 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Static to Dynamic: Exploring Self-supervised Image-to-Video Representation Transfer Learning
Mar 27, 2026Recent studies have made notable progress in video representation learning by transferring image-pretrained models to video tasks, typically with complex temporal modules and video fine-tuning. However, fine-tuning heavy modules may compromise inter-video semantic separability, i.e., the essential ability to distinguish objects across videos. While reducing the tunable parameters hinders their intra-video temporal consistency, which is required for stable representations of the same object within a video. This dilemma indicates a potential trade-off between the intra-video temporal consistency and inter-video semantic separability during image-to-video transfer. To this end, we propose the Consistency-Separability Trade-off Transfer Learning (Co-Settle) framework, which applies a lightweight projection layer on top of the frozen image-pretrained encoder to adjust representation space with a temporal cycle consistency objective and a semantic separability constraint. We further provide a theoretical support showing that the optimized projection yields a better trade-off between the two properties under appropriate conditions. Experiments on eight image-pretrained models demonstrate consistent improvements across multiple levels of video tasks with only five epochs of self-supervised training. The code is available at https://github.com/yafeng19/Co-Settle.
HiGFA: Hierarchical Guidance for Fine-grained Data Augmentation with Diffusion Models
Nov 16, 2025Generative diffusion models show promise for data augmentation. However, applying them to fine-grained tasks presents a significant challenge: ensuring synthetic images accurately capture the subtle, category-defining features critical for high fidelity. Standard approaches, such as text-based Classifier-Free Guidance (CFG), often lack the required specificity, potentially generating misleading examples that degrade fine-grained classifier performance. To address this, we propose Hierarchically Guided Fine-grained Augmentation (HiGFA). HiGFA leverages the temporal dynamics of the diffusion sampling process. It employs strong text and transformed contour guidance with fixed strengths in the early-to-mid sampling stages to establish overall scene, style, and structure. In the final sampling stages, HiGFA activates a specialized fine-grained classifier guidance and dynamically modulates the strength of all guidance signals based on prediction confidence. This hierarchical, confidence-driven orchestration enables HiGFA to generate diverse yet faithful synthetic images by intelligently balancing global structure formation with precise detail refinement. Experiments on several FGVC datasets demonstrate the effectiveness of HiGFA.
TuckA: Hierarchical Compact Tensor Experts for Efficient Fine-Tuning
Nov 10, 2025Efficiently fine-tuning pre-trained models for downstream tasks is a key challenge in the era of foundation models. Parameter-efficient fine-tuning (PEFT) presents a promising solution, achieving performance comparable to full fine-tuning by updating only a small number of adaptation weights per layer. Traditional PEFT methods typically rely on a single expert, where the adaptation weight is a low-rank matrix. However, for complex tasks, the data's inherent diversity poses a significant challenge for such models, as a single adaptation weight cannot adequately capture the features of all samples. To address this limitation, we explore how to integrate multiple small adaptation experts into a compact structure to defeat a large adapter. Specifically, we propose Tucker Adaptation (TuckA), a method with four key properties: (i) We use Tucker decomposition to create a compact 3D tensor where each slice naturally serves as an expert. The low-rank nature of this decomposition ensures that the number of parameters scales efficiently as more experts are added. (ii) We introduce a hierarchical strategy that organizes these experts into groups at different granularities, allowing the model to capture both local and global data patterns. (iii) We develop an efficient batch-level routing mechanism, which reduces the router's parameter size by a factor of $L$ compared to routing at every adapted layer (where $L$ is the number of adapted layers) (iv) We propose data-aware initialization to achieve loss-free expert load balancing based on theoretical analysis. Extensive experiments on benchmarks in natural language understanding, image classification, and mathematical reasoning speak to the efficacy of TuckA, offering a new and effective solution to the PEFT problem.
Semantic Concentration for Self-Supervised Dense Representations Learning
Sep 11, 2025Recent advances in image-level self-supervised learning (SSL) have made significant progress, yet learning dense representations for patches remains challenging. Mainstream methods encounter an over-dispersion phenomenon that patches from the same instance/category scatter, harming downstream performance on dense tasks. This work reveals that image-level SSL avoids over-dispersion by involving implicit semantic concentration. Specifically, the non-strict spatial alignment ensures intra-instance consistency, while shared patterns, i.e., similar parts of within-class instances in the input space, ensure inter-image consistency. Unfortunately, these approaches are infeasible for dense SSL due to their spatial sensitivity and complicated scene-centric data. These observations motivate us to explore explicit semantic concentration for dense SSL. First, to break the strict spatial alignment, we propose to distill the patch correspondences. Facing noisy and imbalanced pseudo labels, we propose a noise-tolerant ranking loss. The core idea is extending the Average Precision (AP) loss to continuous targets, such that its decision-agnostic and adaptive focusing properties prevent the student model from being misled. Second, to discriminate the shared patterns from complicated scenes, we propose the object-aware filter to map the output space to an object-based space. Specifically, patches are represented by learnable prototypes of objects via cross-attention. Last but not least, empirical studies across various tasks soundly support the effectiveness of our method. Code is available in https://github.com/KID-7391/CoTAP.
Learn Faster and Remember More: Balancing Exploration and Exploitation for Continual Test-time Adaptation
Aug 18, 2025Continual Test-Time Adaptation (CTTA) aims to adapt a source pre-trained model to continually changing target domains during inference. As a fundamental principle, an ideal CTTA method should rapidly adapt to new domains (exploration) while retaining and exploiting knowledge from previously encountered domains to handle similar domains in the future. Despite significant advances, balancing exploration and exploitation in CTTA is still challenging: 1) Existing methods focus on adjusting predictions based on deep-layer outputs of neural networks. However, domain shifts typically affect shallow features, which are inefficient to be adjusted from deep predictions, leading to dilatory exploration; 2) A single model inevitably forgets knowledge of previous domains during the exploration, making it incapable of exploiting historical knowledge to handle similar future domains. To address these challenges, this paper proposes a mean teacher framework that strikes an appropriate Balance between Exploration and Exploitation (BEE) during the CTTA process. For the former challenge, we introduce a Multi-level Consistency Regularization (MCR) loss that aligns the intermediate features of the student and teacher models, accelerating adaptation to the current domain. For the latter challenge, we employ a Complementary Anchor Replay (CAR) mechanism to reuse historical checkpoints (anchors), recovering complementary knowledge for diverse domains. Experiments show that our method significantly outperforms state-of-the-art methods on several benchmarks, demonstrating its effectiveness for CTTA tasks.
Exploring Non-contrastive Self-supervised Representation Learning for Image-based Profiling
Jun 17, 2025Image-based cell profiling aims to create informative representations of cell images. This technique is critical in drug discovery and has greatly advanced with recent improvements in computer vision. Inspired by recent developments in non-contrastive Self-Supervised Learning (SSL), this paper provides an initial exploration into training a generalizable feature extractor for cell images using such methods. However, there are two major challenges: 1) There is a large difference between the distributions of cell images and natural images, causing the view-generation process in existing SSL methods to fail; and 2) Unlike typical scenarios where each representation is based on a single image, cell profiling often involves multiple input images, making it difficult to effectively combine all available information. To overcome these challenges, we propose SSLProfiler, a non-contrastive SSL framework specifically designed for cell profiling. We introduce specialized data augmentation and representation post-processing methods tailored to cell images, which effectively address the issues mentioned above and result in a robust feature extractor. With these improvements, SSLProfiler won the Cell Line Transferability challenge at CVPR 2025.
When the Future Becomes the Past: Taming Temporal Correspondence for Self-supervised Video Representation Learning
Mar 19, 2025The past decade has witnessed notable achievements in self-supervised learning for video tasks. Recent efforts typically adopt the Masked Video Modeling (MVM) paradigm, leading to significant progress on multiple video tasks. However, two critical challenges remain: 1) Without human annotations, the random temporal sampling introduces uncertainty, increasing the difficulty of model training. 2) Previous MVM methods primarily recover the masked patches in the pixel space, leading to insufficient information compression for downstream tasks. To address these challenges jointly, we propose a self-supervised framework that leverages Temporal Correspondence for video Representation learning (T-CoRe). For challenge 1), we propose a sandwich sampling strategy that selects two auxiliary frames to reduce reconstruction uncertainty in a two-side-squeezing manner. Addressing challenge 2), we introduce an auxiliary branch into a self-distillation architecture to restore representations in the latent space, generating high-level semantic representations enriched with temporal information. Experiments of T-CoRe consistently present superior performance across several downstream tasks, demonstrating its effectiveness for video representation learning. The code is available at https://github.com/yafeng19/T-CORE.
AUCSeg: AUC-oriented Pixel-level Long-tail Semantic Segmentation
Sep 30, 2024



The Area Under the ROC Curve (AUC) is a well-known metric for evaluating instance-level long-tail learning problems. In the past two decades, many AUC optimization methods have been proposed to improve model performance under long-tail distributions. In this paper, we explore AUC optimization methods in the context of pixel-level long-tail semantic segmentation, a much more complicated scenario. This task introduces two major challenges for AUC optimization techniques. On one hand, AUC optimization in a pixel-level task involves complex coupling across loss terms, with structured inner-image and pairwise inter-image dependencies, complicating theoretical analysis. On the other hand, we find that mini-batch estimation of AUC loss in this case requires a larger batch size, resulting in an unaffordable space complexity. To address these issues, we develop a pixel-level AUC loss function and conduct a dependency-graph-based theoretical analysis of the algorithm's generalization ability. Additionally, we design a Tail-Classes Memory Bank (T-Memory Bank) to manage the significant memory demand. Finally, comprehensive experiments across various benchmarks confirm the effectiveness of our proposed AUCSeg method. The code is available at https://github.com/boyuh/AUCSeg.
Not All Pairs are Equal: Hierarchical Learning for Average-Precision-Oriented Video Retrieval
Jul 22, 2024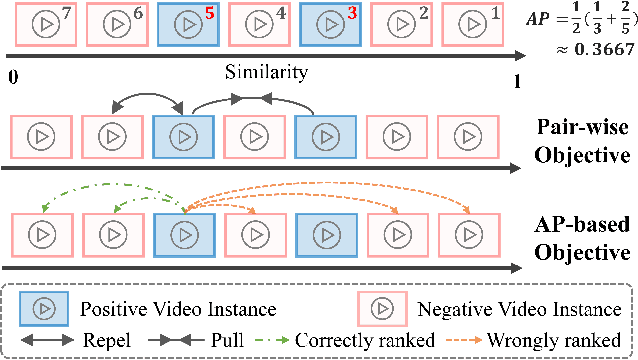
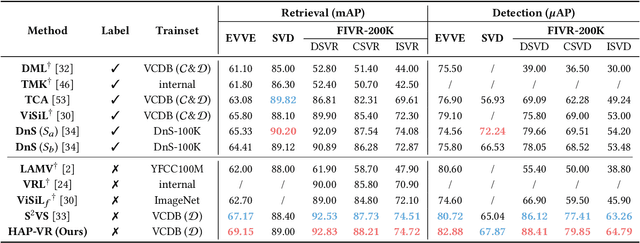
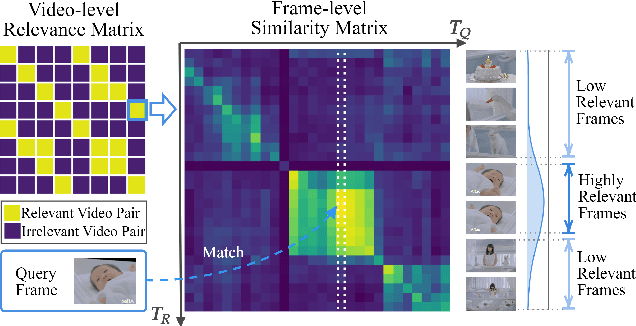
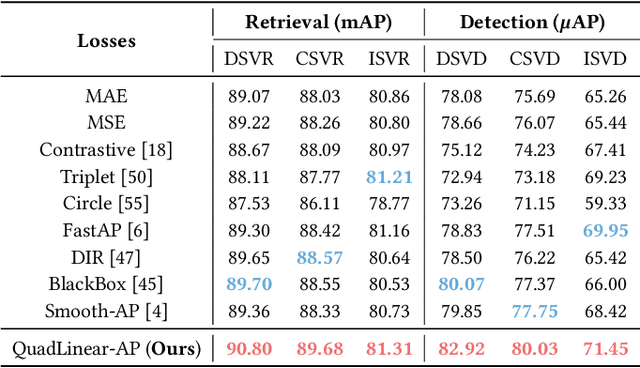
The rapid growth of online video resources has significantly promoted the development of video retrieval methods. As a standard evaluation metric for video retrieval, Average Precision (AP) assesses the overall rankings of relevant videos at the top list, making the predicted scores a reliable reference for users. However, recent video retrieval methods utilize pair-wise losses that treat all sample pairs equally, leading to an evident gap between the training objective and evaluation metric. To effectively bridge this gap, in this work, we aim to address two primary challenges: a) The current similarity measure and AP-based loss are suboptimal for video retrieval; b) The noticeable noise from frame-to-frame matching introduces ambiguity in estimating the AP loss. In response to these challenges, we propose the Hierarchical learning framework for Average-Precision-oriented Video Retrieval (HAP-VR). For the former challenge, we develop the TopK-Chamfer Similarity and QuadLinear-AP loss to measure and optimize video-level similarities in terms of AP. For the latter challenge, we suggest constraining the frame-level similarities to achieve an accurate AP loss estimation. Experimental results present that HAP-VR outperforms existing methods on several benchmark datasets, providing a feasible solution for video retrieval tasks and thus offering potential benefits for the multi-media application.
Top-K Pairwise Ranking: Bridging the Gap Among Ranking-Based Measures for Multi-Label Classification
Jul 09, 2024Multi-label ranking, which returns multiple top-ranked labels for each instance, has a wide range of applications for visual tasks. Due to its complicated setting, prior arts have proposed various measures to evaluate model performances. However, both theoretical analysis and empirical observations show that a model might perform inconsistently on different measures. To bridge this gap, this paper proposes a novel measure named Top-K Pairwise Ranking (TKPR), and a series of analyses show that TKPR is compatible with existing ranking-based measures. In light of this, we further establish an empirical surrogate risk minimization framework for TKPR. On one hand, the proposed framework enjoys convex surrogate losses with the theoretical support of Fisher consistency. On the other hand, we establish a sharp generalization bound for the proposed framework based on a novel technique named data-dependent contraction. Finally, empirical results on benchmark datasets validate the effectiveness of the proposed framework.