 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD-CAP: Fractional Subgraph Diffusion with Class-Aware Propagation for Graph Feature Imputation
Jan 26, 2026Imputing missing node features in graphs is challenging, particularly under high missing rates. Existing methods based on latent representations or global diffusion often fail to produce reliable estimates, and may propagate errors across the graph. We propose FSD-CAP, a two-stage framework designed to improve imputation quality under extreme sparsity. In the first stage, a graph-distance-guided subgraph expansion localizes the diffusion process. A fractional diffusion operator adjusts propagation sharpness based on local structure. In the second stage, imputed features are refined using class-aware propagation, which incorporates pseudo-labels and neighborhood entropy to promote consistency. We evaluated FSD-CAP on multiple datasets. With $99.5\%$ of features missing across five benchmark datasets, FSD-CAP achieves average accuracies of $80.06\%$ (structural) and $81.01\%$ (uniform) in node classification, close to the $81.31\%$ achieved by a standard GCN with full features. For link prediction under the same setting, it reaches AUC scores of $91.65\%$ (structural) and $92.41\%$ (uniform), compared to $95.06\%$ for the fully observed case. Furthermore, FSD-CAP demonstrates superior performance on both large-scale and heterophily datasets when compared to other models.
Scene Graph Generation: A Comprehensive Survey
Jan 03, 2022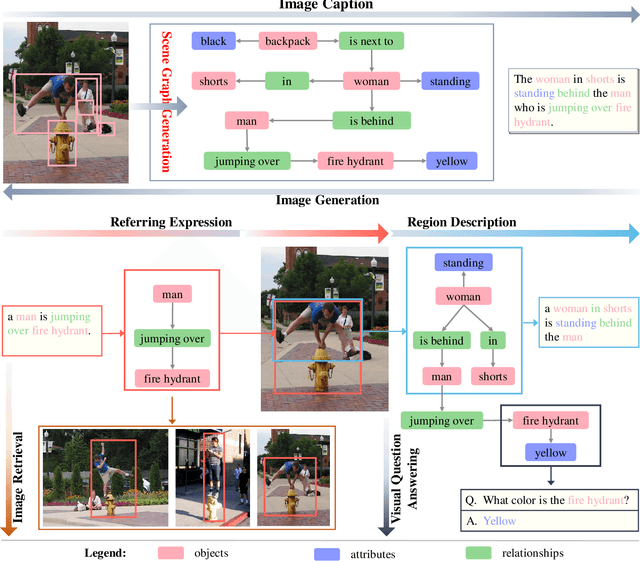
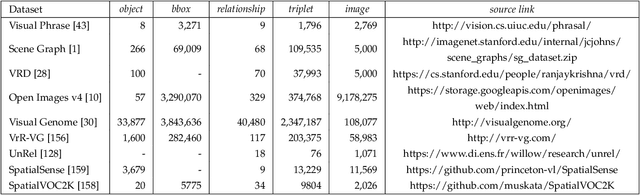
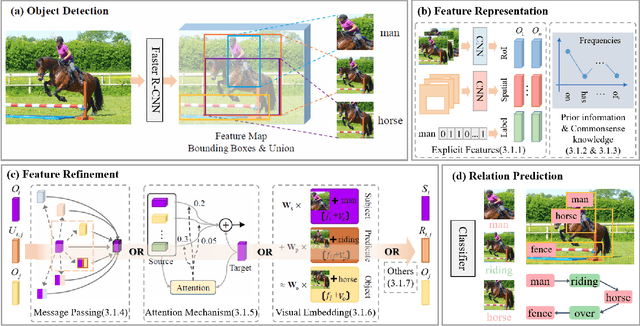
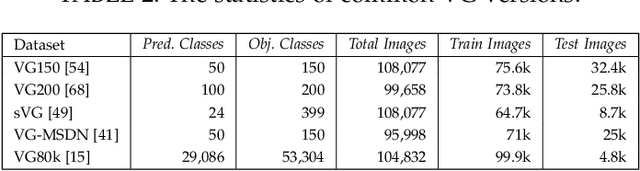
Deep learning techniques have led to remarkable breakthroughs in the field of generic object detection and have spawned a lot of scene-understanding tasks in recent years. Scene graph has been the focus of research because of its powerful semantic representation and applications to scene understanding. Scene Graph Generation (SGG) refers to the task of automatically mapping an image into a semantic structural scene graph, which requires the correct labeling of detected objects and their relationships. Although this is a challenging task, the community has proposed a lot of SGG approaches and achieved good results. In this paper, we provide a comprehensive survey of recent achievements in this field brought about by deep learning techniques. We review 138 representative works that cover different input modalities, and systematically summarize existing methods of image-based SGG from the perspective of feature extraction and fusion. We attempt to connect and systematize the existing visual relationship detection methods, to summarize, and interpret the mechanisms and the strategies of SGG in a comprehensive way. Finally, we finish this survey with deep discussions about current existing problems and future research directions. This survey will help readers to develop a better understanding of the current research status and ideas.
Cross-lingual Data Transformation and Combination for Text Classification
Jun 23, 2019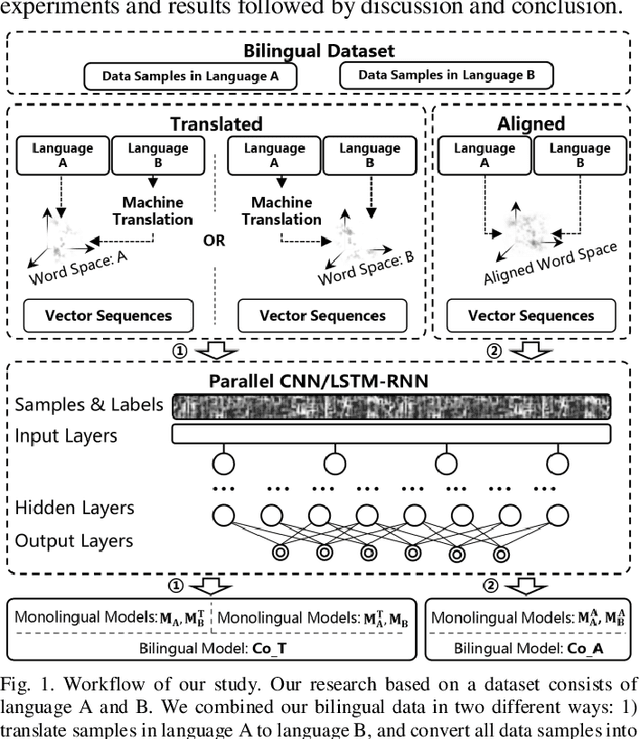
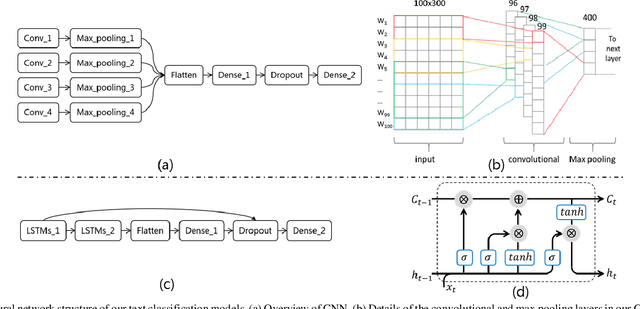
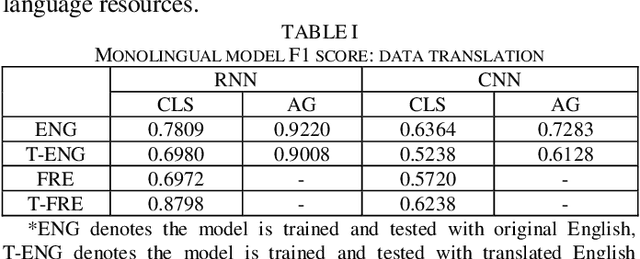
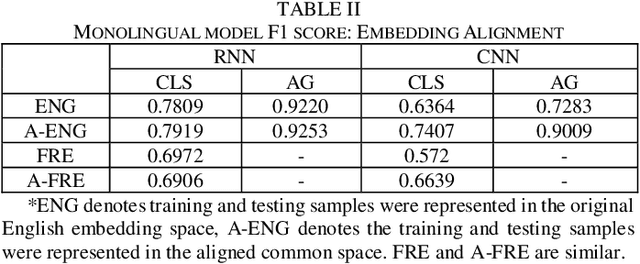
Text classification is a fundamental task for text data mining. In order to train a generalizable model, a large volume of text must be collected. To address data insufficiency, cross-lingual data may occasionally be necessary. Cross-lingual data sources may however suffer from data incompatibility, as text written in different languages can hold distinct word sequences and semantic patterns. Machine translation and word embedding alignment provide an effective way to transform and combine data for cross-lingual data training. To the best of our knowledge, there has been little work done on evaluating how the methodology used to conduct semantic space transformation and data combination affects the performance of classification models trained from cross-lingual resources. In this paper, we systematically evaluated the performance of two commonly used CNN (Convolutional Neural Network) and RNN (Recurrent Neural Network) text classifiers with differing data transformation and combination strategies. Monolingual models were trained from English and French alongside their translated and aligned embeddings. Our results suggested that semantic space transformation may conditionally promote the performance of monolingual models. Bilingual models were trained from a combination of both English and French. Our results indicate that a cross-lingual classification model can significantly benefit from cross-lingual data by learning from translated or aligned embedding spaces.