 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting and evaluating a deep learning language model for clinical why-question answering
Nov 13, 2019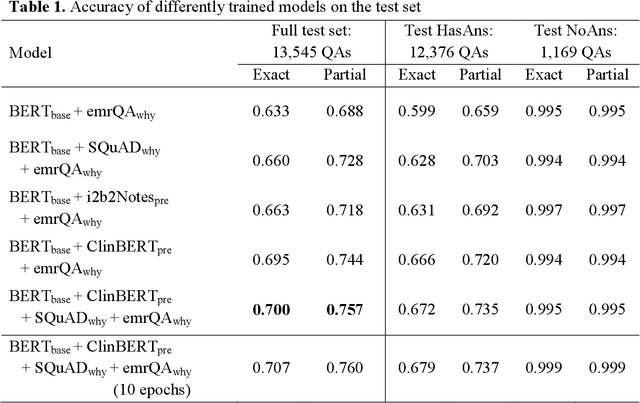


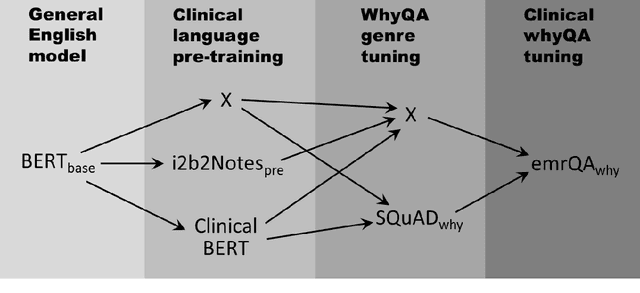
Objectives: To adapt and evaluate a deep learning language model for answering why-questions based on patient-specific clinical text. Materials and Methods: Bidirectional encoder representations from transformers (BERT) models were trained with varying data sources to perform SQuAD 2.0 style why-question answering (why-QA) on clinical notes. The evaluation focused on: 1) comparing the merits from different training data, 2) error analysis. Results: The best model achieved an accuracy of 0.707 (or 0.760 by partial match). Training toward customization for the clinical language helped increase 6% in accuracy. Discussion: The error analysis suggested that the model did not really perform deep reasoning and that clinical why-QA might warrant more sophisticated solutions. Conclusion: The BERT model achieved moderate accuracy in clinical why-QA and should benefit from the rapidly evolving technology. Despite the identified limitations, it could serve as a competent proxy for question-driven clinical information extraction.