 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD-CAP: Fractional Subgraph Diffusion with Class-Aware Propagation for Graph Feature Imputation
Jan 26, 2026Imputing missing node features in graphs is challenging, particularly under high missing rates. Existing methods based on latent representations or global diffusion often fail to produce reliable estimates, and may propagate errors across the graph. We propose FSD-CAP, a two-stage framework designed to improve imputation quality under extreme sparsity. In the first stage, a graph-distance-guided subgraph expansion localizes the diffusion process. A fractional diffusion operator adjusts propagation sharpness based on local structure. In the second stage, imputed features are refined using class-aware propagation, which incorporates pseudo-labels and neighborhood entropy to promote consistency. We evaluated FSD-CAP on multiple datasets. With $99.5\%$ of features missing across five benchmark datasets, FSD-CAP achieves average accuracies of $80.06\%$ (structural) and $81.01\%$ (uniform) in node classification, close to the $81.31\%$ achieved by a standard GCN with full features. For link prediction under the same setting, it reaches AUC scores of $91.65\%$ (structural) and $92.41\%$ (uniform), compared to $95.06\%$ for the fully observed case. Furthermore, FSD-CAP demonstrates superior performance on both large-scale and heterophily datasets when compared to other models.
Multi-Granularity Mutual Refinement Network for Zero-Shot Learning
Nov 11, 2025Zero-shot learning (ZSL) aims to recognize unseen classes with zero samples by transferring semantic knowledge from seen classes. Current approaches typically correlate global visual features with semantic information (i.e., attributes) or align local visual region features with corresponding attributes to enhance visual-semantic interactions. Although effective, these methods often overlook the intrinsic interactions between local region features, which can further improve the acquisition of transferable and explicit visual features. In this paper, we propose a network named Multi-Granularity Mutual Refinement Network (Mg-MRN), which refine discriminative and transferable visual features by learning decoupled multi-granularity features and cross-granularity feature interactions. Specifically, we design a multi-granularity feature extraction module to learn region-level discriminative features through decoupled region feature mining. Then, a cross-granularity feature fusion module strengthens the inherent interactions between region features of varying granularities. This module enhances the discriminability of representations at each granularity level by integrating region representations from adjacent hierarchies, further improving ZSL recognition performance. Extensive experiments on three popular ZSL benchmark datasets demonstrate the superiority and competitiveness of our proposed Mg-MRN method. Our code is available at https://github.com/NingWang2049/Mg-MRN.
TuckA: Hierarchical Compact Tensor Experts for Efficient Fine-Tuning
Nov 10, 2025Efficiently fine-tuning pre-trained models for downstream tasks is a key challenge in the era of foundation models. Parameter-efficient fine-tuning (PEFT) presents a promising solution, achieving performance comparable to full fine-tuning by updating only a small number of adaptation weights per layer. Traditional PEFT methods typically rely on a single expert, where the adaptation weight is a low-rank matrix. However, for complex tasks, the data's inherent diversity poses a significant challenge for such models, as a single adaptation weight cannot adequately capture the features of all samples. To address this limitation, we explore how to integrate multiple small adaptation experts into a compact structure to defeat a large adapter. Specifically, we propose Tucker Adaptation (TuckA), a method with four key properties: (i) We use Tucker decomposition to create a compact 3D tensor where each slice naturally serves as an expert. The low-rank nature of this decomposition ensures that the number of parameters scales efficiently as more experts are added. (ii) We introduce a hierarchical strategy that organizes these experts into groups at different granularities, allowing the model to capture both local and global data patterns. (iii) We develop an efficient batch-level routing mechanism, which reduces the router's parameter size by a factor of $L$ compared to routing at every adapted layer (where $L$ is the number of adapted layers) (iv) We propose data-aware initialization to achieve loss-free expert load balancing based on theoretical analysis. Extensive experiments on benchmarks in natural language understanding, image classification, and mathematical reasoning speak to the efficacy of TuckA, offering a new and effective solution to the PEFT problem.
OpenworldAUC: Towards Unified Evaluation and Optimization for Open-world Prompt Tuning
May 08, 2025Prompt tuning adapts Vision-Language Models like CLIP to open-world tasks with minimal training costs. In this direction, one typical paradigm evaluates model performance separately on known classes (i.e., base domain) and unseen classes (i.e., new domain). However, real-world scenarios require models to handle inputs without prior domain knowledge. This practical challenge has spurred the development of open-world prompt tuning, which demands a unified evaluation of two stages: 1) detecting whether an input belongs to the base or new domain (P1), and 2) classifying the sample into its correct class (P2). What's more, as domain distributions are generally unknown, a proper metric should be insensitive to varying base/new sample ratios (P3). However, we find that current metrics, including HM, overall accuracy, and AUROC, fail to satisfy these three properties simultaneously. To bridge this gap, we propose OpenworldAUC, a unified metric that jointly assesses detection and classification through pairwise instance comparisons. To optimize OpenworldAUC effectively, we introduce Gated Mixture-of-Prompts (GMoP), which employs domain-specific prompts and a gating mechanism to dynamically balance detection and classification. Theoretical guarantees ensure generalization of GMoP under practical conditions. Experiments on 15 benchmarks in open-world scenarios show GMoP achieves SOTA performance on OpenworldAUC and other metrics. We release the code at https://github.com/huacong/OpenworldAUC
ReconBoost: Boosting Can Achieve Modality Reconcilement
May 15, 2024



This paper explores a novel multi-modal alternating learning paradigm pursuing a reconciliation between the exploitation of uni-modal features and the exploration of cross-modal interactions. This is motivated by the fact that current paradigms of multi-modal learning tend to explore multi-modal features simultaneously. The resulting gradient prohibits further exploitation of the features in the weak modality, leading to modality competition, where the dominant modality overpowers the learning process. To address this issue, we study the modality-alternating learning paradigm to achieve reconcilement. Specifically, we propose a new method called ReconBoost to update a fixed modality each time. Herein, the learning objective is dynamically adjusted with a reconcilement regularization against competition with the historical models. By choosing a KL-based reconcilement, we show that the proposed method resembles Friedman's Gradient-Boosting (GB) algorithm, where the updated learner can correct errors made by others and help enhance the overall performance. The major difference with the classic GB is that we only preserve the newest model for each modality to avoid overfitting caused by ensembling strong learners. Furthermore, we propose a memory consolidation scheme and a global rectification scheme to make this strategy more effective. Experiments over six multi-modal benchmarks speak to the efficacy of the method. We release the code at https://github.com/huacong/ReconBoost.
Spatial Parsing and Dynamic Temporal Pooling networks for Human-Object Interaction detection
Jun 07, 2022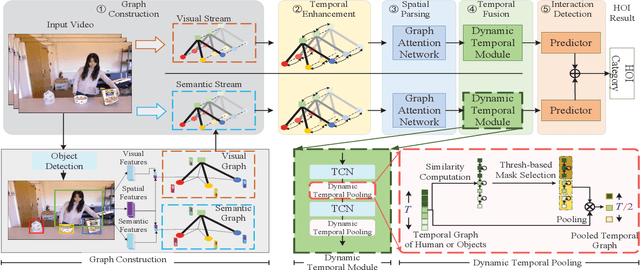
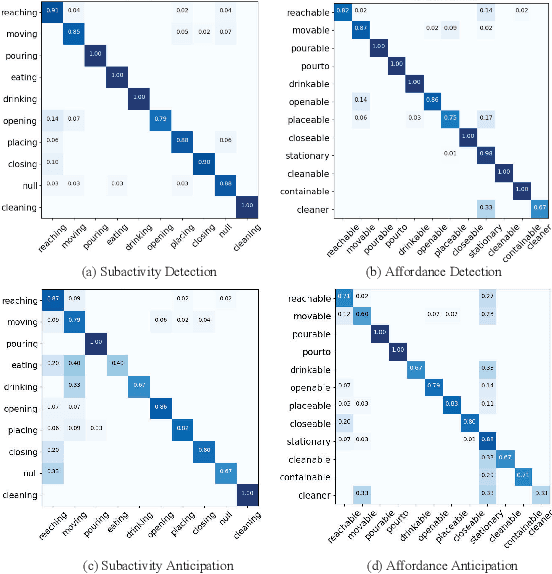


The key of Human-Object Interaction(HOI) recognition is to infer the relationship between human and objects. Recently, the image's Human-Object Interaction(HOI) detection has made significant progress. However, there is still room for improvement in video HOI detection performance. Existing one-stage methods use well-designed end-to-end networks to detect a video segment and directly predict an interaction. It makes the model learning and further optimization of the network more complex. This paper introduces the Spatial Parsing and Dynamic Temporal Pooling (SPDTP) network, which takes the entire video as a spatio-temporal graph with human and object nodes as input. Unlike existing methods, our proposed network predicts the difference between interactive and non-interactive pairs through explicit spatial parsing, and then performs interaction recognition. Moreover, we propose a learnable and differentiable Dynamic Temporal Module(DTM) to emphasize the keyframes of the video and suppress the redundant frame. Furthermore, the experimental results show that SPDTP can pay more attention to active human-object pairs and valid keyframes. Overall, we achieve state-of-the-art performance on CAD-120 dataset and Something-Else dataset.
Spatio-Temporal Interaction Graph Parsing Networks for Human-Object Interaction Recognition
Aug 19, 2021


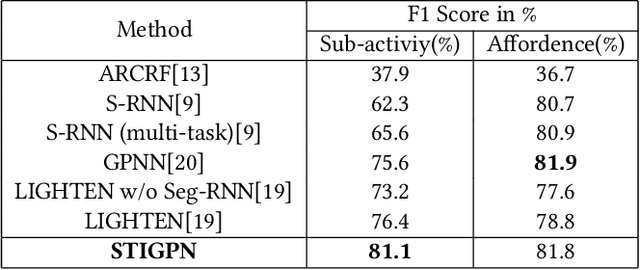
For a given video-based Human-Object Interaction scene, modeling the spatio-temporal relationship between humans and objects are the important cue to understand the contextual information presented in the video. With the effective spatio-temporal relationship modeling, it is possible not only to uncover contextual information in each frame but also to directly capture inter-time dependencies. It is more critical to capture the position changes of human and objects over the spatio-temporal dimension when their appearance features may not show up significant changes over time. The full use of appearance features, the spatial location and the semantic information are also the key to improve the video-based Human-Object Interaction recognition performance. In this paper, Spatio-Temporal Interaction Graph Parsing Networks (STIGPN) are constructed, which encode the videos with a graph composed of human and object nodes. These nodes are connected by two types of relations: (i) spatial relations modeling the interactions between human and the interacted objects within each frame. (ii) inter-time relations capturing the long range dependencies between human and the interacted objects across frame. With the graph, STIGPN learn spatio-temporal features directly from the whole video-based Human-Object Interaction scenes. Multi-modal features and a multi-stream fusion strategy are used to enhance the reasoning capability of STIGPN. Two Human-Object Interaction video datasets, including CAD-120 and Something-Else, are used to evaluate the proposed architectures, and the state-of-the-art performance demonstrates the superiority of STIGPN.
A Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021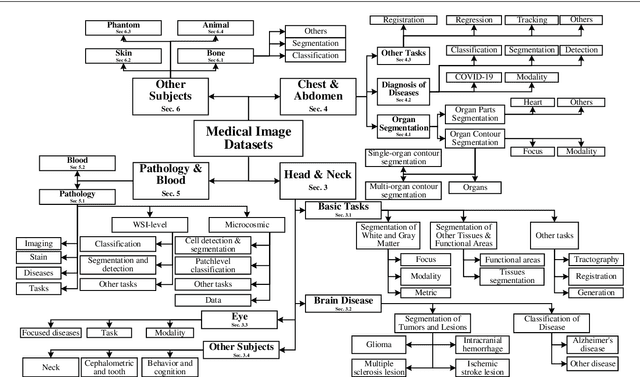
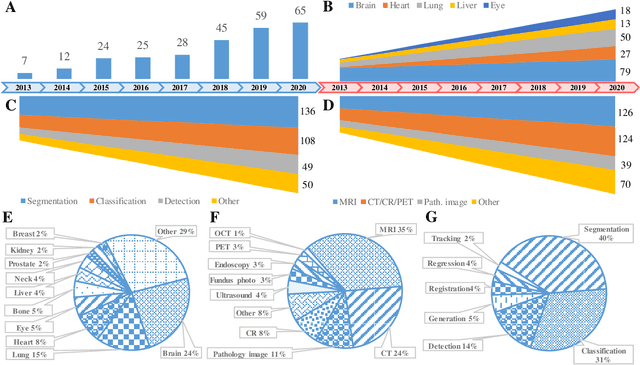
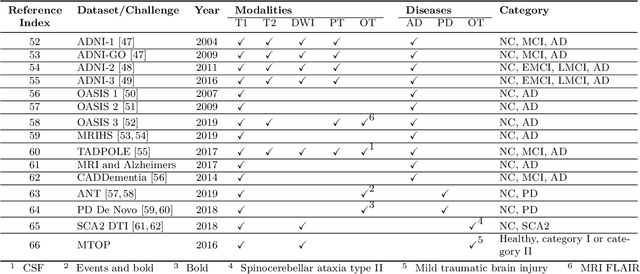
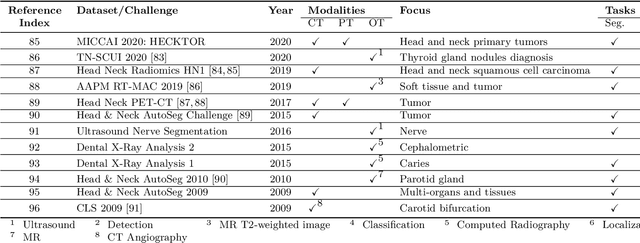
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.