 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Diffusion-based Reconstruction with Contrastive Signals for Balanced Visual Representation
Mar 05, 2026The limited understanding capacity of the visual encoder in Contrastive Language-Image Pre-training (CLIP) has become a key bottleneck for downstream performance. This capacity includes both Discriminative Ability (D-Ability), which reflects class separability, and Detail Perceptual Ability (P-Ability), which focuses on fine-grained visual cues. Recent solutions use diffusion models to enhance representations by conditioning image reconstruction on CLIP visual tokens. We argue that such paradigms may compromise D-Ability and therefore fail to effectively address CLIP's representation limitations. To address this, we integrate contrastive signals into diffusion-based reconstruction to pursue more comprehensive visual representations. We begin with a straightforward design that augments the diffusion process with contrastive learning on input images. However, empirical results show that the naive combination suffers from gradient conflict and yields suboptimal performance. To balance the optimization, we introduce the Diffusion Contrastive Reconstruction (DCR), which unifies the learning objective. The key idea is to inject contrastive signals derived from each reconstructed image, rather than from the original input, into the diffusion process. Our theoretical analysis shows that the DCR loss can jointly optimize D-Ability and P-Ability. Extensive experiments across various benchmarks and multi-modal large language models validate the effectiveness of our method. The code is available at https://github.com/boyuh/DCR.
Towards Size-invariant Salient Object Detection: A Generic Evaluation and Optimization Approach
Sep 19, 2025This paper investigates a fundamental yet underexplored issue in Salient Object Detection (SOD): the size-invariant property for evaluation protocols, particularly in scenarios when multiple salient objects of significantly different sizes appear within a single image. We first present a novel perspective to expose the inherent size sensitivity of existing widely used SOD metrics. Through careful theoretical derivations, we show that the evaluation outcome of an image under current SOD metrics can be essentially decomposed into a sum of several separable terms, with the contribution of each term being directly proportional to its corresponding region size. Consequently, the prediction errors would be dominated by the larger regions, while smaller yet potentially more semantically important objects are often overlooked, leading to biased performance assessments and practical degradation. To address this challenge, a generic Size-Invariant Evaluation (SIEva) framework is proposed. The core idea is to evaluate each separable component individually and then aggregate the results, thereby effectively mitigating the impact of size imbalance across objects. Building upon this, we further develop a dedicated optimization framework (SIOpt), which adheres to the size-invariant principle and significantly enhances the detection of salient objects across a broad range of sizes. Notably, SIOpt is model-agnostic and can be seamlessly integrated with a wide range of SOD backbones. Theoretically, we also present generalization analysis of SOD methods and provide evidence supporting the validity of our new evaluation protocols. Finally, comprehensive experiments speak to the efficacy of our proposed approach. The code is available at https://github.com/Ferry-Li/SI-SOD.
Dual-Stage Reweighted MoE for Long-Tailed Egocentric Mistake Detection
Sep 16, 2025In this report, we address the problem of determining whether a user performs an action incorrectly from egocentric video data. To handle the challenges posed by subtle and infrequent mistakes, we propose a Dual-Stage Reweighted Mixture-of-Experts (DR-MoE) framework. In the first stage, features are extracted using a frozen ViViT model and a LoRA-tuned ViViT model, which are combined through a feature-level expert module. In the second stage, three classifiers are trained with different objectives: reweighted cross-entropy to mitigate class imbalance, AUC loss to improve ranking under skewed distributions, and label-aware loss with sharpness-aware minimization to enhance calibration and generalization. Their predictions are fused using a classification-level expert module. The proposed method achieves strong performance, particularly in identifying rare and ambiguous mistake instances. The code is available at https://github.com/boyuh/DR-MoE.
One Image is Worth a Thousand Words: A Usability Preservable Text-Image Collaborative Erasing Framework
May 16, 2025Concept erasing has recently emerged as an effective paradigm to prevent text-to-image diffusion models from generating visually undesirable or even harmful content. However, current removal methods heavily rely on manually crafted text prompts, making it challenging to achieve a high erasure (efficacy) while minimizing the impact on other benign concepts (usability). In this paper, we attribute the limitations to the inherent gap between the text and image modalities, which makes it hard to transfer the intricately entangled concept knowledge from text prompts to the image generation process. To address this, we propose a novel solution by directly integrating visual supervision into the erasure process, introducing the first text-image Collaborative Concept Erasing (Co-Erasing) framework. Specifically, Co-Erasing describes the concept jointly by text prompts and the corresponding undesirable images induced by the prompts, and then reduces the generating probability of the target concept through negative guidance. This approach effectively bypasses the knowledge gap between text and image, significantly enhancing erasure efficacy. Additionally, we design a text-guided image concept refinement strategy that directs the model to focus on visual features most relevant to the specified text concept, minimizing disruption to other benign concepts. Finally, comprehensive experiments suggest that Co-Erasing outperforms state-of-the-art erasure approaches significantly with a better trade-off between efficacy and usability. Codes are available at https://github.com/Ferry-Li/Co-Erasing.
MixBridge: Heterogeneous Image-to-Image Backdoor Attack through Mixture of Schrödinger Bridges
May 12, 2025This paper focuses on implanting multiple heterogeneous backdoor triggers in bridge-based diffusion models designed for complex and arbitrary input distributions. Existing backdoor formulations mainly address single-attack scenarios and are limited to Gaussian noise input models. To fill this gap, we propose MixBridge, a novel diffusion Schr\"odinger bridge (DSB) framework to cater to arbitrary input distributions (taking I2I tasks as special cases). Beyond this trait, we demonstrate that backdoor triggers can be injected into MixBridge by directly training with poisoned image pairs. This eliminates the need for the cumbersome modifications to stochastic differential equations required in previous studies, providing a flexible tool to study backdoor behavior for bridge models. However, a key question arises: can a single DSB model train multiple backdoor triggers? Unfortunately, our theory shows that when attempting this, the model ends up following the geometric mean of benign and backdoored distributions, leading to performance conflict across backdoor tasks. To overcome this, we propose a Divide-and-Merge strategy to mix different bridges, where models are independently pre-trained for each specific objective (Divide) and then integrated into a unified model (Merge). In addition, a Weight Reallocation Scheme (WRS) is also designed to enhance the stealthiness of MixBridge. Empirical studies across diverse generation tasks speak to the efficacy of MixBridge.
OpenworldAUC: Towards Unified Evaluation and Optimization for Open-world Prompt Tuning
May 08, 2025Prompt tuning adapts Vision-Language Models like CLIP to open-world tasks with minimal training costs. In this direction, one typical paradigm evaluates model performance separately on known classes (i.e., base domain) and unseen classes (i.e., new domain). However, real-world scenarios require models to handle inputs without prior domain knowledge. This practical challenge has spurred the development of open-world prompt tuning, which demands a unified evaluation of two stages: 1) detecting whether an input belongs to the base or new domain (P1), and 2) classifying the sample into its correct class (P2). What's more, as domain distributions are generally unknown, a proper metric should be insensitive to varying base/new sample ratios (P3). However, we find that current metrics, including HM, overall accuracy, and AUROC, fail to satisfy these three properties simultaneously. To bridge this gap, we propose OpenworldAUC, a unified metric that jointly assesses detection and classification through pairwise instance comparisons. To optimize OpenworldAUC effectively, we introduce Gated Mixture-of-Prompts (GMoP), which employs domain-specific prompts and a gating mechanism to dynamically balance detection and classification. Theoretical guarantees ensure generalization of GMoP under practical conditions. Experiments on 15 benchmarks in open-world scenarios show GMoP achieves SOTA performance on OpenworldAUC and other metrics. We release the code at https://github.com/huacong/OpenworldAUC
Bidirectional Logits Tree: Pursuing Granularity Reconcilement in Fine-Grained Classification
Dec 17, 2024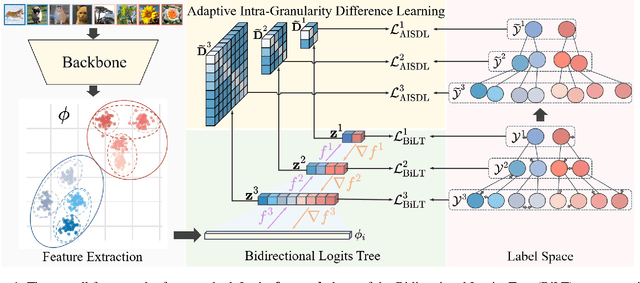
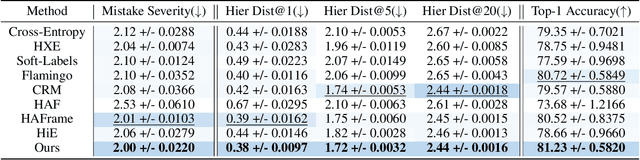
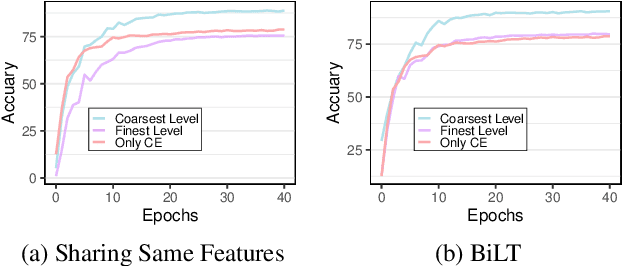

This paper addresses the challenge of Granularity Competition in fine-grained classification tasks, which arises due to the semantic gap between multi-granularity labels. Existing approaches typically develop independent hierarchy-aware models based on shared features extracted from a common base encoder. However, because coarse-grained levels are inherently easier to learn than finer ones, the base encoder tends to prioritize coarse feature abstractions, which impedes the learning of fine-grained features. To overcome this challenge, we propose a novel framework called the Bidirectional Logits Tree (BiLT) for Granularity Reconcilement. The key idea is to develop classifiers sequentially from the finest to the coarsest granularities, rather than parallelly constructing a set of classifiers based on the same input features. In this setup, the outputs of finer-grained classifiers serve as inputs for coarser-grained ones, facilitating the flow of hierarchical semantic information across different granularities. On top of this, we further introduce an Adaptive Intra-Granularity Difference Learning (AIGDL) approach to uncover subtle semantic differences between classes within the same granularity. Extensive experiments demonstrate the effectiveness of our proposed method.
AUCSeg: AUC-oriented Pixel-level Long-tail Semantic Segmentation
Sep 30, 2024



The Area Under the ROC Curve (AUC) is a well-known metric for evaluating instance-level long-tail learning problems. In the past two decades, many AUC optimization methods have been proposed to improve model performance under long-tail distributions. In this paper, we explore AUC optimization methods in the context of pixel-level long-tail semantic segmentation, a much more complicated scenario. This task introduces two major challenges for AUC optimization techniques. On one hand, AUC optimization in a pixel-level task involves complex coupling across loss terms, with structured inner-image and pairwise inter-image dependencies, complicating theoretical analysis. On the other hand, we find that mini-batch estimation of AUC loss in this case requires a larger batch size, resulting in an unaffordable space complexity. To address these issues, we develop a pixel-level AUC loss function and conduct a dependency-graph-based theoretical analysis of the algorithm's generalization ability. Additionally, we design a Tail-Classes Memory Bank (T-Memory Bank) to manage the significant memory demand. Finally, comprehensive experiments across various benchmarks confirm the effectiveness of our proposed AUCSeg method. The code is available at https://github.com/boyuh/AUCSeg.
Improved Diversity-Promoting Collaborative Metric Learning for Recommendation
Sep 02, 2024



Collaborative Metric Learning (CML) has recently emerged as a popular method in recommendation systems (RS), closing the gap between metric learning and collaborative filtering. Following the convention of RS, existing practices exploit unique user representation in their model design. This paper focuses on a challenging scenario where a user has multiple categories of interests. Under this setting, the unique user representation might induce preference bias, especially when the item category distribution is imbalanced. To address this issue, we propose a novel method called \textit{Diversity-Promoting Collaborative Metric Learning} (DPCML), with the hope of considering the commonly ignored minority interest of the user. The key idea behind DPCML is to introduce a set of multiple representations for each user in the system where users' preference toward an item is aggregated by taking the minimum item-user distance among their embedding set. Specifically, we instantiate two effective assignment strategies to explore a proper quantity of vectors for each user. Meanwhile, a \textit{Diversity Control Regularization Scheme} (DCRS) is developed to accommodate the multi-vector representation strategy better. Theoretically, we show that DPCML could induce a smaller generalization error than traditional CML. Furthermore, we notice that CML-based approaches usually require \textit{negative sampling} to reduce the heavy computational burden caused by the pairwise objective therein. In this paper, we reveal the fundamental limitation of the widely adopted hard-aware sampling from the One-Way Partial AUC (OPAUC) perspective and then develop an effective sampling alternative for the CML-based paradigm. Finally, comprehensive experiments over a range of benchmark datasets speak to the efficacy of DPCML. Code are available at \url{https://github.com/statusrank/LibCML}.
Size-invariance Matters: Rethinking Metrics and Losses for Imbalanced Multi-object Salient Object Detection
May 16, 2024



This paper explores the size-invariance of evaluation metrics in Salient Object Detection (SOD), especially when multiple targets of diverse sizes co-exist in the same image. We observe that current metrics are size-sensitive, where larger objects are focused, and smaller ones tend to be ignored. We argue that the evaluation should be size-invariant because bias based on size is unjustified without additional semantic information. In pursuit of this, we propose a generic approach that evaluates each salient object separately and then combines the results, effectively alleviating the imbalance. We further develop an optimization framework tailored to this goal, achieving considerable improvements in detecting objects of different sizes. Theoretically, we provide evidence supporting the validity of our new metrics and present the generalization analysis of SOD. Extensive experiments demonstrate the effectiveness of our method. The code is available at https://github.com/Ferry-Li/SI-SOD.