 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Pulse-Shaped OFDM Framework for Chirp-Domain Waveforms: Continuous-Time Modeling and Practical I/O Analysis
Mar 15, 2026In this paper, a unified framework for chirp-domain waveforms, including orthogonal chirp division multiplexing (OCDM) and affine frequency division multiplexing (AFDM), is developed. Based on their continuous-time representations, we show that these waveforms fall within the conventional Weyl-Heisenberg (WH) framework for multicarrier (MC) waveforms, where the root chirp corresponds directly to the prototype pulse in the WH framework. Since the chirp is a constant-envelope signal and is transparent to subcarrier orthogonality, these waveforms can be further interpreted as pulse-shaped (PS) orthogonal frequency division multiplexing (OFDM). Within the developed PS-OFDM framework, the power spectral density of chirp-domain waveforms is derived analytically. We then discuss existing practical implementations of chirp-domain waveforms, which rely on sub-Nyquist discrete-time samples and therefore exhibit frequency aliasing. The resulting aliased waveform is analyzed, and the orthogonality among the embedded aliased chirps is discussed. It is shown that the aliased chirps are conditionally orthogonal, whereas the implemented approximate aliased chirps can maintain mutual orthogonality when an appropriate sample-wise pulse-shaping filter is applied. We further derive an exact input-output relation for the implemented chirp-domain waveform over a delay-Doppler (DD) channel, showing that the effective channel observed at a practical receiver does not, in general, admit a DD spreading-function model commonly assumed in the literature. The implementation complexity is also investigated and compared with that of orthogonal delay-Doppler division multiplexing (ODDM), the DD-domain MC waveform defined within the evolved WH framework. Finally, simulation results are provided to verify the analysis.
SemantiCache: Efficient KV Cache Compression via Semantic Chunking and Clustered Merging
Mar 15, 2026Existing KV cache compression methods generally operate on discrete tokens or non-semantic chunks. However, such approaches often lead to semantic fragmentation, where linguistically coherent units are disrupted, causing irreversible information loss and degradation in model performance. To address this, we introduce SemantiCache, a novel compression framework that preserves semantic integrity by aligning the compression process with the semantic hierarchical nature of language. Specifically, we first partition the cache into semantically coherent chunks by delimiters, which are natural semantic boundaries. Within each chunk, we introduce a computationally efficient Greedy Seed-Based Clustering (GSC) algorithm to group tokens into semantic clusters. These clusters are further merged into semantic cores, enhanced by a Proportional Attention mechanism that rebalances the reduced attention contributions of the merged tokens. Extensive experiments across diverse benchmarks and models demonstrate that SemantiCache accelerates the decoding stage of inference by up to 2.61 times and substantially reduces memory footprint, while maintaining performance comparable to the original model.
3ViewSense: Spatial and Mental Perspective Reasoning from Orthographic Views in Vision-Language Models
Mar 08, 2026Current Large Language Models have achieved Olympiad-level logic, yet Vision-Language Models paradoxically falter on elementary spatial tasks like block counting. This capability mismatch reveals a critical ``spatial intelligence gap,'' where models fail to construct coherent 3D mental representations from 2D observations. We uncover this gap via diagnostic analyses showing the bottleneck is a missing view-consistent spatial interface rather than insufficient visual features or weak reasoning. To bridge this, we introduce \textbf{3ViewSense}, a framework that grounds spatial reasoning in Orthographic Views. Drawing on engineering cognition, we propose a ``Simulate-and-Reason'' mechanism that decomposes complex scenes into canonical orthographic projections to resolve geometric ambiguities. By aligning egocentric perceptions with these allocentric references, our method facilitates explicit mental rotation and reconstruction. Empirical results on spatial reasoning benchmarks demonstrate that our method significantly outperforms existing baselines, with consistent gains on occlusion-heavy counting and view-consistent spatial reasoning. The framework also improves the stability and consistency of spatial descriptions, offering a scalable path toward stronger spatial intelligence in multimodal systems.
Doppler Shift Keying Modulation for Uplink Multiple Access over Doubly-Dispersive Channels
Mar 03, 2026The delay-Doppler (DD) domain modulation has been regarded as one of the most competitive candidates to support wireless communications for emerging high-mobility applications in the sixth-generation mobile networks. Unfortunately, most of the existing designs for DD domain modulation suffer from high peak-to-average power ratio (PAPR) and unbearable detection complexity under uplink transmission since large time duration and bandwidth are required to guarantee high DD resolutions. To address these issues, the Doppler shift keying (DSK) modulation based on the orthogonal delay Doppler division multiplexing modulator is proposed in this paper, where the input-output characterization in the DD domain is fully exploited. The principle of the DSK transceiver is first established with the one-hot mapper and low-complexity iterative successive interference cancellation-maximum ratio combining detector for point-to-point scenarios. The proposed scheme is then generalized to the zero auto-correlation sequence-based implementation, which benefits the extension of multi-user (MU) uplink DSK frameworks. For uplink DSK transmission, Zadoff-Chu (ZC) sequences are adopted as the basis sequences. We optimize the assignment of ZC roots to different user equipments (UEs) by minimizing the maximum inter-user interference. This optimization process, which analyzes the root allocation, directly assigns a specific ZC sequence to each UE. The PAPR and bit error rate performance of the proposed DSK modulation with the low-complexity detector is finally verified by extensive simulation results under doubly-dispersive channels, which demonstrates the superiority of DSK modulation especially for uplink multiple access over doubly dispersive channels.
MA-enhanced Mixed Near-field and Far-field Covert Communications
Nov 11, 2025In this paper, we propose to employ a modular-based movable extremely large-scale array (XL-array) at Alice for enhancing covert communication performance. Compared with existing work that mostly considered either far-field or near-field covert communications, we consider in this paper a more general and practical mixed-field scenario, where multiple Bobs are located in either the near-field or far-field of Alice, in the presence of multiple near-field Willies. Specifically, we first consider a two-Bob-one-Willie system and show that conventional fixed-position XL-arrays suffer degraded sum-rate performance due to the energy-spread effect in mixed-field systems, which, however, can be greatly improved by subarray movement. On the other hand, for transmission covertness, it is revealed that sufficient angle difference between far-field Bob and Willie as well as adequate range difference between near-field Bob and Willie are necessary for ensuring covertness in fixed-position XL-array systems, while this requirement can be relaxed in movable XL-array systems thanks to flexible channel correlation control between Bobs and Willie. Next, for general system setups, we formulate an optimization problem to maximize the achievable sum-rate under covertness constraint. To solve this non-convex optimization problem, we first decompose it into two subproblems, corresponding to an inner problem for beamforming optimization given positions of subarrays and an outer problem for subarray movement optimization. Although these two subproblems are still non-convex, we obtain their high-quality solutions by using the successive convex approximation technique and devising a customized differential evolution algorithm, respectively. Last, numerical results demonstrate the effectiveness of proposed movable XL-array in balancing sum-rate and covert communication requirements.
LexSemBridge: Fine-Grained Dense Representation Enhancement through Token-Aware Embedding Augmentation
Aug 25, 2025As queries in retrieval-augmented generation (RAG) pipelines powered by large language models (LLMs) become increasingly complex and diverse, dense retrieval models have demonstrated strong performance in semantic matching. Nevertheless, they often struggle with fine-grained retrieval tasks, where precise keyword alignment and span-level localization are required, even in cases with high lexical overlap that would intuitively suggest easier retrieval. To systematically evaluate this limitation, we introduce two targeted tasks, keyword retrieval and part-of-passage retrieval, designed to simulate practical fine-grained scenarios. Motivated by these observations, we propose LexSemBridge, a unified framework that enhances dense query representations through fine-grained, input-aware vector modulation. LexSemBridge constructs latent enhancement vectors from input tokens using three paradigms: Statistical (SLR), Learned (LLR), and Contextual (CLR), and integrates them with dense embeddings via element-wise interaction. Theoretically, we show that this modulation preserves the semantic direction while selectively amplifying discriminative dimensions. LexSemBridge operates as a plug-in without modifying the backbone encoder and naturally extends to both text and vision modalities. Extensive experiments across semantic and fine-grained retrieval tasks validate the effectiveness and generality of our approach. All code and models are publicly available at https://github.com/Jasaxion/LexSemBridge/
Traffic-Aware Pedestrian Intention Prediction
Jul 16, 2025Accurate pedestrian intention estimation is crucial for the safe navigation of autonomous vehicles (AVs) and hence attracts a lot of research attention. However, current models often fail to adequately consider dynamic traffic signals and contextual scene information, which are critical for real-world applications. This paper presents a Traffic-Aware Spatio-Temporal Graph Convolutional Network (TA-STGCN) that integrates traffic signs and their states (Red, Yellow, Green) into pedestrian intention prediction. Our approach introduces the integration of dynamic traffic signal states and bounding box size as key features, allowing the model to capture both spatial and temporal dependencies in complex urban environments. The model surpasses existing methods in accuracy. Specifically, TA-STGCN achieves a 4.75% higher accuracy compared to the baseline model on the PIE dataset, demonstrating its effectiveness in improving pedestrian intention prediction.
Advancing Generalizable Tumor Segmentation with Anomaly-Aware Open-Vocabulary Attention Maps and Frozen Foundation Diffusion Models
May 05, 2025We explore Generalizable Tumor Segmentation, aiming to train a single model for zero-shot tumor segmentation across diverse anatomical regions. Existing methods face limitations related to segmentation quality, scalability, and the range of applicable imaging modalities. In this paper, we uncover the potential of the internal representations within frozen medical foundation diffusion models as highly efficient zero-shot learners for tumor segmentation by introducing a novel framework named DiffuGTS. DiffuGTS creates anomaly-aware open-vocabulary attention maps based on text prompts to enable generalizable anomaly segmentation without being restricted by a predefined training category list. To further improve and refine anomaly segmentation masks, DiffuGTS leverages the diffusion model, transforming pathological regions into high-quality pseudo-healthy counterparts through latent space inpainting, and applies a novel pixel-level and feature-level residual learning approach, resulting in segmentation masks with significantly enhanced quality and generalization. Comprehensive experiments on four datasets and seven tumor categories demonstrate the superior performance of our method, surpassing current state-of-the-art models across multiple zero-shot settings. Codes are available at https://github.com/Yankai96/DiffuGTS.
A Primer on Orthogonal Delay-Doppler Division Multiplexing (ODDM)
Apr 15, 2025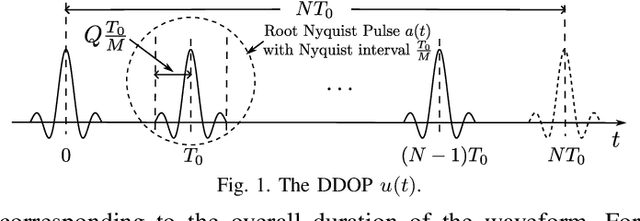
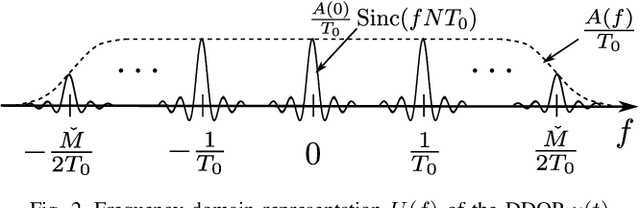
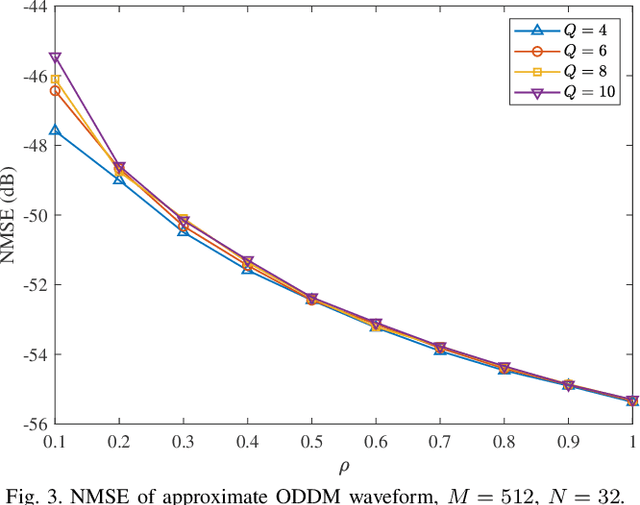
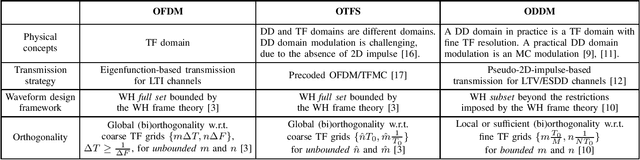
As a new type of multicarrier (MC) scheme built upon the recently discovered delay-Doppler domain orthogonal pulse (DDOP), orthogonal delay-Doppler division multiplexing (ODDM) aims to address the challenges of waveform design in linear time-varying channels. In this paper, we explore the design principles of ODDM and clarify the key ideas underlying the DDOP. We then derive an alternative representation of the DDOP and highlight the fundamental differences between ODDM and conventional MC schemes. Finally, we discuss and compare two implementation methods for ODDM.
Graph Neural Network-Based Distributed Optimal Control for Linear Networked Systems: An Online Distributed Training Approach
Apr 08, 2025In this paper, we consider the distributed optimal control problem for linear networked systems. In particular, we are interested in learning distributed optimal controllers using graph recurrent neural networks (GRNNs). Most of the existing approaches result in centralized optimal controllers with offline training processes. However, as the increasing demand of network resilience, the optimal controllers are further expected to be distributed, and are desirable to be trained in an online distributed fashion, which are also the main contributions of our work. To solve this problem, we first propose a GRNN-based distributed optimal control method, and we cast the problem as a self-supervised learning problem. Then, the distributed online training is achieved via distributed gradient computation, and inspired by the (consensus-based) distributed optimization idea, a distributed online training optimizer is designed. Furthermore, the local closed-loop stability of the linear networked system under our proposed GRNN-based controller is provided by assuming that the nonlinear activation function of the GRNN-based controller is both local sector-bounded and slope-restricted. The effectiveness of our proposed method is illustrated by numerical simulations using a specifically developed simulator.