as easy & medium (GSM8K, MATH-500) and hard (AIME2024, AIME2025, OlympiadBench), show that MathSmith consistently outperforms existing baselines under both short and long CoT settings. Additionally, a weakness-focused variant generation module enables targeted improvement on specific concepts. Overall, MathSmith exhibits strong scalability, generalization, and transferability, highlighting the promise of high-difficulty synthetic data in advancing LLM reasoning capabilities.
A Hierarchical Framework for Measuring Scientific Paper Innovation via Large Language Models
Apr 20, 2025Measuring scientific paper innovation is both important and challenging. Existing content-based methods often overlook the full-paper context, fail to capture the full scope of innovation, and lack generalization. We propose HSPIM, a hierarchical and training-free framework based on large language models (LLMs). It introduces a Paper-to-Sections-to-QAs decomposition to assess innovation. We segment the text by section titles and use zero-shot LLM prompting to implement section classification, question-answering (QA) augmentation, and weighted novelty scoring. The generated QA pair focuses on section-level innovation and serves as additional context to improve the LLM scoring. For each chunk, the LLM outputs a novelty score and a confidence score. We use confidence scores as weights to aggregate novelty scores into a paper-level innovation score. To further improve performance, we propose a two-layer question structure consisting of common and section-specific questions, and apply a genetic algorithm to optimize the question-prompt combinations. Comprehensive experiments on scientific conference paper datasets show that HSPIM outperforms baseline methods in effectiveness, generalization, and interpretability.
IRSC: A Zero-shot Evaluation Benchmark for Information Retrieval through Semantic Comprehension in Retrieval-Augmented Generation Scenarios
Sep 26, 2024



In Retrieval-Augmented Generation (RAG) tasks using Large Language Models (LLMs), the quality of retrieved information is critical to the final output. This paper introduces the IRSC benchmark for evaluating the performance of embedding models in multilingual RAG tasks. The benchmark encompasses five retrieval tasks: query retrieval, title retrieval, part-of-paragraph retrieval, keyword retrieval, and summary retrieval. Our research addresses the current lack of comprehensive testing and effective comparison methods for embedding models in RAG scenarios. We introduced new metrics: the Similarity of Semantic Comprehension Index (SSCI) and the Retrieval Capability Contest Index (RCCI), and evaluated models such as Snowflake-Arctic, BGE, GTE, and M3E. Our contributions include: 1) the IRSC benchmark, 2) the SSCI and RCCI metrics, and 3) insights into the cross-lingual limitations of embedding models. The IRSC benchmark aims to enhance the understanding and development of accurate retrieval systems in RAG tasks. All code and datasets are available at: https://github.com/Jasaxion/IRSC_Benchmark