 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Parsing and Dynamic Temporal Pooling networks for Human-Object Interaction detection
Paper and Code
Jun 07, 2022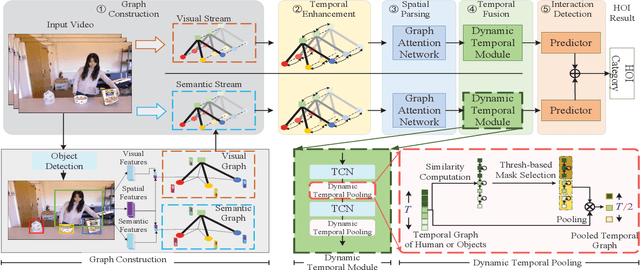


The key of Human-Object Interaction(HOI) recognition is to infer the relationship between human and objects. Recently, the image's Human-Object Interaction(HOI) detection has made significant progress. However, there is still room for improvement in video HOI detection performance. Existing one-stage methods use well-designed end-to-end networks to detect a video segment and directly predict an interaction. It makes the model learning and further optimization of the network more complex. This paper introduces the Spatial Parsing and Dynamic Temporal Pooling (SPDTP) network, which takes the entire video as a spatio-temporal graph with human and object nodes as input. Unlike existing methods, our proposed network predicts the difference between interactive and non-interactive pairs through explicit spatial parsing, and then performs interaction recognition. Moreover, we propose a learnable and differentiable Dynamic Temporal Module(DTM) to emphasize the keyframes of the video and suppress the redundant frame. Furthermore, the experimental results show that SPDTP can pay more attention to active human-object pairs and valid keyframes. Overall, we achieve state-of-the-art performance on CAD-120 dataset and Something-Else dataset.