 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025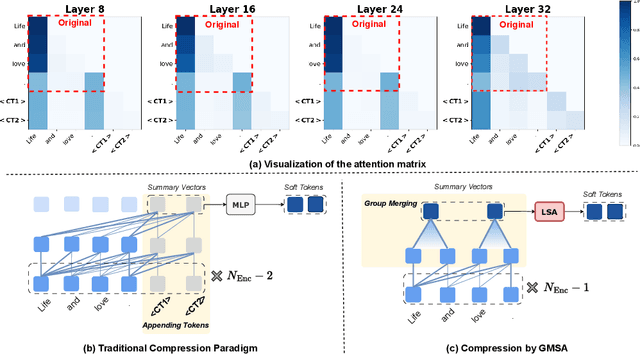
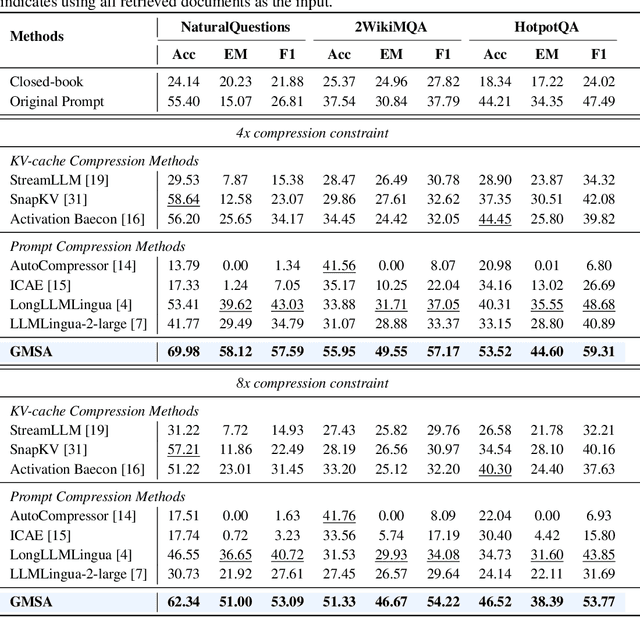
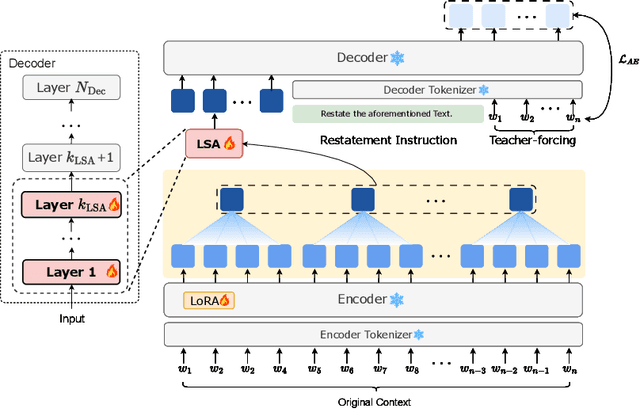

Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
Corrections Meet Explanations: A Unified Framework for Explainable Grammatical Error Correction
Feb 21, 2025Grammatical Error Correction (GEC) faces a critical challenge concerning explainability, notably when GEC systems are designed for language learners. Existing research predominantly focuses on explaining grammatical errors extracted in advance, thus neglecting the relationship between explanations and corrections. To address this gap, we introduce EXGEC, a unified explainable GEC framework that integrates explanation and correction tasks in a generative manner, advocating that these tasks mutually reinforce each other. Experiments have been conducted on EXPECT, a recent human-labeled dataset for explainable GEC, comprising around 20k samples. Moreover, we detect significant noise within EXPECT, potentially compromising model training and evaluation. Therefore, we introduce an alternative dataset named EXPECT-denoised, ensuring a more objective framework for training and evaluation. Results on various NLP models (BART, T5, and Llama3) show that EXGEC models surpass single-task baselines in both tasks, demonstrating the effectiveness of our approach.
Revisiting Classification Taxonomy for Grammatical Errors
Feb 18, 2025Grammatical error classification plays a crucial role in language learning systems, but existing classification taxonomies often lack rigorous validation, leading to inconsistencies and unreliable feedback. In this paper, we revisit previous classification taxonomies for grammatical errors by introducing a systematic and qualitative evaluation framework. Our approach examines four aspects of a taxonomy, i.e., exclusivity, coverage, balance, and usability. Then, we construct a high-quality grammatical error classification dataset annotated with multiple classification taxonomies and evaluate them grounding on our proposed evaluation framework. Our experiments reveal the drawbacks of existing taxonomies. Our contributions aim to improve the precision and effectiveness of error analysis, providing more understandable and actionable feedback for language learners.
EssayJudge: A Multi-Granular Benchmark for Assessing Automated Essay Scoring Capabilities of Multimodal Large Language Models
Feb 17, 2025Automated Essay Scoring (AES) plays a crucial role in educational assessment by providing scalable and consistent evaluations of writing tasks. However, traditional AES systems face three major challenges: (1) reliance on handcrafted features that limit generalizability, (2) difficulty in capturing fine-grained traits like coherence and argumentation, and (3) inability to handle multimodal contexts. In the era of Multimodal Large Language Models (MLLMs), we propose EssayJudge, the first multimodal benchmark to evaluate AES capabilities across lexical-, sentence-, and discourse-level traits. By leveraging MLLMs' strengths in trait-specific scoring and multimodal context understanding, EssayJudge aims to offer precise, context-rich evaluations without manual feature engineering, addressing longstanding AES limitations. Our experiments with 18 representative MLLMs reveal gaps in AES performance compared to human evaluation, particularly in discourse-level traits, highlighting the need for further advancements in MLLM-based AES research. Our dataset and code will be available upon acceptance.
Position: LLMs Can be Good Tutors in Foreign Language Education
Feb 08, 2025While recent efforts have begun integrating large language models (LLMs) into foreign language education (FLE), they often rely on traditional approaches to learning tasks without fully embracing educational methodologies, thus lacking adaptability to language learning. To address this gap, we argue that LLMs have the potential to serve as effective tutors in FLE. Specifically, LLMs can play three critical roles: (1) as data enhancers, improving the creation of learning materials or serving as student simulations; (2) as task predictors, serving as learner assessment or optimizing learning pathway; and (3) as agents, enabling personalized and inclusive education. We encourage interdisciplinary research to explore these roles, fostering innovation while addressing challenges and risks, ultimately advancing FLE through the thoughtful integration of LLMs.
Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning
Feb 05, 2025



Scientific reasoning, the process through which humans apply logic, evidence, and critical thinking to explore and interpret scientific phenomena, is essential in advancing knowledge reasoning across diverse fields. However, despite significant progress, current scientific reasoning models still struggle with generalization across domains and often fall short of multimodal perception. Multimodal Large Language Models (MLLMs), which integrate text, images, and other modalities, present an exciting opportunity to overcome these limitations and enhance scientific reasoning. Therefore, this position paper argues that MLLMs can significantly advance scientific reasoning across disciplines such as mathematics, physics, chemistry, and biology. First, we propose a four-stage research roadmap of scientific reasoning capabilities, and highlight the current state of MLLM applications in scientific reasoning, noting their ability to integrate and reason over diverse data types. Second, we summarize the key challenges that remain obstacles to achieving MLLM's full potential. To address these challenges, we propose actionable insights and suggestions for the future. Overall, our work offers a novel perspective on MLLM integration with scientific reasoning, providing the LLM community with a valuable vision for achieving Artificial General Intelligence (AGI).
Mind Scramble: Unveiling Large Language Model Psychology Via Typoglycemia
Oct 02, 2024



Research into the external behaviors and internal mechanisms of large language models (LLMs) has shown promise in addressing complex tasks in the physical world. Studies suggest that powerful LLMs, like GPT-4, are beginning to exhibit human-like cognitive abilities, including planning, reasoning, and reflection. In this paper, we introduce a research line and methodology called LLM Psychology, leveraging human psychology experiments to investigate the cognitive behaviors and mechanisms of LLMs. We migrate the Typoglycemia phenomenon from psychology to explore the "mind" of LLMs. Unlike human brains, which rely on context and word patterns to comprehend scrambled text, LLMs use distinct encoding and decoding processes. Through Typoglycemia experiments at the character, word, and sentence levels, we observe: (I) LLMs demonstrate human-like behaviors on a macro scale, such as lower task accuracy and higher token/time consumption; (II) LLMs exhibit varying robustness to scrambled input, making Typoglycemia a benchmark for model evaluation without new datasets; (III) Different task types have varying impacts, with complex logical tasks (e.g., math) being more challenging in scrambled form; (IV) Each LLM has a unique and consistent "cognitive pattern" across tasks, revealing general mechanisms in its psychology process. We provide an in-depth analysis of hidden layers to explain these phenomena, paving the way for future research in LLM Psychology and deeper interpretability.
CLEME2.0: Towards More Interpretable Evaluation by Disentangling Edits for Grammatical Error Correction
Jul 01, 2024The paper focuses on improving the interpretability of Grammatical Error Correction (GEC) metrics, which receives little attention in previous studies. To bridge the gap, we propose CLEME2.0, a reference-based evaluation strategy that can describe four elementary dimensions of GEC systems, namely hit-correction, error-correction, under-correction, and over-correction. They collectively contribute to revealing the critical characteristics and locating drawbacks of GEC systems. Evaluating systems by Combining these dimensions leads to high human consistency over other reference-based and reference-less metrics. Extensive experiments on 2 human judgement datasets and 6 reference datasets demonstrate the effectiveness and robustness of our method. All the codes will be released after the peer review.
EXCGEC: A Benchmark of Edit-wise Explainable Chinese Grammatical Error Correction
Jul 01, 2024



Existing studies explore the explainability of Grammatical Error Correction (GEC) in a limited scenario, where they ignore the interaction between corrections and explanations. To bridge the gap, this paper introduces the task of EXplainable GEC (EXGEC), which focuses on the integral role of both correction and explanation tasks. To facilitate the task, we propose EXCGEC, a tailored benchmark for Chinese EXGEC consisting of 8,216 explanation-augmented samples featuring the design of hybrid edit-wise explanations. We benchmark several series of LLMs in multiple settings, covering post-explaining and pre-explaining. To promote the development of the task, we introduce a comprehensive suite of automatic metrics and conduct human evaluation experiments to demonstrate the human consistency of the automatic metrics for free-text explanations. All the codes and data will be released after the review.
ProductAgent: Benchmarking Conversational Product Search Agent with Asking Clarification Questions
Jul 01, 2024
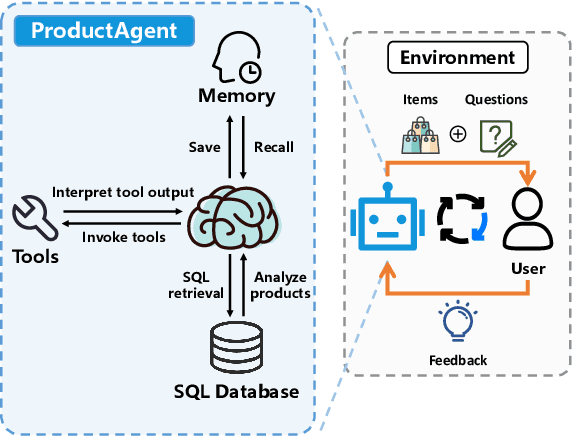
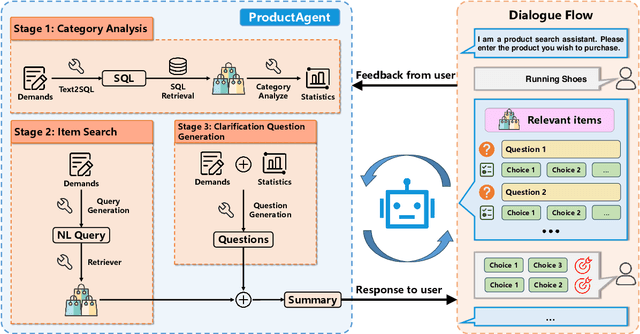

This paper introduces the task of product demand clarification within an e-commercial scenario, where the user commences the conversation with ambiguous queries and the task-oriented agent is designed to achieve more accurate and tailored product searching by asking clarification questions. To address this task, we propose ProductAgent, a conversational information seeking agent equipped with abilities of strategic clarification question generation and dynamic product retrieval. Specifically, we develop the agent with strategies for product feature summarization, query generation, and product retrieval. Furthermore, we propose the benchmark called PROCLARE to evaluate the agent's performance both automatically and qualitatively with the aid of a LLM-driven user simulator. Experiments show that ProductAgent interacts positively with the user and enhances retrieval performance with increasing dialogue turns, where user demands become gradually more explicit and detailed. All the source codes will be released after the review anonymity period.