 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic Model Context Protocol Framework for Medical Concept Standardization
Sep 04, 2025The Observational Medical Outcomes Partnership (OMOP) common data model (CDM) provides a standardized representation of heterogeneous health data to support large-scale, multi-institutional research. One critical step in data standardization using OMOP CDM is the mapping of source medical terms to OMOP standard concepts, a procedure that is resource-intensive and error-prone. While large language models (LLMs) have the potential to facilitate this process, their tendency toward hallucination makes them unsuitable for clinical deployment without training and expert validation. Here, we developed a zero-training, hallucination-preventive mapping system based on the Model Context Protocol (MCP), a standardized and secure framework allowing LLMs to interact with external resources and tools. The system enables explainable mapping and significantly improves efficiency and accuracy with minimal effort. It provides real-time vocabulary lookups and structured reasoning outputs suitable for immediate use in both exploratory and production environments.
Multi-Label Classification with Generative AI Models in Healthcare: A Case Study of Suicidality and Risk Factors
Jul 22, 2025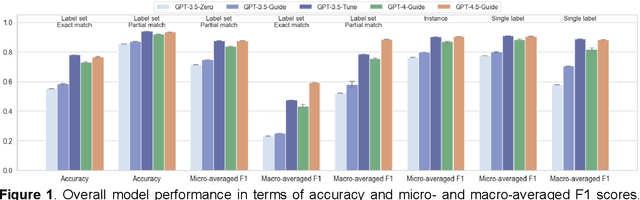
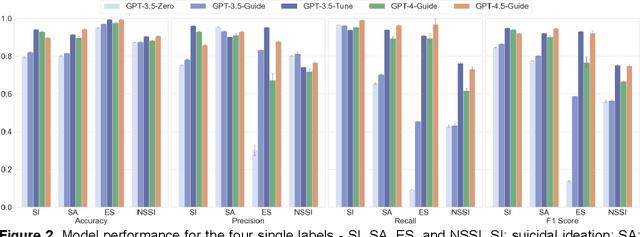
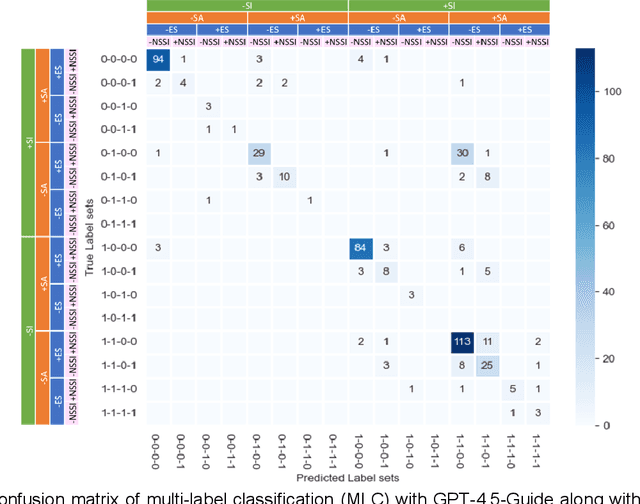
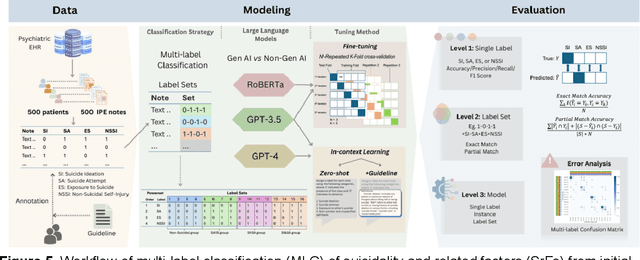
Suicide remains a pressing global health crisis, with over 720,000 deaths annually and millions more affected by suicide ideation (SI) and suicide attempts (SA). Early identification of suicidality-related factors (SrFs), including SI, SA, exposure to suicide (ES), and non-suicidal self-injury (NSSI), is critical for timely intervention. While prior studies have applied AI to detect SrFs in clinical notes, most treat suicidality as a binary classification task, overlooking the complexity of cooccurring risk factors. This study explores the use of generative large language models (LLMs), specifically GPT-3.5 and GPT-4.5, for multi-label classification (MLC) of SrFs from psychiatric electronic health records (EHRs). We present a novel end to end generative MLC pipeline and introduce advanced evaluation methods, including label set level metrics and a multilabel confusion matrix for error analysis. Finetuned GPT-3.5 achieved top performance with 0.94 partial match accuracy and 0.91 F1 score, while GPT-4.5 with guided prompting showed superior performance across label sets, including rare or minority label sets, indicating a more balanced and robust performance. Our findings reveal systematic error patterns, such as the conflation of SI and SA, and highlight the models tendency toward cautious over labeling. This work not only demonstrates the feasibility of using generative AI for complex clinical classification tasks but also provides a blueprint for structuring unstructured EHR data to support large scale clinical research and evidence based medicine.
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Mar 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved performance in System-2 reasoning domains like mathematics and programming by harnessing supervised fine-tuning (SFT) and reinforcement learning (RL) techniques to enhance the Chain-of-Thought (CoT) reasoning. However, while longer CoT reasoning sequences improve performance, they also introduce significant computational overhead due to verbose and redundant outputs, known as the "overthinking phenomenon". In this paper, we provide the first structured survey to systematically investigate and explore the current progress toward achieving efficient reasoning in LLMs. Overall, relying on the inherent mechanism of LLMs, we categorize existing works into several key directions: (1) model-based efficient reasoning, which considers optimizing full-length reasoning models into more concise reasoning models or directly training efficient reasoning models; (2) reasoning output-based efficient reasoning, which aims to dynamically reduce reasoning steps and length during inference; (3) input prompts-based efficient reasoning, which seeks to enhance reasoning efficiency based on input prompt properties such as difficulty or length control. Additionally, we introduce the use of efficient data for training reasoning models, explore the reasoning capabilities of small language models, and discuss evaluation methods and benchmarking.
Explainable Diagnosis Prediction through Neuro-Symbolic Integration
Oct 01, 2024

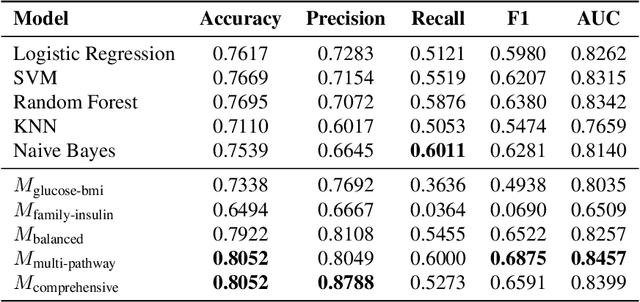
Diagnosis prediction is a critical task in healthcare, where timely and accurate identification of medical conditions can significantly impact patient outcomes. Traditional machine learning and deep learning models have achieved notable success in this domain but often lack interpretability which is a crucial requirement in clinical settings. In this study, we explore the use of neuro-symbolic methods, specifically Logical Neural Networks (LNNs), to develop explainable models for diagnosis prediction. Essentially, we design and implement LNN-based models that integrate domain-specific knowledge through logical rules with learnable thresholds. Our models, particularly $M_{\text{multi-pathway}}$ and $M_{\text{comprehensive}}$, demonstrate superior performance over traditional models such as Logistic Regression, SVM, and Random Forest, achieving higher accuracy (up to 80.52\%) and AUROC scores (up to 0.8457) in the case study of diabetes prediction. The learned weights and thresholds within the LNN models provide direct insights into feature contributions, enhancing interpretability without compromising predictive power. These findings highlight the potential of neuro-symbolic approaches in bridging the gap between accuracy and explainability in healthcare AI applications. By offering transparent and adaptable diagnostic models, our work contributes to the advancement of precision medicine and supports the development of equitable healthcare solutions. Future research will focus on extending these methods to larger and more diverse datasets to further validate their applicability across different medical conditions and populations.
Large Language Models Struggle in Token-Level Clinical Named Entity Recognition
Jun 30, 2024Large Language Models (LLMs) have revolutionized various sectors, including healthcare where they are employed in diverse applications. Their utility is particularly significant in the context of rare diseases, where data scarcity, complexity, and specificity pose considerable challenges. In the clinical domain, Named Entity Recognition (NER) stands out as an essential task and it plays a crucial role in extracting relevant information from clinical texts. Despite the promise of LLMs, current research mostly concentrates on document-level NER, identifying entities in a more general context across entire documents, without extracting their precise location. Additionally, efforts have been directed towards adapting ChatGPT for token-level NER. However, there is a significant research gap when it comes to employing token-level NER for clinical texts, especially with the use of local open-source LLMs. This study aims to bridge this gap by investigating the effectiveness of both proprietary and local LLMs in token-level clinical NER. Essentially, we delve into the capabilities of these models through a series of experiments involving zero-shot prompting, few-shot prompting, retrieval-augmented generation (RAG), and instruction-fine-tuning. Our exploration reveals the inherent challenges LLMs face in token-level NER, particularly in the context of rare diseases, and suggests possible improvements for their application in healthcare. This research contributes to narrowing a significant gap in healthcare informatics and offers insights that could lead to a more refined application of LLMs in the healthcare sector.
An Open Natural Language Processing Development Framework for EHR-based Clinical Research: A case demonstration using the National COVID Cohort Collaborative (N3C)
Oct 20, 2021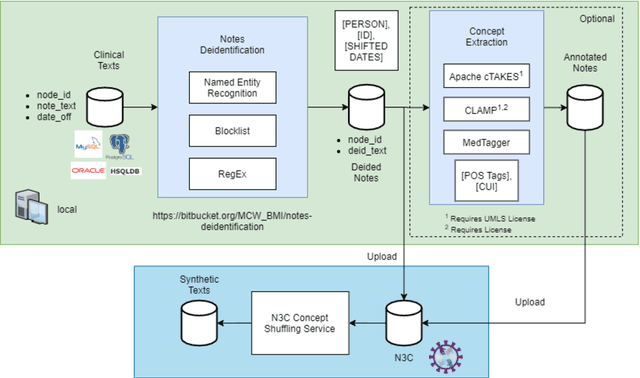

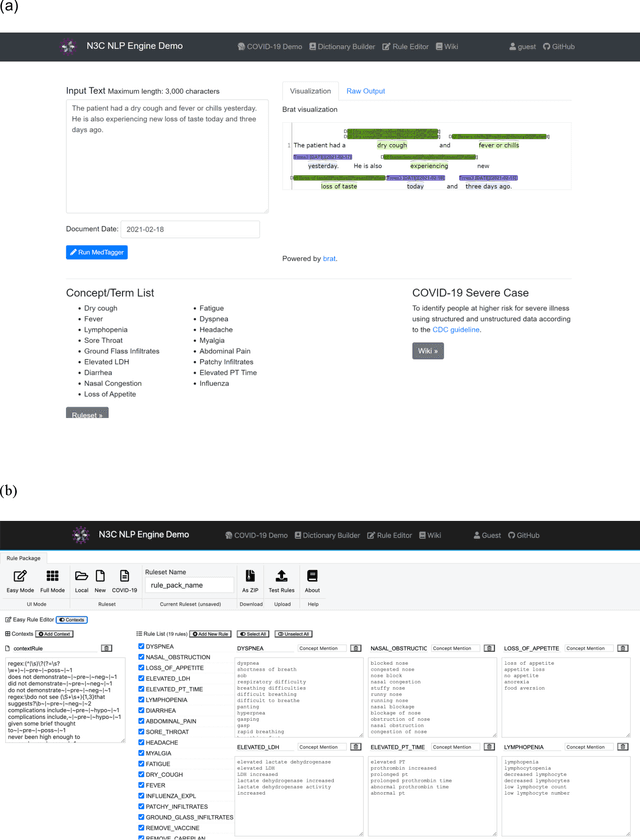
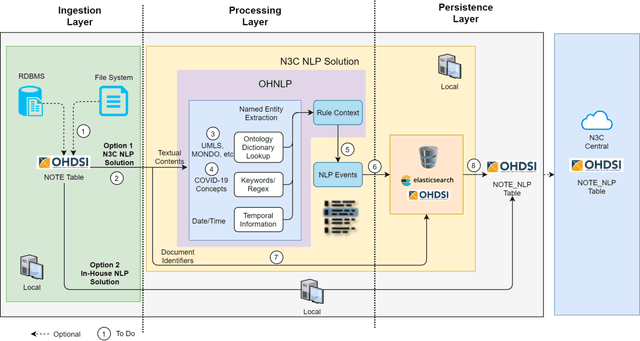
While we pay attention to the latest advances in clinical natural language processing (NLP), we can notice some resistance in the clinical and translational research community to adopt NLP models due to limited transparency, Interpretability and usability. Built upon our previous work, in this study, we proposed an open natural language processing development framework and evaluated it through the implementation of NLP algorithms for the National COVID Cohort Collaborative (N3C). Based on the interests in information extraction from COVID-19 related clinical notes, our work includes 1) an open data annotation process using COVID-19 signs and symptoms as the use case, 2) a community-driven ruleset composing platform, and 3) a synthetic text data generation workflow to generate texts for information extraction tasks without involving human subjects. The generated corpora derived out of the texts from multiple intuitions and gold standard annotation are tested on a single institution's rule set has the performances in F1 score of 0.876, 0.706 and 0.694, respectively. The study as a consortium effort of the N3C NLP subgroup demonstrates the feasibility of creating a federated NLP algorithm development and benchmarking platform to enhance multi-institution clinical NLP study.
Leveraging a Joint of Phenotypic and Genetic Features on Cancer Patient Subgrouping
Mar 30, 2021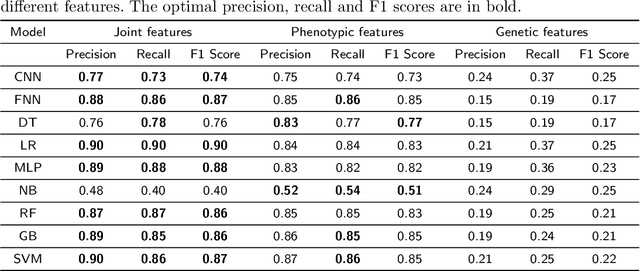

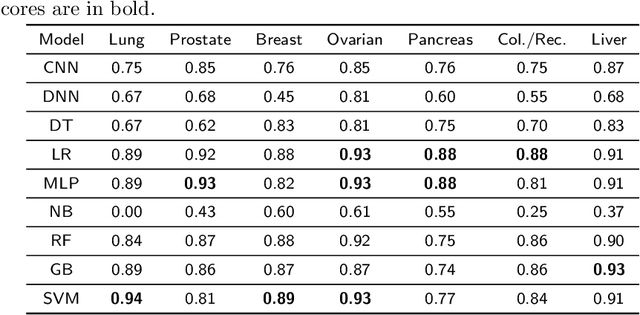
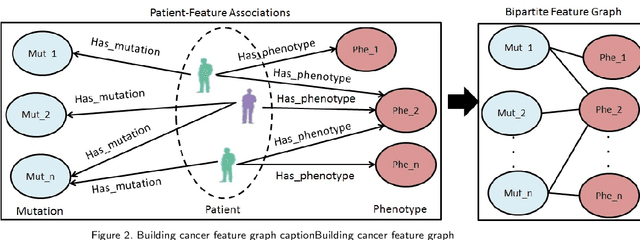
Cancer is responsible for millions of deaths worldwide every year. Although significant progress has been achieved in cancer medicine, many issues remain to be addressed for improving cancer therapy. Appropriate cancer patient stratification is the prerequisite for selecting appropriate treatment plan, as cancer patients are of known heterogeneous genetic make-ups and phenotypic differences. In this study, built upon deep phenotypic characterizations extractable from Mayo Clinic electronic health records (EHRs) and genetic test reports for a collection of cancer patients, we developed a system leveraging a joint of phenotypic and genetic features for cancer patient subgrouping. The workflow is roughly divided into three parts: feature preprocessing, cancer patient classification, and cancer patient clustering based. In feature preprocessing step, we performed filtering, retaining the most relevant features. In cancer patient classification, we utilized joint categorical features to build a patient-feature matrix and applied nine different machine learning models, Random Forests (RF), Decision Tree (DT), Support Vector Machine (SVM), Naive Bayes (NB), Logistic Regression (LR), Multilayer Perceptron (MLP), Gradient Boosting (GB), Convolutional Neural Network (CNN), and Feedforward Neural Network (FNN), for classification purposes. Finally, in the cancer patient clustering step, we leveraged joint embeddings features and patient-feature associations to build an undirected feature graph and then trained the cancer feature node embeddings.
Comparisons of Graph Neural Networks on Cancer Classification Leveraging a Joint of Phenotypic and Genetic Features
Jan 14, 2021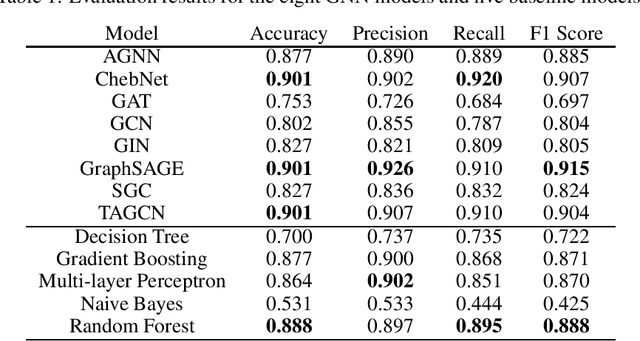
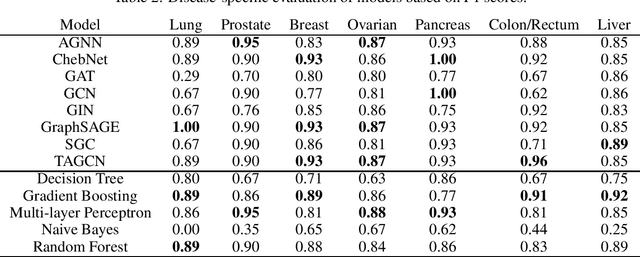
Cancer is responsible for millions of deaths worldwide every year. Although significant progress hasbeen achieved in cancer medicine, many issues remain to be addressed for improving cancer therapy.Appropriate cancer patient stratification is the prerequisite for selecting appropriate treatment plan, ascancer patients are of known heterogeneous genetic make-ups and phenotypic differences. In thisstudy, built upon deep phenotypic characterizations extractable from Mayo Clinic electronic healthrecords (EHRs) and genetic test reports for a collection of cancer patients, we evaluated variousgraph neural networks (GNNs) leveraging a joint of phenotypic and genetic features for cancer typeclassification. Models were applied and fine-tuned on the Mayo Clinic cancer disease dataset. Theassessment was done through the reported accuracy, precision, recall, and F1 values as well as throughF1 scores based on the disease class. Per our evaluation results, GNNs on average outperformed thebaseline models with mean statistics always being higher that those of the baseline models (0.849 vs0.772 for accuracy, 0.858 vs 0.794 for precision, 0.843 vs 0.759 for recall, and 0.843 vs 0.855 for F1score). Among GNNs, ChebNet, GraphSAGE, and TAGCN showed the best performance, while GATshowed the worst. We applied and compared eight GNN models including AGNN, ChebNet, GAT,GCN, GIN, GraphSAGE, SGC, and TAGCN on the Mayo Clinic cancer disease dataset and assessedtheir performance as well as compared them with each other and with more conventional machinelearning models such as decision tree, gradient boosting, multi-layer perceptron, naive bayes, andrandom forest which we used as the baselines.
Adapting and evaluating a deep learning language model for clinical why-question answering
Nov 13, 2019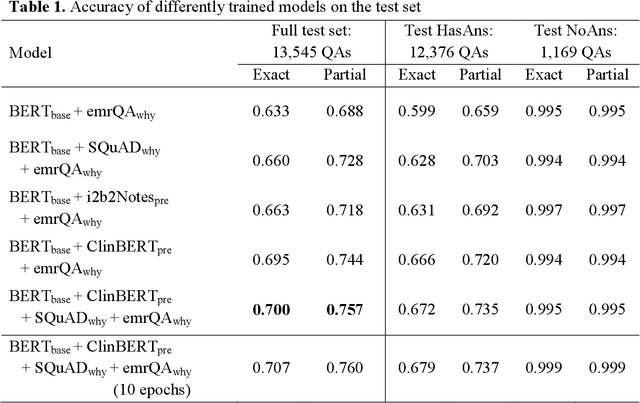


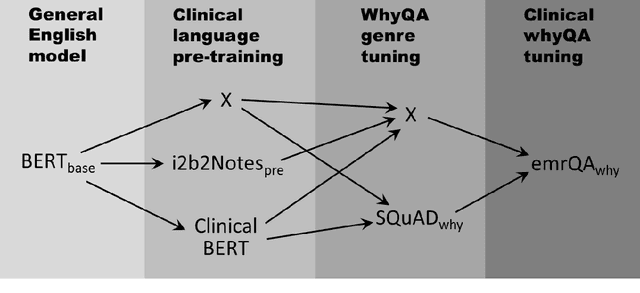
Objectives: To adapt and evaluate a deep learning language model for answering why-questions based on patient-specific clinical text. Materials and Methods: Bidirectional encoder representations from transformers (BERT) models were trained with varying data sources to perform SQuAD 2.0 style why-question answering (why-QA) on clinical notes. The evaluation focused on: 1) comparing the merits from different training data, 2) error analysis. Results: The best model achieved an accuracy of 0.707 (or 0.760 by partial match). Training toward customization for the clinical language helped increase 6% in accuracy. Discussion: The error analysis suggested that the model did not really perform deep reasoning and that clinical why-QA might warrant more sophisticated solutions. Conclusion: The BERT model achieved moderate accuracy in clinical why-QA and should benefit from the rapidly evolving technology. Despite the identified limitations, it could serve as a competent proxy for question-driven clinical information extraction.
Development of Clinical Concept Extraction Applications: A Methodology Review
Oct 28, 2019
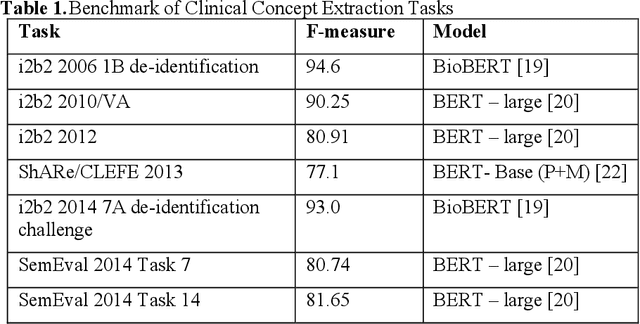
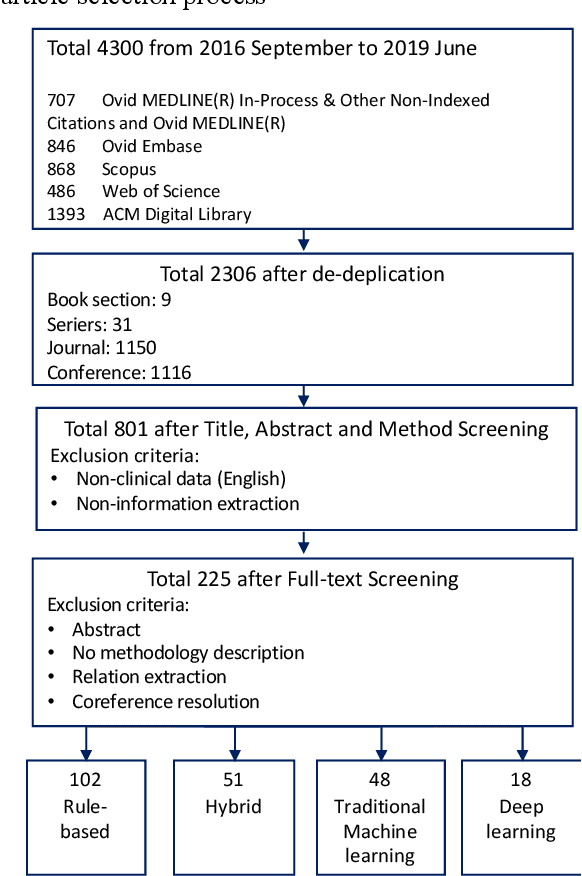
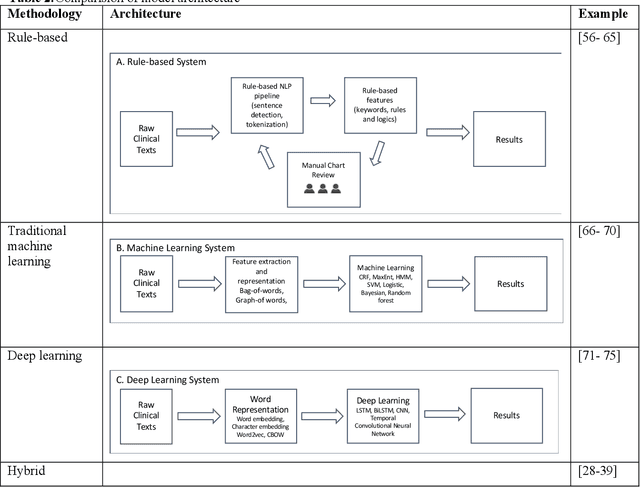
Our study provided a review of the development of clinical concept extraction applications from January 2009 to June 2019. We hope, through the studying of different approaches with variant clinical context, can enhance the decision making for the development of clinical concept extraction.