 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025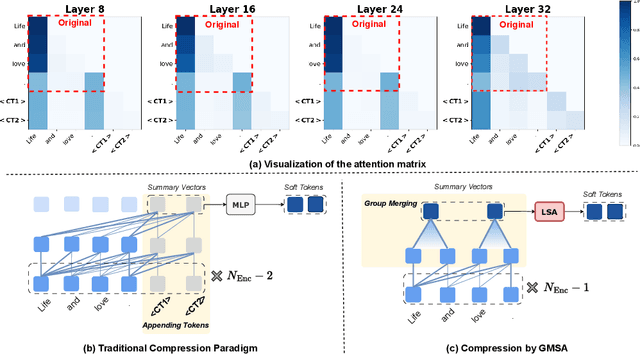
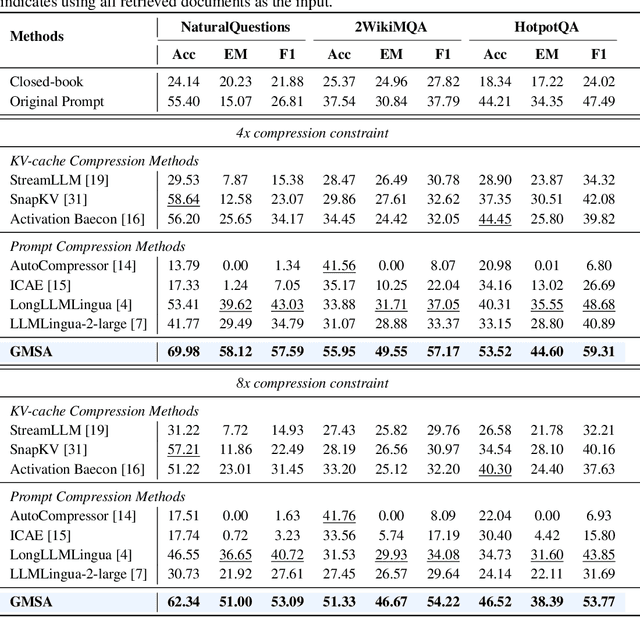
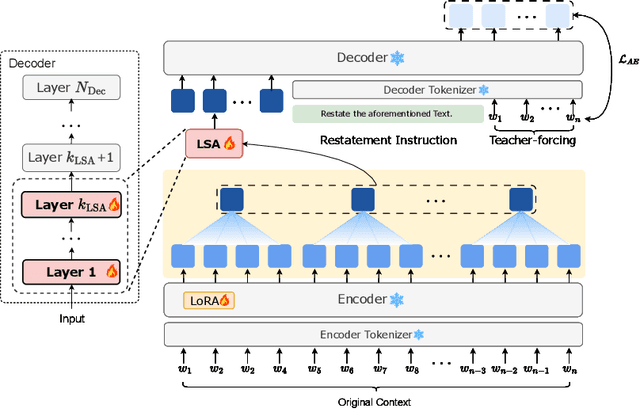

Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
OpenworldAUC: Towards Unified Evaluation and Optimization for Open-world Prompt Tuning
May 08, 2025Prompt tuning adapts Vision-Language Models like CLIP to open-world tasks with minimal training costs. In this direction, one typical paradigm evaluates model performance separately on known classes (i.e., base domain) and unseen classes (i.e., new domain). However, real-world scenarios require models to handle inputs without prior domain knowledge. This practical challenge has spurred the development of open-world prompt tuning, which demands a unified evaluation of two stages: 1) detecting whether an input belongs to the base or new domain (P1), and 2) classifying the sample into its correct class (P2). What's more, as domain distributions are generally unknown, a proper metric should be insensitive to varying base/new sample ratios (P3). However, we find that current metrics, including HM, overall accuracy, and AUROC, fail to satisfy these three properties simultaneously. To bridge this gap, we propose OpenworldAUC, a unified metric that jointly assesses detection and classification through pairwise instance comparisons. To optimize OpenworldAUC effectively, we introduce Gated Mixture-of-Prompts (GMoP), which employs domain-specific prompts and a gating mechanism to dynamically balance detection and classification. Theoretical guarantees ensure generalization of GMoP under practical conditions. Experiments on 15 benchmarks in open-world scenarios show GMoP achieves SOTA performance on OpenworldAUC and other metrics. We release the code at https://github.com/huacong/OpenworldAUC
ABKD: Pursuing a Proper Allocation of the Probability Mass in Knowledge Distillation via $α$-$β$-Divergence
May 07, 2025Knowledge Distillation (KD) transfers knowledge from a large teacher model to a smaller student model by minimizing the divergence between their output distributions, typically using forward Kullback-Leibler divergence (FKLD) or reverse KLD (RKLD). It has become an effective training paradigm due to the broader supervision information provided by the teacher distribution compared to one-hot labels. We identify that the core challenge in KD lies in balancing two mode-concentration effects: the \textbf{\textit{Hardness-Concentration}} effect, which refers to focusing on modes with large errors, and the \textbf{\textit{Confidence-Concentration}} effect, which refers to focusing on modes with high student confidence. Through an analysis of how probabilities are reassigned during gradient updates, we observe that these two effects are entangled in FKLD and RKLD, but in extreme forms. Specifically, both are too weak in FKLD, causing the student to fail to concentrate on the target class. In contrast, both are too strong in RKLD, causing the student to overly emphasize the target class while ignoring the broader distributional information from the teacher. To address this imbalance, we propose ABKD, a generic framework with $\alpha$-$\beta$-divergence. Our theoretical results show that ABKD offers a smooth interpolation between FKLD and RKLD, achieving an effective trade-off between these effects. Extensive experiments on 17 language/vision datasets with 12 teacher-student settings confirm its efficacy. The code is available at https://github.com/ghwang-s/abkd.
Focal-SAM: Focal Sharpness-Aware Minimization for Long-Tailed Classification
May 03, 2025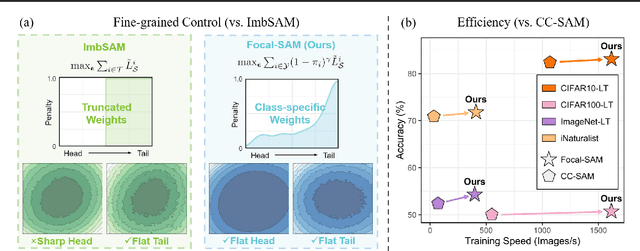

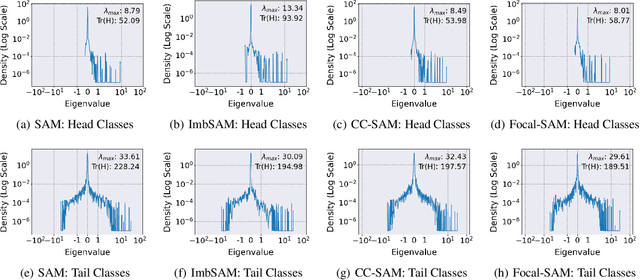
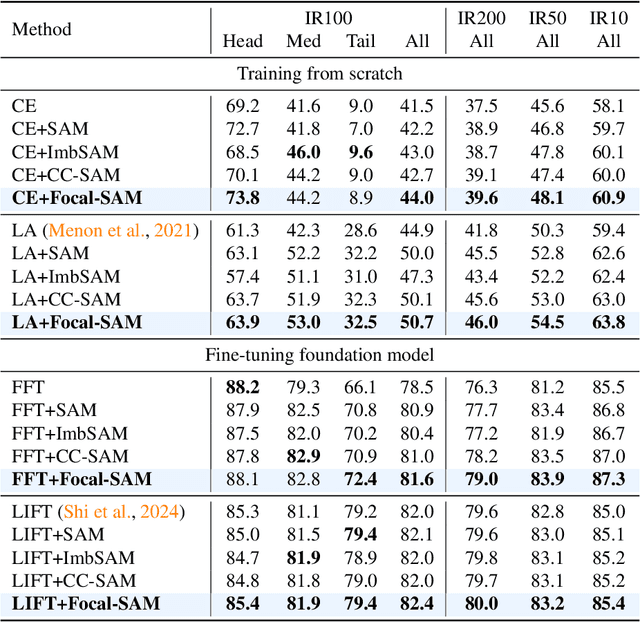
Real-world datasets often follow a long-tailed distribution, making generalization to tail classes difficult. Recent methods resorted to long-tail variants of Sharpness-Aware Minimization (SAM), such as ImbSAM and CC-SAM, to improve generalization by flattening the loss landscape. However, these attempts face a trade-off between computational efficiency and control over the loss landscape. On the one hand, ImbSAM is efficient but offers only coarse control as it excludes head classes from the SAM process. On the other hand, CC-SAM provides fine-grained control through class-dependent perturbations but at the cost of efficiency due to multiple backpropagations. Seeing this dilemma, we introduce Focal-SAM, which assigns different penalties to class-wise sharpness, achieving fine-grained control without extra backpropagations, thus maintaining efficiency. Furthermore, we theoretically analyze Focal-SAM's generalization ability and derive a sharper generalization bound. Extensive experiments on both traditional and foundation models validate the effectiveness of Focal-SAM.
EDGE: Unknown-aware Multi-label Learning by Energy Distribution Gap Expansion
Dec 10, 2024Multi-label Out-Of-Distribution (OOD) detection aims to discriminate the OOD samples from the multi-label In-Distribution (ID) ones. Compared with its multiclass counterpart, it is crucial to model the joint information among classes. To this end, JointEnergy, which is a representative multi-label OOD inference criterion, summarizes the logits of all the classes. However, we find that JointEnergy can produce an imbalance problem in OOD detection, especially when the model lacks enough discrimination ability. Specifically, we find that the samples only related to minority classes tend to be classified as OOD samples due to the ambiguous energy decision boundary. Besides, imbalanced multi-label learning methods, originally designed for ID ones, would not be suitable for OOD detection scenarios, even producing a serious negative transfer effect. In this paper, we resort to auxiliary outlier exposure (OE) and propose an unknown-aware multi-label learning framework to reshape the uncertainty energy space layout. In this framework, the energy score is separately optimized for tail ID samples and unknown samples, and the energy distribution gap between them is expanded, such that the tail ID samples can have a significantly larger energy score than the OOD ones. What's more, a simple yet effective measure is designed to select more informative OE datasets. Finally, comprehensive experimental results on multiple multi-label and OOD datasets reveal the effectiveness of the proposed method.
Suppress Content Shift: Better Diffusion Features via Off-the-Shelf Generation Techniques
Oct 10, 2024
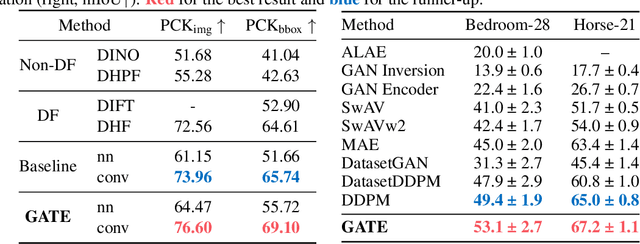


Diffusion models are powerful generative models, and this capability can also be applied to discrimination. The inner activations of a pre-trained diffusion model can serve as features for discriminative tasks, namely, diffusion feature. We discover that diffusion feature has been hindered by a hidden yet universal phenomenon that we call content shift. To be specific, there are content differences between features and the input image, such as the exact shape of a certain object. We locate the cause of content shift as one inherent characteristic of diffusion models, which suggests the broad existence of this phenomenon in diffusion feature. Further empirical study also indicates that its negative impact is not negligible even when content shift is not visually perceivable. Hence, we propose to suppress content shift to enhance the overall quality of diffusion features. Specifically, content shift is related to the information drift during the process of recovering an image from the noisy input, pointing out the possibility of turning off-the-shelf generation techniques into tools for content shift suppression. We further propose a practical guideline named GATE to efficiently evaluate the potential benefit of a technique and provide an implementation of our methodology. Despite the simplicity, the proposed approach has achieved superior results on various tasks and datasets, validating its potential as a generic booster for diffusion features. Our code is available at https://github.com/Darkbblue/diffusion-content-shift.
Not All Diffusion Model Activations Have Been Evaluated as Discriminative Features
Oct 04, 2024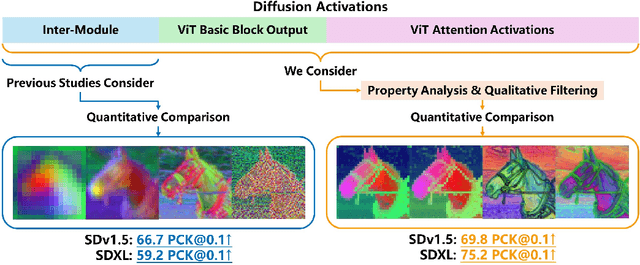

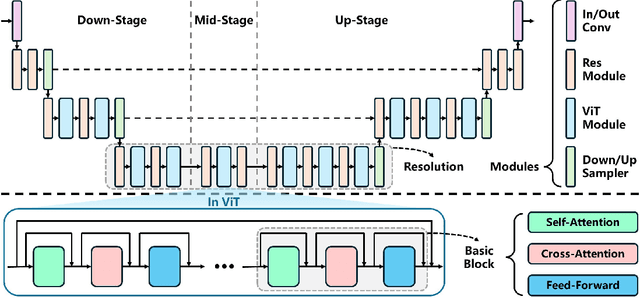

Diffusion models are initially designed for image generation. Recent research shows that the internal signals within their backbones, named activations, can also serve as dense features for various discriminative tasks such as semantic segmentation. Given numerous activations, selecting a small yet effective subset poses a fundamental problem. To this end, the early study of this field performs a large-scale quantitative comparison of the discriminative ability of the activations. However, we find that many potential activations have not been evaluated, such as the queries and keys used to compute attention scores. Moreover, recent advancements in diffusion architectures bring many new activations, such as those within embedded ViT modules. Both combined, activation selection remains unresolved but overlooked. To tackle this issue, this paper takes a further step with a much broader range of activations evaluated. Considering the significant increase in activations, a full-scale quantitative comparison is no longer operational. Instead, we seek to understand the properties of these activations, such that the activations that are clearly inferior can be filtered out in advance via simple qualitative evaluation. After careful analysis, we discover three properties universal among diffusion models, enabling this study to go beyond specific models. On top of this, we present effective feature selection solutions for several popular diffusion models. Finally, the experiments across multiple discriminative tasks validate the superiority of our method over the SOTA competitors. Our code is available at https://github.com/Darkbblue/generic-diffusion-feature.
HGOE: Hybrid External and Internal Graph Outlier Exposure for Graph Out-of-Distribution Detection
Jul 31, 2024With the progressive advancements in deep graph learning, out-of-distribution (OOD) detection for graph data has emerged as a critical challenge. While the efficacy of auxiliary datasets in enhancing OOD detection has been extensively studied for image and text data, such approaches have not yet been explored for graph data. Unlike Euclidean data, graph data exhibits greater diversity but lower robustness to perturbations, complicating the integration of outliers. To tackle these challenges, we propose the introduction of \textbf{H}ybrid External and Internal \textbf{G}raph \textbf{O}utlier \textbf{E}xposure (HGOE) to improve graph OOD detection performance. Our framework involves using realistic external graph data from various domains and synthesizing internal outliers within ID subgroups to address the poor robustness and presence of OOD samples within the ID class. Furthermore, we develop a boundary-aware OE loss that adaptively assigns weights to outliers, maximizing the use of high-quality OOD samples while minimizing the impact of low-quality ones. Our proposed HGOE framework is model-agnostic and designed to enhance the effectiveness of existing graph OOD detection models. Experimental results demonstrate that our HGOE framework can significantly improve the performance of existing OOD detection models across all 8 real datasets.
Top-K Pairwise Ranking: Bridging the Gap Among Ranking-Based Measures for Multi-Label Classification
Jul 09, 2024Multi-label ranking, which returns multiple top-ranked labels for each instance, has a wide range of applications for visual tasks. Due to its complicated setting, prior arts have proposed various measures to evaluate model performances. However, both theoretical analysis and empirical observations show that a model might perform inconsistently on different measures. To bridge this gap, this paper proposes a novel measure named Top-K Pairwise Ranking (TKPR), and a series of analyses show that TKPR is compatible with existing ranking-based measures. In light of this, we further establish an empirical surrogate risk minimization framework for TKPR. On one hand, the proposed framework enjoys convex surrogate losses with the theoretical support of Fisher consistency. On the other hand, we establish a sharp generalization bound for the proposed framework based on a novel technique named data-dependent contraction. Finally, empirical results on benchmark datasets validate the effectiveness of the proposed framework.
Harnessing Hierarchical Label Distribution Variations in Test Agnostic Long-tail Recognition
May 13, 2024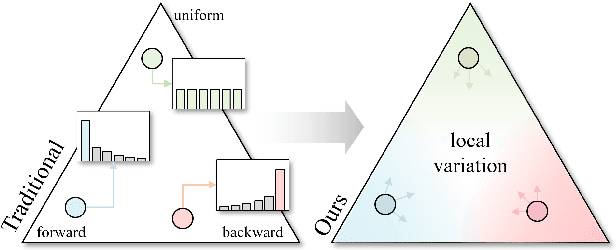

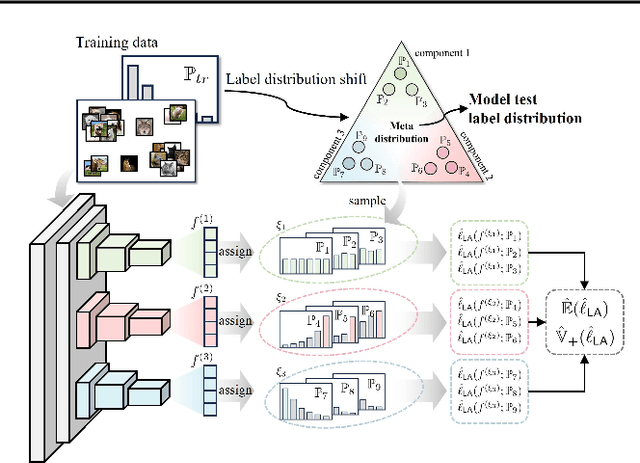
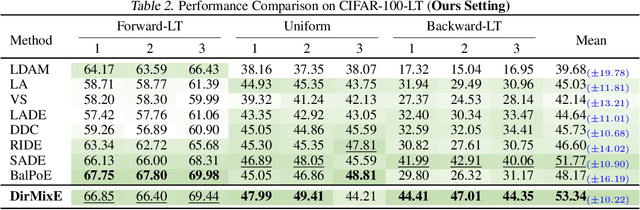
This paper explores test-agnostic long-tail recognition, a challenging long-tail task where the test label distributions are unknown and arbitrarily imbalanced. We argue that the variation in these distributions can be broken down hierarchically into global and local levels. The global ones reflect a broad range of diversity, while the local ones typically arise from milder changes, often focused on a particular neighbor. Traditional methods predominantly use a Mixture-of-Expert (MoE) approach, targeting a few fixed test label distributions that exhibit substantial global variations. However, the local variations are left unconsidered. To address this issue, we propose a new MoE strategy, $\mathsf{DirMixE}$, which assigns experts to different Dirichlet meta-distributions of the label distribution, each targeting a specific aspect of local variations. Additionally, the diversity among these Dirichlet meta-distributions inherently captures global variations. This dual-level approach also leads to a more stable objective function, allowing us to sample different test distributions better to quantify the mean and variance of performance outcomes. Theoretically, we show that our proposed objective benefits from enhanced generalization by virtue of the variance-based regularization. Comprehensive experiments across multiple benchmarks confirm the effectiveness of $\mathsf{DirMixE}$. The code is available at \url{https://github.com/scongl/DirMixE}.