 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJackpot: Optimal Budgeted Rejection Sampling for Extreme Actor-Policy Mismatch Reinforcement Learning
Feb 05, 2026Reinforcement learning (RL) for large language models (LLMs) remains expensive, particularly because the rollout is expensive. Decoupling rollout generation from policy optimization (e.g., leveraging a more efficient model to rollout) could enable substantial efficiency gains, yet doing so introduces a severe distribution mismatch that destabilizes learning. We propose Jackpot, a framework that leverages Optimal Budget Rejection Sampling (OBRS) to directly reduce the discrepancy between the rollout model and the evolving policy. Jackpot integrates a principled OBRS procedure, a unified training objective that jointly updates the policy and rollout models, and an efficient system implementation enabled by top-$k$ probability estimation and batch-level bias correction. Our theoretical analysis shows that OBRS consistently moves the rollout distribution closer to the target distribution under a controllable acceptance budget. Empirically, \sys substantially improves training stability compared to importance-sampling baselines, achieving performance comparable to on-policy RL when training Qwen3-8B-Base for up to 300 update steps of batchsize 64. Taken together, our results show that OBRS-based alignment brings us a step closer to practical and effective decoupling of rollout generation from policy optimization for RL for LLMs.
NFCDS: A Plug-and-Play Noise Frequency-Controlled Diffusion Sampling Strategy for Image Restoration
Jan 29, 2026Diffusion sampling-based Plug-and-Play (PnP) methods produce images with high perceptual quality but often suffer from reduced data fidelity, primarily due to the noise introduced during reverse diffusion. To address this trade-off, we propose Noise Frequency-Controlled Diffusion Sampling (NFCDS), a spectral modulation mechanism for reverse diffusion noise. We show that the fidelity-perception conflict can be fundamentally understood through noise frequency: low-frequency components induce blur and degrade fidelity, while high-frequency components drive detail generation. Based on this insight, we design a Fourier-domain filter that progressively suppresses low-frequency noise and preserves high-frequency content. This controlled refinement injects a data-consistency prior directly into sampling, enabling fast convergence to results that are both high-fidelity and perceptually convincing--without additional training. As a PnP module, NFCDS seamlessly integrates into existing diffusion-based restoration frameworks and improves the fidelity-perception balance across diverse zero-shot tasks.
Distilling the Thought, Watermarking the Answer: A Principle Semantic Guided Watermark for Large Reasoning Models
Jan 08, 2026Reasoning Large Language Models (RLLMs) excelling in complex tasks present unique challenges for digital watermarking, as existing methods often disrupt logical coherence or incur high computational costs. Token-based watermarking techniques can corrupt the reasoning flow by applying pseudo-random biases, while semantic-aware approaches improve quality but introduce significant latency or require auxiliary models. This paper introduces ReasonMark, a novel watermarking framework specifically designed for reasoning-intensive LLMs. Our approach decouples generation into an undisturbed Thinking Phase and a watermarked Answering Phase. We propose a Criticality Score to identify semantically pivotal tokens from the reasoning trace, which are distilled into a Principal Semantic Vector (PSV). The PSV then guides a semantically-adaptive mechanism that modulates watermark strength based on token-PSV alignment, ensuring robustness without compromising logical integrity. Extensive experiments show ReasonMark surpasses state-of-the-art methods by reducing text Perplexity by 0.35, increasing translation BLEU score by 0.164, and raising mathematical accuracy by 0.67 points. These advancements are achieved alongside a 0.34% higher watermark detection AUC and stronger robustness to attacks, all with a negligible increase in latency. This work enables the traceable and trustworthy deployment of reasoning LLMs in real-world applications.
Towards a Unified View of Large Language Model Post-Training
Sep 04, 2025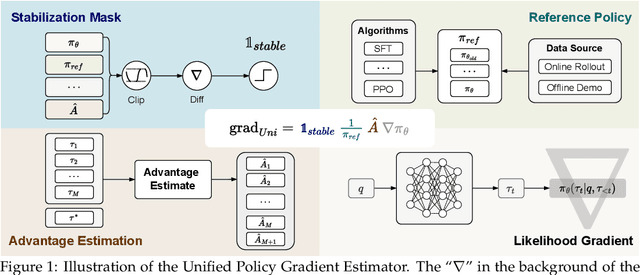

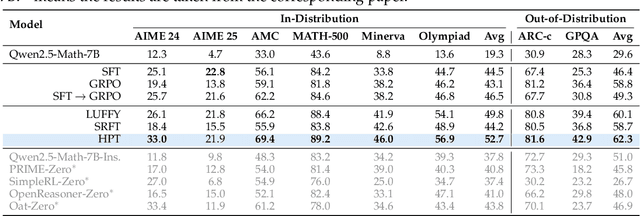
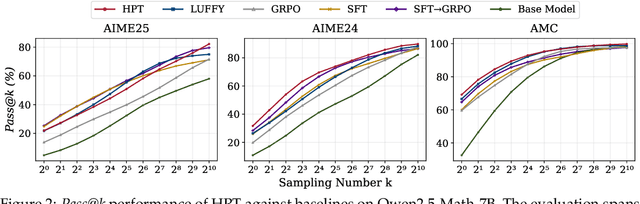
Two major sources of training data exist for post-training modern language models: online (model-generated rollouts) data, and offline (human or other-model demonstrations) data. These two types of data are typically used by approaches like Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT), respectively. In this paper, we show that these approaches are not in contradiction, but are instances of a single optimization process. We derive a Unified Policy Gradient Estimator, and present the calculations of a wide spectrum of post-training approaches as the gradient of a common objective under different data distribution assumptions and various bias-variance tradeoffs. The gradient estimator is constructed with four interchangeable parts: stabilization mask, reference policy denominator, advantage estimate, and likelihood gradient. Motivated by our theoretical findings, we propose Hybrid Post-Training (HPT), an algorithm that dynamically selects different training signals. HPT is designed to yield both effective exploitation of demonstration and stable exploration without sacrificing learned reasoning patterns. We provide extensive experiments and ablation studies to verify the effectiveness of our unified theoretical framework and HPT. Across six mathematical reasoning benchmarks and two out-of-distribution suites, HPT consistently surpasses strong baselines across models of varying scales and families.
Zero-Shot Solving of Imaging Inverse Problems via Noise-Refined Likelihood Guided Diffusion Models
Jun 16, 2025

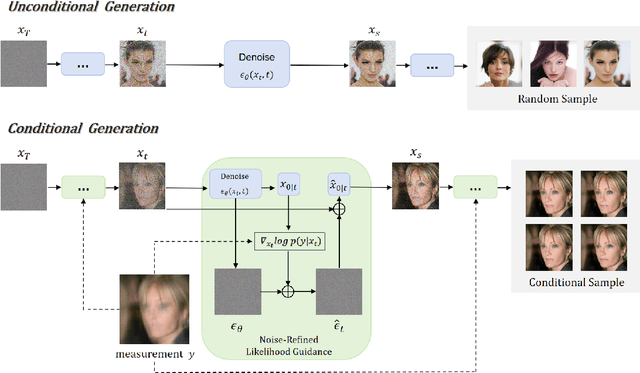
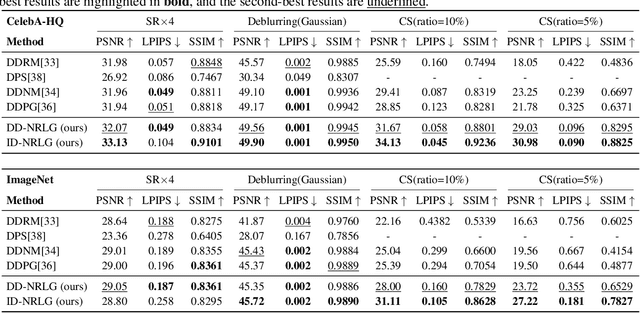
Diffusion models have achieved remarkable success in imaging inverse problems owing to their powerful generative capabilities. However, existing approaches typically rely on models trained for specific degradation types, limiting their generalizability to various degradation scenarios. To address this limitation, we propose a zero-shot framework capable of handling various imaging inverse problems without model retraining. We introduce a likelihood-guided noise refinement mechanism that derives a closed-form approximation of the likelihood score, simplifying score estimation and avoiding expensive gradient computations. This estimated score is subsequently utilized to refine the model-predicted noise, thereby better aligning the restoration process with the generative framework of diffusion models. In addition, we integrate the Denoising Diffusion Implicit Models (DDIM) sampling strategy to further improve inference efficiency. The proposed mechanism can be applied to both optimization-based and sampling-based schemes, providing an effective and flexible zero-shot solution for imaging inverse problems. Extensive experiments demonstrate that our method achieves superior performance across multiple inverse problems, particularly in compressive sensing, delivering high-quality reconstructions even at an extremely low sampling rate (5%).
Multiverse: Your Language Models Secretly Decide How to Parallelize and Merge Generation
Jun 11, 2025Autoregressive Large Language Models (AR-LLMs) frequently exhibit implicit parallelism in sequential generation. Inspired by this, we introduce Multiverse, a new generative model that enables natively parallel generation. Multiverse internalizes a MapReduce paradigm, generating automatically through three stages: (i) a Map stage for adaptive task decomposition, (ii) a Process stage for parallel subtask execution, and (iii) a Reduce stage for lossless result synthesis. Next, we build a real-world Multiverse reasoning model with co-design of data, algorithm, and system, enabling rapid and seamless transfer from frontier AR-LLMs. Starting from sequential reasoning chains, we create Multiverse 1K by converting them into structured training data using an automated LLM-assisted pipeline, avoiding costly human annotations. Algorithmically, we design Multiverse Attention to separate parallel reasoning steps while keeping compatibility with causal attention for efficient training. Systematically, we implement Multiverse Engine to enable parallel inference. It features a dedicated scheduler that dynamically switches between sequential and parallel generation, triggered directly by the model. After a 3-hour fine-tuning with 1K examples, our Multiverse-32B stands as the only open-sourced non-AR model achieving performance on par with leading AR-LLMs of the same scale, evidenced by AIME24 & 25 scores of 54% and 46%, respectively. Moreover, our budget control experiments show that Multiverse-32B exhibits superior scaling, outperforming AR-LLMs by 1.87% on average using the same context length. Such scaling further leads to practical efficiency gain, achieving up to 2x speedup across varying batch sizes. We have open-sourced the entire Multiverse ecosystem, including data, model weights, engine, supporting tools, as well as complete data curation prompts and detailed training and evaluation recipes.
AutoL2S: Auto Long-Short Reasoning for Efficient Large Language Models
May 28, 2025The reasoning-capable large language models (LLMs) demonstrate strong performance on complex reasoning tasks but often suffer from overthinking, generating unnecessarily long chain-of-thought (CoT) reasoning paths for easy reasoning questions, thereby increasing inference cost and latency. Recent approaches attempt to address this challenge by manually deciding when to apply long or short reasoning. However, they lack the flexibility to adapt CoT length dynamically based on question complexity. In this paper, we propose Auto Long-Short Reasoning (AutoL2S), a dynamic and model-agnostic framework that enables LLMs to dynamically compress their generated reasoning path based on the complexity of the reasoning question. AutoL2S enables a learned paradigm, in which LLMs themselves can decide when longer reasoning is necessary and when shorter reasoning suffices, by training on data annotated with our proposed method, which includes both long and short CoT paths and a special <EASY> token. We then use <EASY> token to indicate when the model can skip generating lengthy CoT reasoning. This proposed annotation strategy can enhance the LLMs' ability to generate shorter CoT reasoning paths with improved quality after training. Extensive evaluation results show that AutoL2S reduces the length of reasoning generation by up to 57% without compromising performance, demonstrating the effectiveness of AutoL2S for scalable and efficient LLM reasoning.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Mar 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved performance in System-2 reasoning domains like mathematics and programming by harnessing supervised fine-tuning (SFT) and reinforcement learning (RL) techniques to enhance the Chain-of-Thought (CoT) reasoning. However, while longer CoT reasoning sequences improve performance, they also introduce significant computational overhead due to verbose and redundant outputs, known as the "overthinking phenomenon". In this paper, we provide the first structured survey to systematically investigate and explore the current progress toward achieving efficient reasoning in LLMs. Overall, relying on the inherent mechanism of LLMs, we categorize existing works into several key directions: (1) model-based efficient reasoning, which considers optimizing full-length reasoning models into more concise reasoning models or directly training efficient reasoning models; (2) reasoning output-based efficient reasoning, which aims to dynamically reduce reasoning steps and length during inference; (3) input prompts-based efficient reasoning, which seeks to enhance reasoning efficiency based on input prompt properties such as difficulty or length control. Additionally, we introduce the use of efficient data for training reasoning models, explore the reasoning capabilities of small language models, and discuss evaluation methods and benchmarking.
GSM-Infinite: How Do Your LLMs Behave over Infinitely Increasing Context Length and Reasoning Complexity?
Feb 07, 2025Long-context large language models (LLMs) have recently shown strong performance in information retrieval and long-document QA. However, to tackle the most challenging intellectual problems, LLMs must reason effectively in long and complex contexts (e.g., frontier mathematical research). Studying how LLMs handle increasing reasoning complexity and context length is essential, yet existing benchmarks lack a solid basis for quantitative evaluation. Inspired by the abstraction of GSM-8K problems as computational graphs, and the ability to introduce noise by adding unnecessary nodes and edges, we develop a grade school math problem generator capable of producing arithmetic problems with infinite difficulty and context length under fine-grained control. Using our newly synthesized GSM-Infinite benchmark, we comprehensively evaluate existing LLMs. We find a consistent sigmoid decline in reasoning performance as complexity increases, along with a systematic inference scaling trend: exponentially increasing inference computation yields only linear performance gains. These findings underscore the fundamental limitations of current long-context LLMs and the key challenges in scaling reasoning capabilities. Our GSM-Infinite benchmark provides a scalable and controllable testbed for systematically studying and advancing LLM reasoning in long and complex contexts.