 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Compressor:A training-free prompt compression method in long context scenarios
Paper and Code
Sep 28, 2024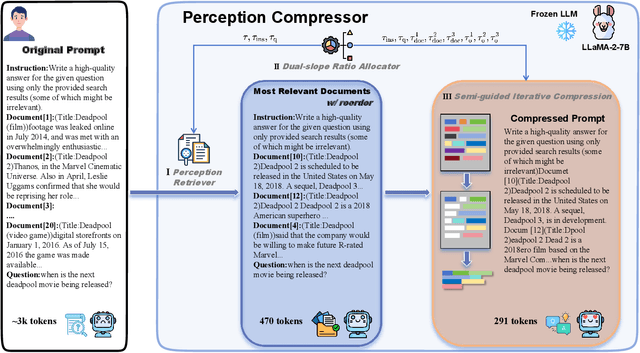
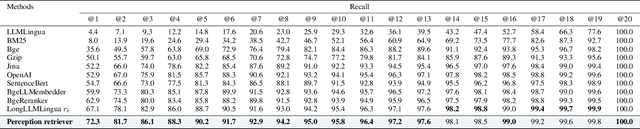
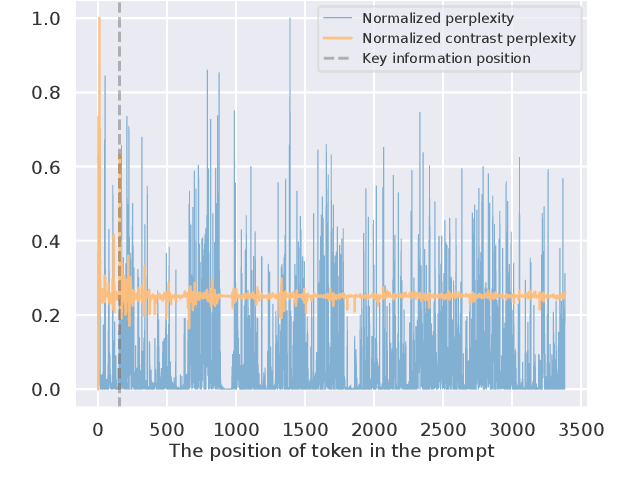
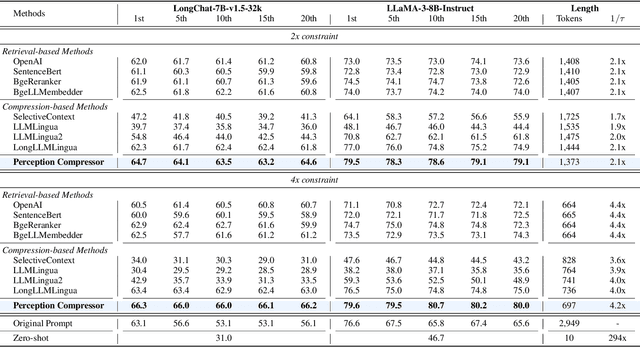
Large Language Models (LLMs) demonstrate exceptional capabilities in various scenarios. However, they suffer from much redundant information and tend to be lost in the middle in long context scenarios, leading to inferior performance. To address these challenges, we present Perception Compressor, a training-free prompt compression method. It includes a dual-slope ratio allocator to dynamically assign compression ratios and open-book ratios, a perception retriever that leverages guiding questions and instruction to retrieve the most relevant demonstrations, and a semi-guided iterative compression that retains key information at the token level while removing tokens that distract the LLM. We conduct extensive experiments on long context benchmarks, i.e., NaturalQuestions, LongBench, and MuSiQue. Experiment results show that Perception Compressor outperforms existing methods by a large margin, achieving state-of-the-art performance.