 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantiCache: Efficient KV Cache Compression via Semantic Chunking and Clustered Merging
Mar 15, 2026Existing KV cache compression methods generally operate on discrete tokens or non-semantic chunks. However, such approaches often lead to semantic fragmentation, where linguistically coherent units are disrupted, causing irreversible information loss and degradation in model performance. To address this, we introduce SemantiCache, a novel compression framework that preserves semantic integrity by aligning the compression process with the semantic hierarchical nature of language. Specifically, we first partition the cache into semantically coherent chunks by delimiters, which are natural semantic boundaries. Within each chunk, we introduce a computationally efficient Greedy Seed-Based Clustering (GSC) algorithm to group tokens into semantic clusters. These clusters are further merged into semantic cores, enhanced by a Proportional Attention mechanism that rebalances the reduced attention contributions of the merged tokens. Extensive experiments across diverse benchmarks and models demonstrate that SemantiCache accelerates the decoding stage of inference by up to 2.61 times and substantially reduces memory footprint, while maintaining performance comparable to the original model.
Read As Human: Compressing Context via Parallelizable Close Reading and Skimming
Feb 02, 2026Large Language Models (LLMs) demonstrate exceptional capability across diverse tasks. However, their deployment in long-context scenarios is hindered by two challenges: computational inefficiency and redundant information. We propose RAM (Read As HuMan), a context compression framework that adopts an adaptive hybrid reading strategy, to address these challenges. Inspired by human reading behavior (i.e., close reading important content while skimming less relevant content), RAM partitions the context into segments and encodes them with the input query in parallel. High-relevance segments are fully retained (close reading), while low-relevance ones are query-guided compressed into compact summary vectors (skimming). Both explicit textual segments and implicit summary vectors are concatenated and fed into decoder to achieve both superior performance and natural language format interpretability. To refine the decision boundary between close reading and skimming, we further introduce a contrastive learning objective based on positive and negative query-segment pairs. Experiments demonstrate that RAM outperforms existing baselines on multiple question answering and summarization benchmarks across two backbones, while delivering up to a 12x end-to-end speedup on long inputs (average length 16K; maximum length 32K).
GMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025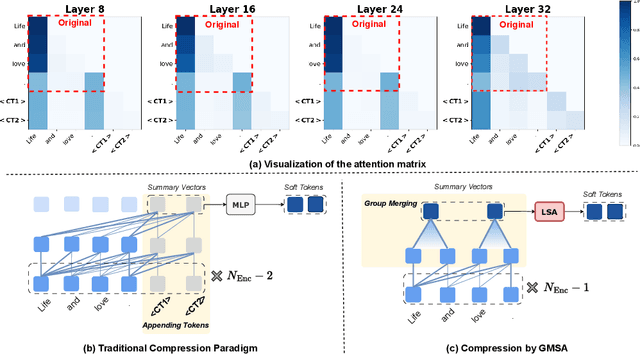
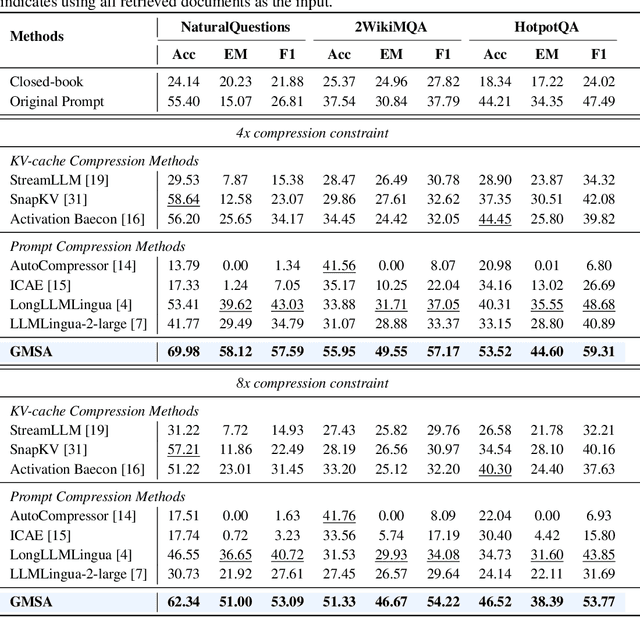
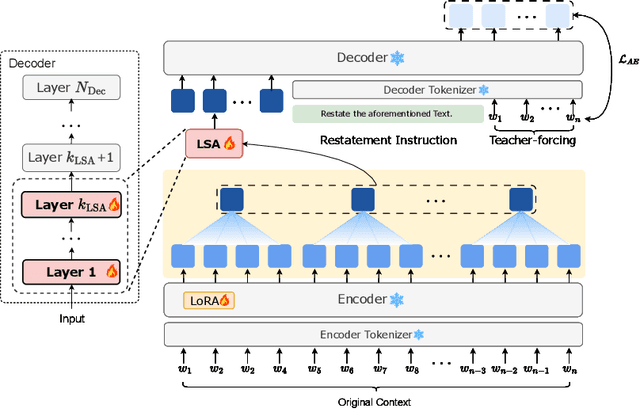

Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
From Token to Line: Enhancing Code Generation with a Long-Term Perspective
Apr 10, 2025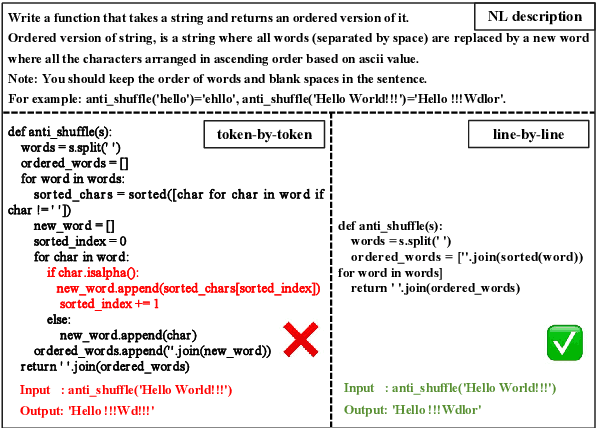
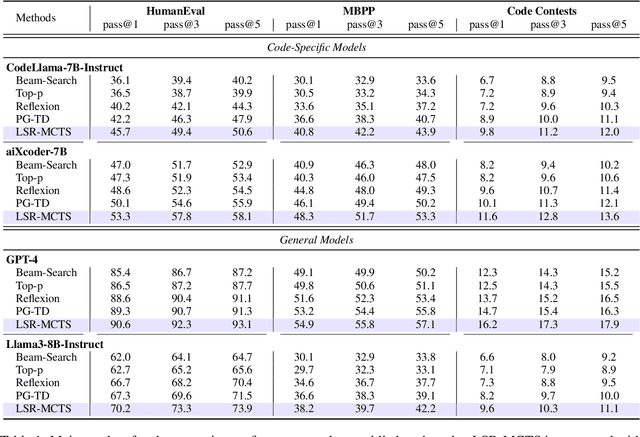
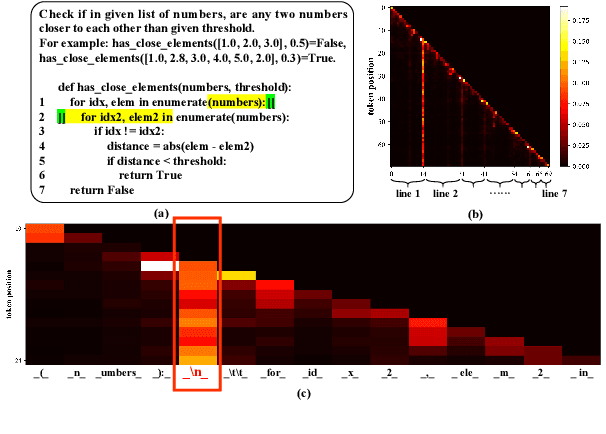
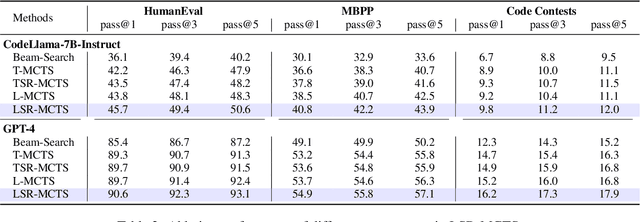
The emergence of large language models (LLMs) has significantly promoted the development of code generation task, sparking a surge in pertinent literature. Current research is hindered by redundant generation results and a tendency to overfit local patterns in the short term. Although existing studies attempt to alleviate the issue by adopting a multi-token prediction strategy, there remains limited focus on choosing the appropriate processing length for generations. By analyzing the attention between tokens during the generation process of LLMs, it can be observed that the high spikes of the attention scores typically appear at the end of lines. This insight suggests that it is reasonable to treat each line of code as a fundamental processing unit and generate them sequentially. Inspired by this, we propose the \textbf{LSR-MCTS} algorithm, which leverages MCTS to determine the code line-by-line and select the optimal path. Further, we integrate a self-refine mechanism at each node to enhance diversity and generate higher-quality programs through error correction. Extensive experiments and comprehensive analyses on three public coding benchmarks demonstrate that our method outperforms the state-of-the-art performance approaches.
Perception Compressor:A training-free prompt compression method in long context scenarios
Sep 28, 2024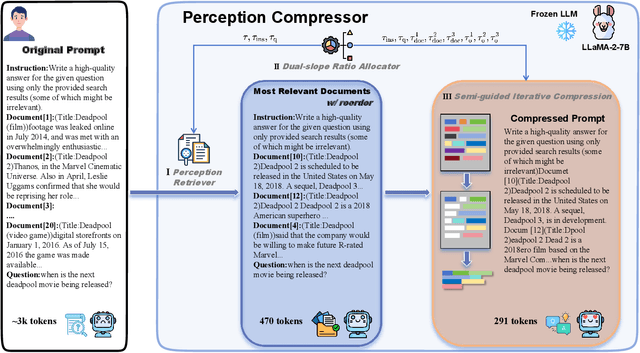
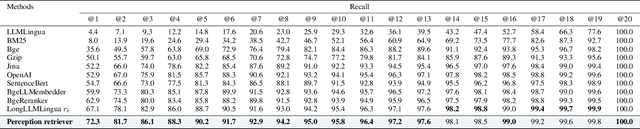
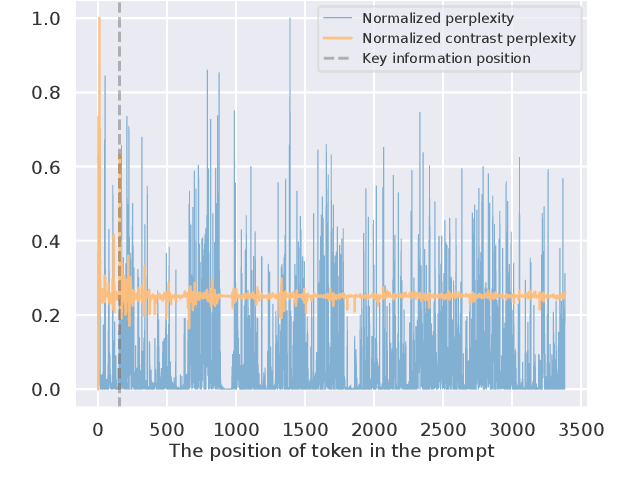
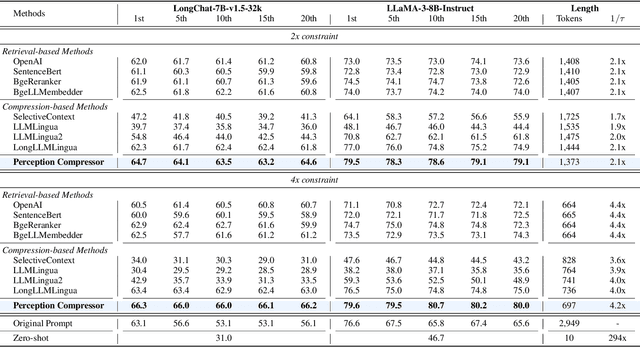
Large Language Models (LLMs) demonstrate exceptional capabilities in various scenarios. However, they suffer from much redundant information and tend to be lost in the middle in long context scenarios, leading to inferior performance. To address these challenges, we present Perception Compressor, a training-free prompt compression method. It includes a dual-slope ratio allocator to dynamically assign compression ratios and open-book ratios, a perception retriever that leverages guiding questions and instruction to retrieve the most relevant demonstrations, and a semi-guided iterative compression that retains key information at the token level while removing tokens that distract the LLM. We conduct extensive experiments on long context benchmarks, i.e., NaturalQuestions, LongBench, and MuSiQue. Experiment results show that Perception Compressor outperforms existing methods by a large margin, achieving state-of-the-art performance.
UltraWiki: Ultra-fine-grained Entity Set Expansion with Negative Seed Entities
Mar 07, 2024



Entity Set Expansion (ESE) aims to identify new entities belonging to the same semantic class as a given set of seed entities. Traditional methods primarily relied on positive seed entities to represent a target semantic class, which poses challenge for the representation of ultra-fine-grained semantic classes. Ultra-fine-grained semantic classes are defined based on fine-grained semantic classes with more specific attribute constraints. Describing it with positive seed entities alone cause two issues: (i) Ambiguity among ultra-fine-grained semantic classes. (ii) Inability to define "unwanted" semantic. Due to these inherent shortcomings, previous methods struggle to address the ultra-fine-grained ESE (Ultra-ESE). To solve this issue, we first introduce negative seed entities in the inputs, which belong to the same fine-grained semantic class as the positive seed entities but differ in certain attributes. Negative seed entities eliminate the semantic ambiguity by contrast between positive and negative attributes. Meanwhile, it provide a straightforward way to express "unwanted". To assess model performance in Ultra-ESE, we constructed UltraWiki, the first large-scale dataset tailored for Ultra-ESE. UltraWiki encompasses 236 ultra-fine-grained semantic classes, where each query of them is represented with 3-5 positive and negative seed entities. A retrieval-based framework RetExpan and a generation-based framework GenExpan are proposed to comprehensively assess the efficacy of large language models from two different paradigms in Ultra-ESE. Moreover, we devised three strategies to enhance models' comprehension of ultra-fine-grained entities semantics: contrastive learning, retrieval augmentation, and chain-of-thought reasoning. Extensive experiments confirm the effectiveness of our proposed strategies and also reveal that there remains a large space for improvement in Ultra-ESE.
MESED: A Multi-modal Entity Set Expansion Dataset with Fine-grained Semantic Classes and Hard Negative Entities
Jul 27, 2023The Entity Set Expansion (ESE) task aims to expand a handful of seed entities with new entities belonging to the same semantic class. Conventional ESE methods are based on mono-modality (i.e., literal modality), which struggle to deal with complex entities in the real world such as: (1) Negative entities with fine-grained semantic differences. (2) Synonymous entities. (3) Polysemous entities. (4) Long-tailed entities. These challenges prompt us to propose Multi-modal Entity Set Expansion (MESE), where models integrate information from multiple modalities to represent entities. Intuitively, the benefits of multi-modal information for ESE are threefold: (1) Different modalities can provide complementary information. (2) Multi-modal information provides a unified signal via common visual properties for the same semantic class or entity. (3) Multi-modal information offers robust alignment signal for synonymous entities. To assess the performance of model in MESE and facilitate further research, we constructed the MESED dataset which is the first multi-modal dataset for ESE with large-scale and elaborate manual calibration. A powerful multi-modal model MultiExpan is proposed which is pre-trained on four multimodal pre-training tasks. The extensive experiments and analyses on MESED demonstrate the high quality of the dataset and the effectiveness of our MultiExpan, as well as pointing the direction for future research.