 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated Mitral Inflow Doppler Analysis Using Deep Learning
Nov 24, 2020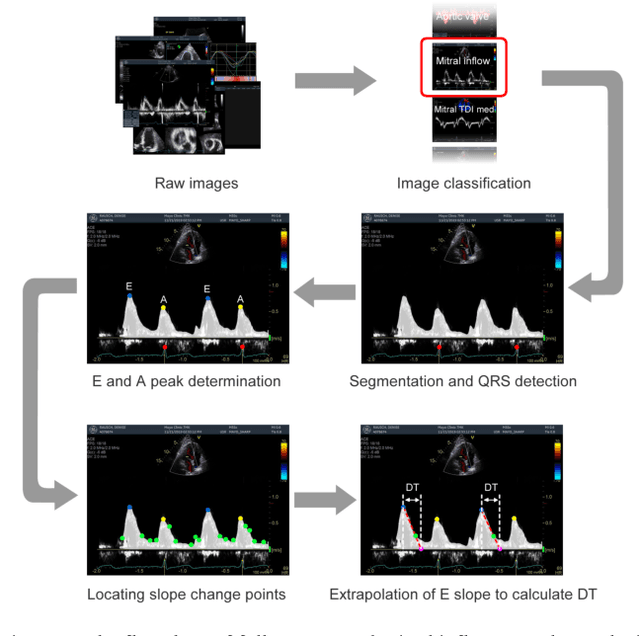
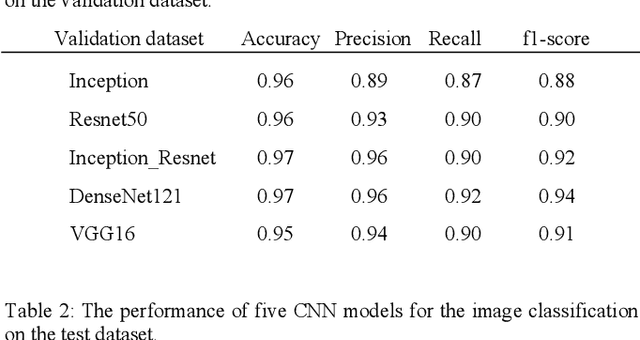

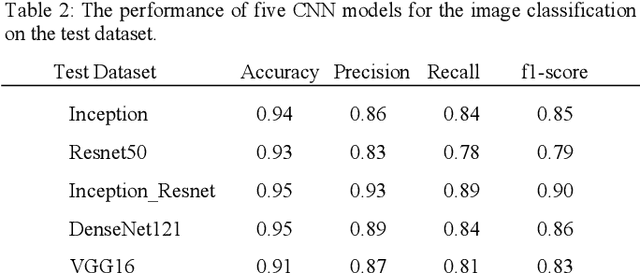
Echocardiography (echo) is an indispensable tool in a cardiologist's diagnostic armamentarium. To date, almost all echocardiographic parameters require time-consuming manual labeling and measurements by an experienced echocardiographer and exhibit significant variability, owing to the noisy and artifact-laden nature of echo images. For example, mitral inflow (MI) Doppler is used to assess left ventricular (LV) diastolic function, which is of paramount clinical importance to distinguish between different cardiac diseases. In the current work we present a fully automated workflow which leverages deep learning to a) label MI Doppler images acquired in an echo study, b) detect the envelope of MI Doppler signal, c) extract early and late filing (E and A wave) flow velocities and E-wave deceleration time from the envelope. We trained a variety of convolutional neural networks (CNN) models on 5544 images of 140 patients for predicting 24 image classes including MI Doppler images and obtained overall accuracy of 0.97 on 1737 images of 40 patients. Automated E and A wave velocity showed excellent correlation (Pearson R 0.99 and 0.98 respectively) and Bland Altman agreement (mean difference 0.06 and 0.05 m/s respectively and SD 0.03 for both) with the operator measurements. Deceleration time also showed good but lower correlation (Pearson R 0.82) and Bland-Altman agreement (mean difference: 34.1ms, SD: 30.9ms). These results demonstrate feasibility of Doppler echocardiography measurement automation and the promise of a fully automated echocardiography measurement package.
Adapting and evaluating a deep learning language model for clinical why-question answering
Nov 13, 2019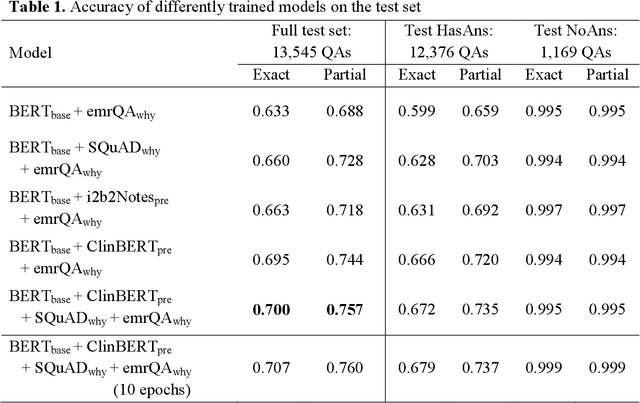


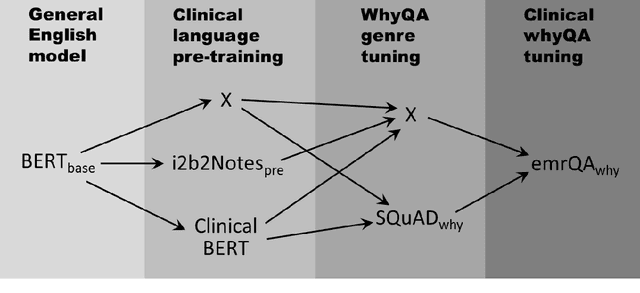
Objectives: To adapt and evaluate a deep learning language model for answering why-questions based on patient-specific clinical text. Materials and Methods: Bidirectional encoder representations from transformers (BERT) models were trained with varying data sources to perform SQuAD 2.0 style why-question answering (why-QA) on clinical notes. The evaluation focused on: 1) comparing the merits from different training data, 2) error analysis. Results: The best model achieved an accuracy of 0.707 (or 0.760 by partial match). Training toward customization for the clinical language helped increase 6% in accuracy. Discussion: The error analysis suggested that the model did not really perform deep reasoning and that clinical why-QA might warrant more sophisticated solutions. Conclusion: The BERT model achieved moderate accuracy in clinical why-QA and should benefit from the rapidly evolving technology. Despite the identified limitations, it could serve as a competent proxy for question-driven clinical information extraction.