 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe two-way knowledge interaction interface between humans and neural networks
Jan 10, 2024Despite neural networks (NN) have been widely applied in various fields and generally outperforms humans, they still lack interpretability to a certain extent, and humans are unable to intuitively understand the decision logic of NN. This also hinders the knowledge interaction between humans and NN, preventing humans from getting involved to give direct guidance when NN's decisions go wrong. While recent research in explainable AI has achieved interpretability of NN from various perspectives, it has not yet provided effective methods for knowledge exchange between humans and NN. To address this problem, we constructed a two-way interaction interface that uses structured representations of visual concepts and their relationships as the "language" for knowledge exchange between humans and NN. Specifically, NN provide intuitive reasoning explanations to humans based on the class-specific structural concepts graph (C-SCG). On the other hand, humans can modify the biases present in the C-SCG through their prior knowledge and reasoning ability, and thus provide direct knowledge guidance to NN through this interface. Through experimental validation, based on this interaction interface, NN can provide humans with easily understandable explanations of the reasoning process. Furthermore, human involvement and prior knowledge can directly and effectively contribute to enhancing the performance of NN.
Spatial Parsing and Dynamic Temporal Pooling networks for Human-Object Interaction detection
Jun 07, 2022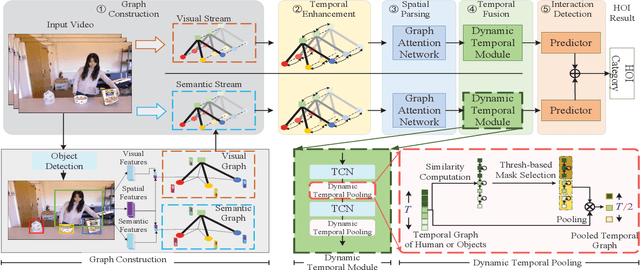


The key of Human-Object Interaction(HOI) recognition is to infer the relationship between human and objects. Recently, the image's Human-Object Interaction(HOI) detection has made significant progress. However, there is still room for improvement in video HOI detection performance. Existing one-stage methods use well-designed end-to-end networks to detect a video segment and directly predict an interaction. It makes the model learning and further optimization of the network more complex. This paper introduces the Spatial Parsing and Dynamic Temporal Pooling (SPDTP) network, which takes the entire video as a spatio-temporal graph with human and object nodes as input. Unlike existing methods, our proposed network predicts the difference between interactive and non-interactive pairs through explicit spatial parsing, and then performs interaction recognition. Moreover, we propose a learnable and differentiable Dynamic Temporal Module(DTM) to emphasize the keyframes of the video and suppress the redundant frame. Furthermore, the experimental results show that SPDTP can pay more attention to active human-object pairs and valid keyframes. Overall, we achieve state-of-the-art performance on CAD-120 dataset and Something-Else dataset.
Scene Graph Generation: A Comprehensive Survey
Jan 03, 2022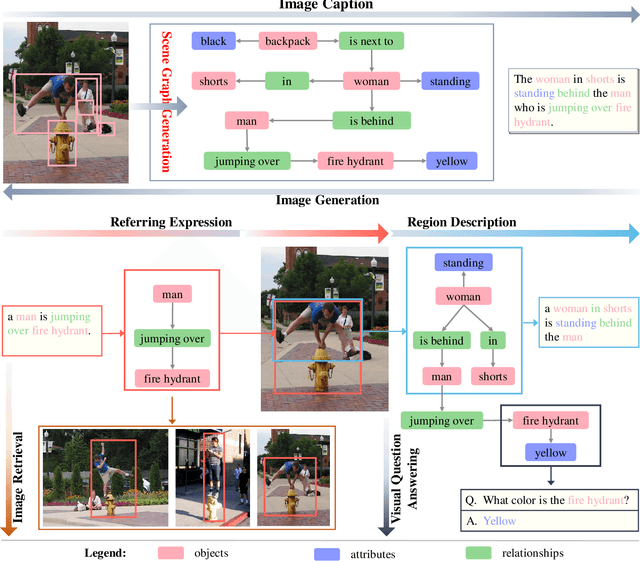
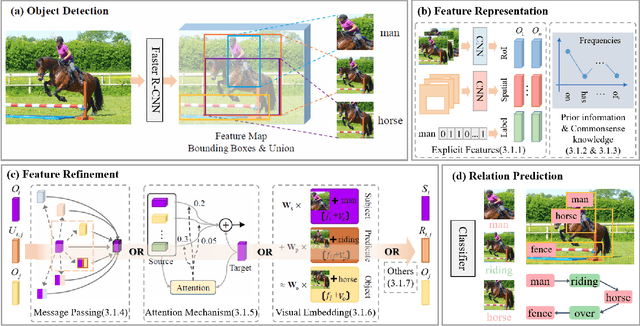
Deep learning techniques have led to remarkable breakthroughs in the field of generic object detection and have spawned a lot of scene-understanding tasks in recent years. Scene graph has been the focus of research because of its powerful semantic representation and applications to scene understanding. Scene Graph Generation (SGG) refers to the task of automatically mapping an image into a semantic structural scene graph, which requires the correct labeling of detected objects and their relationships. Although this is a challenging task, the community has proposed a lot of SGG approaches and achieved good results. In this paper, we provide a comprehensive survey of recent achievements in this field brought about by deep learning techniques. We review 138 representative works that cover different input modalities, and systematically summarize existing methods of image-based SGG from the perspective of feature extraction and fusion. We attempt to connect and systematize the existing visual relationship detection methods, to summarize, and interpret the mechanisms and the strategies of SGG in a comprehensive way. Finally, we finish this survey with deep discussions about current existing problems and future research directions. This survey will help readers to develop a better understanding of the current research status and ideas.
Spatio-Temporal Interaction Graph Parsing Networks for Human-Object Interaction Recognition
Aug 19, 2021


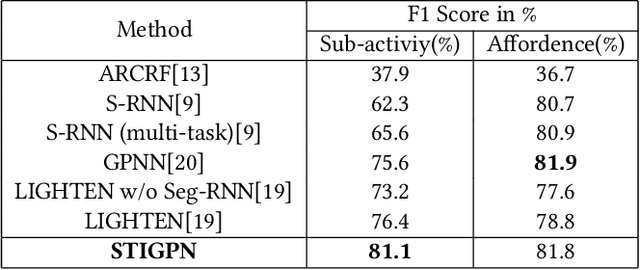
For a given video-based Human-Object Interaction scene, modeling the spatio-temporal relationship between humans and objects are the important cue to understand the contextual information presented in the video. With the effective spatio-temporal relationship modeling, it is possible not only to uncover contextual information in each frame but also to directly capture inter-time dependencies. It is more critical to capture the position changes of human and objects over the spatio-temporal dimension when their appearance features may not show up significant changes over time. The full use of appearance features, the spatial location and the semantic information are also the key to improve the video-based Human-Object Interaction recognition performance. In this paper, Spatio-Temporal Interaction Graph Parsing Networks (STIGPN) are constructed, which encode the videos with a graph composed of human and object nodes. These nodes are connected by two types of relations: (i) spatial relations modeling the interactions between human and the interacted objects within each frame. (ii) inter-time relations capturing the long range dependencies between human and the interacted objects across frame. With the graph, STIGPN learn spatio-temporal features directly from the whole video-based Human-Object Interaction scenes. Multi-modal features and a multi-stream fusion strategy are used to enhance the reasoning capability of STIGPN. Two Human-Object Interaction video datasets, including CAD-120 and Something-Else, are used to evaluate the proposed architectures, and the state-of-the-art performance demonstrates the superiority of STIGPN.
A Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021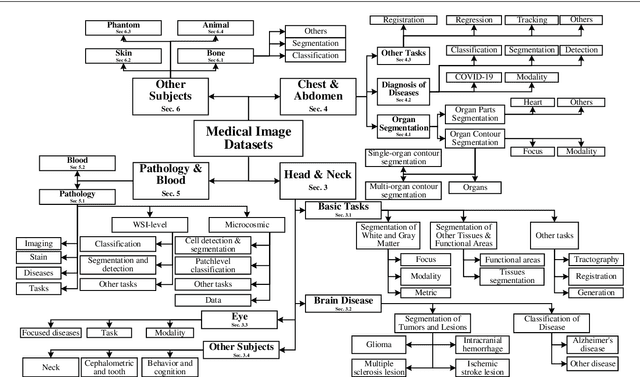
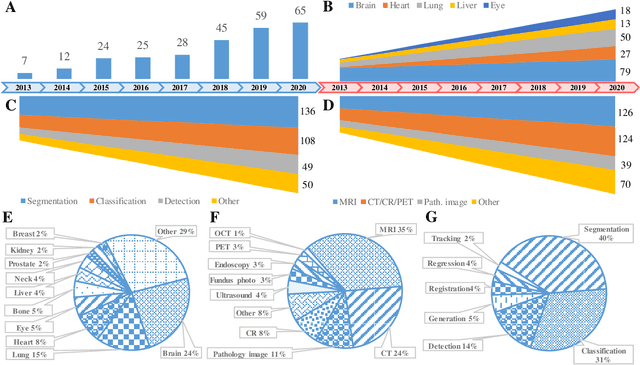
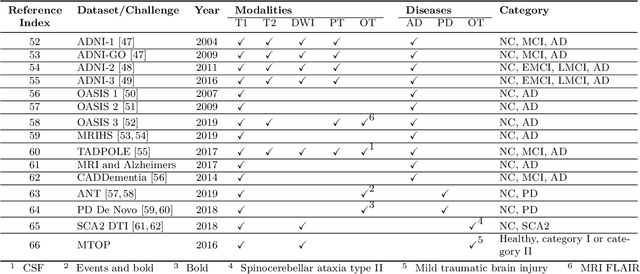
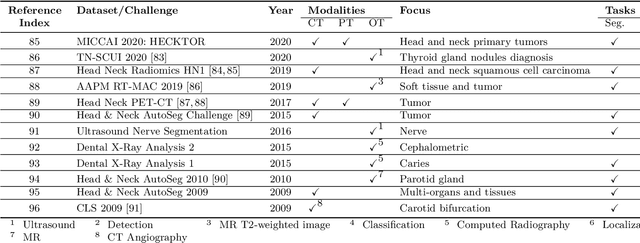
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.
MeDaS: An open-source platform as service to help break the walls between medicine and informatics
Jul 14, 2020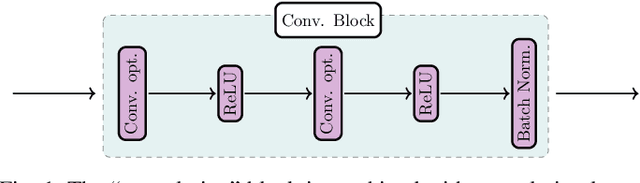


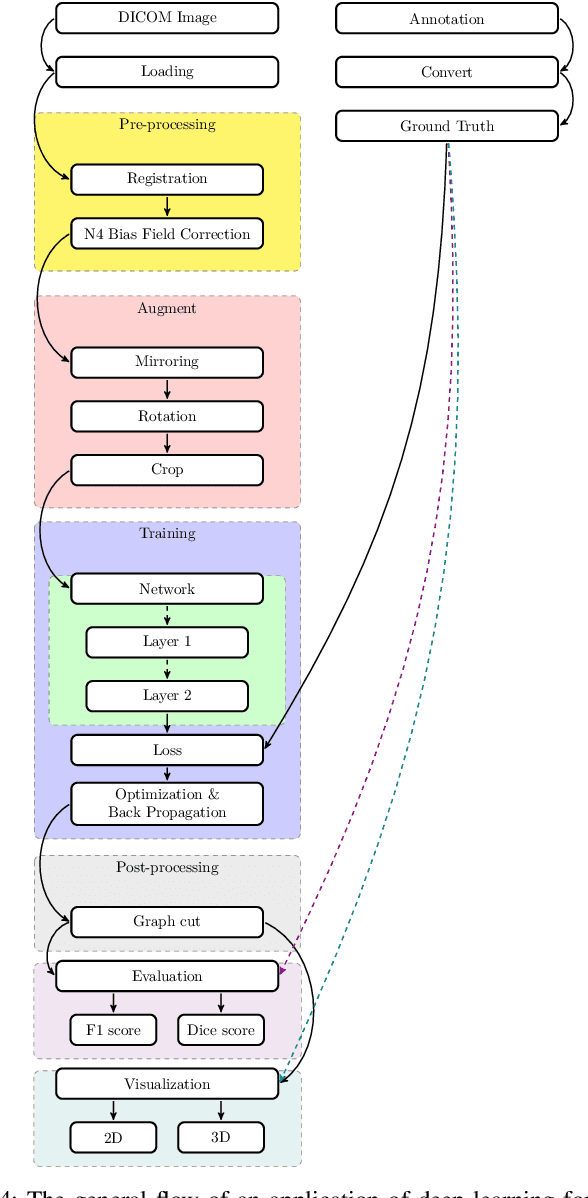
In the past decade, deep learning (DL) has achieved unprecedented success in numerous fields including computer vision, natural language processing, and healthcare. In particular, DL is experiencing an increasing development in applications for advanced medical image analysis in terms of analysis, segmentation, classification, and furthermore. On the one hand, tremendous needs that leverage the power of DL for medical image analysis are arising from the research community of a medical, clinical, and informatics background to jointly share their expertise, knowledge, skills, and experience. On the other hand, barriers between disciplines are on the road for them often hampering a full and efficient collaboration. To this end, we propose our novel open-source platform, i.e., MeDaS -- the MeDical open-source platform as Service. To the best of our knowledge, MeDaS is the first open-source platform proving a collaborative and interactive service for researchers from a medical background easily using DL related toolkits, and at the same time for scientists or engineers from information sciences to understand the medical knowledge side. Based on a series of toolkits and utilities from the idea of RINV (Rapid Implementation aNd Verification), our proposed MeDaS platform can implement pre-processing, post-processing, augmentation, visualization, and other phases needed in medical image analysis. Five tasks including the subjects of lung, liver, brain, chest, and pathology, are validated and demonstrated to be efficiently realisable by using MeDaS.
Structure-Feature based Graph Self-adaptive Pooling
Jan 30, 2020

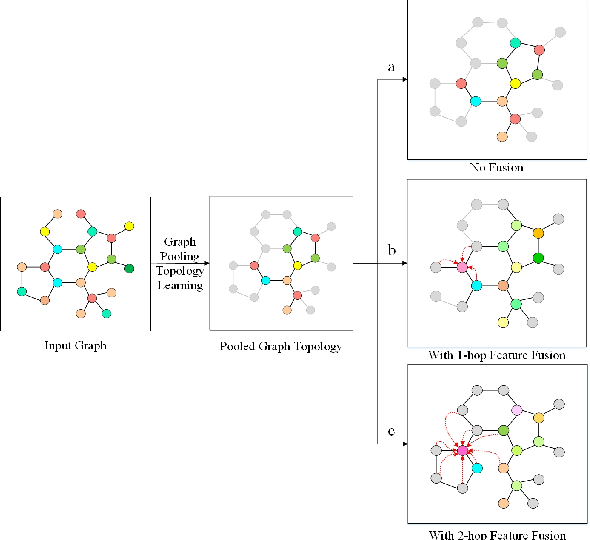
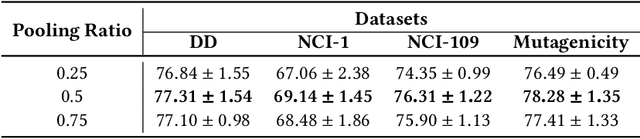
Various methods to deal with graph data have been proposed in recent years. However, most of these methods focus on graph feature aggregation rather than graph pooling. Besides, the existing top-k selection graph pooling methods have a few problems. First, to construct the pooled graph topology, current top-k selection methods evaluate the importance of the node from a single perspective only, which is simplistic and unobjective. Second, the feature information of unselected nodes is directly lost during the pooling process, which inevitably leads to a massive loss of graph feature information. To solve these problems mentioned above, we propose a novel graph self-adaptive pooling method with the following objectives: (1) to construct a reasonable pooled graph topology, structure and feature information of the graph are considered simultaneously, which provide additional veracity and objectivity in node selection; and (2) to make the pooled nodes contain sufficiently effective graph information, node feature information is aggregated before discarding the unimportant nodes; thus, the selected nodes contain information from neighbor nodes, which can enhance the use of features of the unselected nodes. Experimental results on four different datasets demonstrate that our method is effective in graph classification and outperforms state-of-the-art graph pooling methods.
Efficient Scene Text Detection with Textual Attention Tower
Jan 30, 2020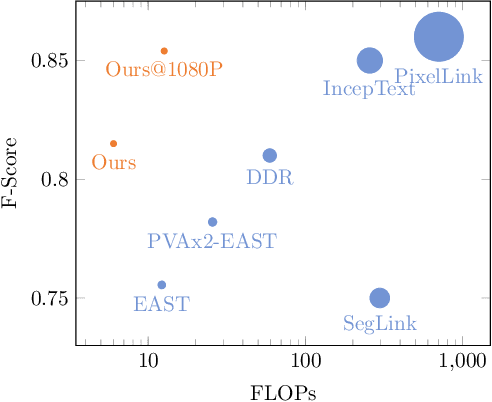
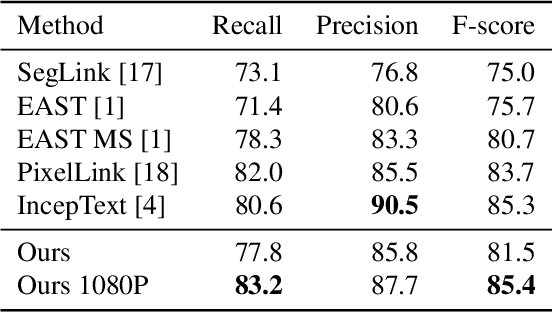


Scene text detection has received attention for years and achieved an impressive performance across various benchmarks. In this work, we propose an efficient and accurate approach to detect multioriented text in scene images. The proposed feature fusion mechanism allows us to use a shallower network to reduce the computational complexity. A self-attention mechanism is adopted to suppress false positive detections. Experiments on public benchmarks including ICDAR 2013, ICDAR 2015 and MSRA-TD500 show that our proposed approach can achieve better or comparable performances with fewer parameters and less computational cost.