 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntraSlice: Towards High-Performance Structural Pruning with Block-Intra PCA for LLMs
Feb 02, 2026Large Language Models (LLMs) achieve strong performance across diverse tasks but face deployment challenges due to their massive size. Structured pruning offers acceleration benefits but leads to significant performance degradation. Recent PCA-based pruning methods have alleviated this issue by retaining key activation components, but are only applied between modules in order to fuse the transformation matrix, which introduces extra parameters and severely disrupts activation distributions due to residual connections. To address these issues, we propose IntraSlice, a framework that applies block-wise module-intra PCA compression pruning. By leveraging the structural characteristics of Transformer modules, we design an approximate PCA method whose transformation matrices can be fully fused into the model without additional parameters. We also introduce a PCA-based global pruning ratio estimator that further considers the distribution of compressed activations, building on conventional module importance. We validate our method on Llama2, Llama3, and Phi series across various language benchmarks. Experimental results demonstrate that our approach achieves superior compression performance compared to recent baselines at the same compression ratio or inference speed.
NFCDS: A Plug-and-Play Noise Frequency-Controlled Diffusion Sampling Strategy for Image Restoration
Jan 29, 2026Diffusion sampling-based Plug-and-Play (PnP) methods produce images with high perceptual quality but often suffer from reduced data fidelity, primarily due to the noise introduced during reverse diffusion. To address this trade-off, we propose Noise Frequency-Controlled Diffusion Sampling (NFCDS), a spectral modulation mechanism for reverse diffusion noise. We show that the fidelity-perception conflict can be fundamentally understood through noise frequency: low-frequency components induce blur and degrade fidelity, while high-frequency components drive detail generation. Based on this insight, we design a Fourier-domain filter that progressively suppresses low-frequency noise and preserves high-frequency content. This controlled refinement injects a data-consistency prior directly into sampling, enabling fast convergence to results that are both high-fidelity and perceptually convincing--without additional training. As a PnP module, NFCDS seamlessly integrates into existing diffusion-based restoration frameworks and improves the fidelity-perception balance across diverse zero-shot tasks.
Block Rotation is All You Need for MXFP4 Quantization
Nov 06, 2025Large language models (LLMs) have achieved remarkable success, but their rapidly growing scale imposes prohibitive costs in memory, computation, and energy. Post-training quantization (PTQ) is a promising solution for efficient deployment, yet achieving accurate W4A4 quantization remains an open challenge. While most existing methods are designed for INT4 formats, the emergence of MXFP4 -- a new FP4 format with various hardware support (NVIDIA, AMD, Intel)-- raises questions about the applicability of current techniques. In this work, we establish a comprehensive benchmark of PTQ methods under the MXFP4 format. Through systematic evaluation, we find that methods like GPTQ consistently deliver strong performance, whereas rotation-based approaches, which are almost used by all state-of-the-art approaches, suffer from severe incompatibility with MXFP4. We further provide the first in-depth analysis of this conflict, tracing its root to a fundamental mismatch between MXFP4's PoT (power-of-two) block scaling and the redistribution of outlier energy via global rotation. Building on this insight, we propose a simple yet effective block rotation strategy that adapts rotation-based methods to MXFP4, leading to substantial accuracy improvements across diverse LLMs. Our findings not only offer clear guidance for practitioners but also set a foundation for advancing PTQ research under emerging low-precision formats.
DartQuant: Efficient Rotational Distribution Calibration for LLM Quantization
Nov 06, 2025Quantization plays a crucial role in accelerating the inference of large-scale models, and rotational matrices have been shown to effectively improve quantization performance by smoothing outliers. However, end-to-end fine-tuning of rotational optimization algorithms incurs high computational costs and is prone to overfitting. To address this challenge, we propose an efficient distribution-aware rotational calibration method, DartQuant, which reduces the complexity of rotational optimization by constraining the distribution of the activations after rotation. This approach also effectively reduces reliance on task-specific losses, thereby mitigating the risk of overfitting. Additionally, we introduce the QR-Orth optimization scheme, which replaces expensive alternating optimization with a more efficient solution. In a variety of model quantization experiments, DartQuant demonstrates superior performance. Compared to existing methods, it achieves 47$\times$ acceleration and 10$\times$ memory savings for rotational optimization on a 70B model. Furthermore, it is the first to successfully complete rotational calibration for a 70B model on a single 3090 GPU, making quantization of large language models feasible in resource-constrained environments. Code is available at https://github.com/CAS-CLab/DartQuant.git.
Zero-Shot Solving of Imaging Inverse Problems via Noise-Refined Likelihood Guided Diffusion Models
Jun 16, 2025

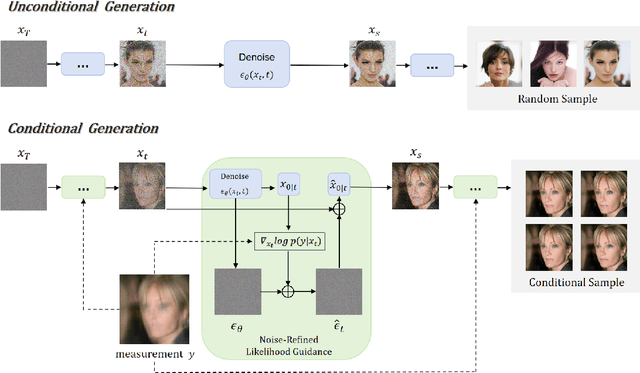
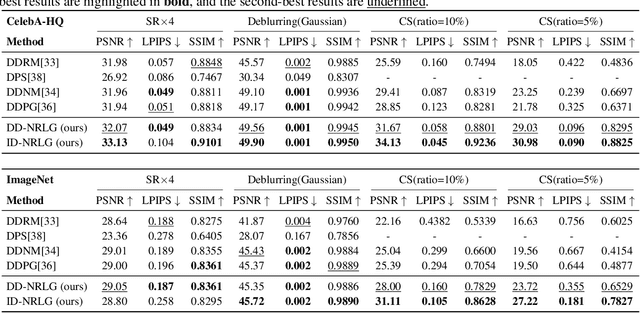
Diffusion models have achieved remarkable success in imaging inverse problems owing to their powerful generative capabilities. However, existing approaches typically rely on models trained for specific degradation types, limiting their generalizability to various degradation scenarios. To address this limitation, we propose a zero-shot framework capable of handling various imaging inverse problems without model retraining. We introduce a likelihood-guided noise refinement mechanism that derives a closed-form approximation of the likelihood score, simplifying score estimation and avoiding expensive gradient computations. This estimated score is subsequently utilized to refine the model-predicted noise, thereby better aligning the restoration process with the generative framework of diffusion models. In addition, we integrate the Denoising Diffusion Implicit Models (DDIM) sampling strategy to further improve inference efficiency. The proposed mechanism can be applied to both optimization-based and sampling-based schemes, providing an effective and flexible zero-shot solution for imaging inverse problems. Extensive experiments demonstrate that our method achieves superior performance across multiple inverse problems, particularly in compressive sensing, delivering high-quality reconstructions even at an extremely low sampling rate (5%).
Self-Learning Hyperspectral and Multispectral Image Fusion via Adaptive Residual Guided Subspace Diffusion Model
May 17, 2025Hyperspectral and multispectral image (HSI-MSI) fusion involves combining a low-resolution hyperspectral image (LR-HSI) with a high-resolution multispectral image (HR-MSI) to generate a high-resolution hyperspectral image (HR-HSI). Most deep learning-based methods for HSI-MSI fusion rely on large amounts of hyperspectral data for supervised training, which is often scarce in practical applications. In this paper, we propose a self-learning Adaptive Residual Guided Subspace Diffusion Model (ARGS-Diff), which only utilizes the observed images without any extra training data. Specifically, as the LR-HSI contains spectral information and the HR-MSI contains spatial information, we design two lightweight spectral and spatial diffusion models to separately learn the spectral and spatial distributions from them. Then, we use these two models to reconstruct HR-HSI from two low-dimensional components, i.e, the spectral basis and the reduced coefficient, during the reverse diffusion process. Furthermore, we introduce an Adaptive Residual Guided Module (ARGM), which refines the two components through a residual guided function at each sampling step, thereby stabilizing the sampling process. Extensive experimental results demonstrate that ARGS-Diff outperforms existing state-of-the-art methods in terms of both performance and computational efficiency in the field of HSI-MSI fusion. Code is available at https://github.com/Zhu1116/ARGS-Diff.
Explicit Change Relation Learning for Change Detection in VHR Remote Sensing Images
Nov 14, 2023



Change detection has always been a concerned task in the interpretation of remote sensing images. It is essentially a unique binary classification task with two inputs, and there is a change relationship between these two inputs. At present, the mining of change relationship features is usually implicit in the network architectures that contain single-branch or two-branch encoders. However, due to the lack of artificial prior design for change relationship features, these networks cannot learn enough change semantic information and lose more accurate change detection performance. So we propose a network architecture NAME for the explicit mining of change relation features. In our opinion, the change features of change detection should be divided into pre-changed image features, post-changed image features and change relation features. In order to fully mine these three kinds of change features, we propose the triple branch network combining the transformer and convolutional neural network (CNN) to extract and fuse these change features from two perspectives of global information and local information, respectively. In addition, we design the continuous change relation (CCR) branch to further obtain the continuous and detail change relation features to improve the change discrimination capability of the model. The experimental results show that our network performs better, in terms of F1, IoU, and OA, than those of the existing advanced networks for change detection on four public very high-resolution (VHR) remote sensing datasets. Our source code is available at https://github.com/DalongZ/NAME.
SwinV2DNet: Pyramid and Self-Supervision Compounded Feature Learning for Remote Sensing Images Change Detection
Aug 22, 2023



Among the current mainstream change detection networks, transformer is deficient in the ability to capture accurate low-level details, while convolutional neural network (CNN) is wanting in the capacity to understand global information and establish remote spatial relationships. Meanwhile, both of the widely used early fusion and late fusion frameworks are not able to well learn complete change features. Therefore, based on swin transformer V2 (Swin V2) and VGG16, we propose an end-to-end compounded dense network SwinV2DNet to inherit the advantages of both transformer and CNN and overcome the shortcomings of existing networks in feature learning. Firstly, it captures the change relationship features through the densely connected Swin V2 backbone, and provides the low-level pre-changed and post-changed features through a CNN branch. Based on these three change features, we accomplish accurate change detection results. Secondly, combined with transformer and CNN, we propose mixed feature pyramid (MFP) which provides inter-layer interaction information and intra-layer multi-scale information for complete feature learning. MFP is a plug and play module which is experimentally proven to be also effective in other change detection networks. Further more, we impose a self-supervision strategy to guide a new CNN branch, which solves the untrainable problem of the CNN branch and provides the semantic change information for the features of encoder. The state-of-the-art (SOTA) change detection scores and fine-grained change maps were obtained compared with other advanced methods on four commonly used public remote sensing datasets. The code is available at https://github.com/DalongZ/SwinV2DNet.
ReAFFPN: Rotation-equivariant Attention Feature Fusion Pyramid Networks for Aerial Object Detection
Oct 17, 2022

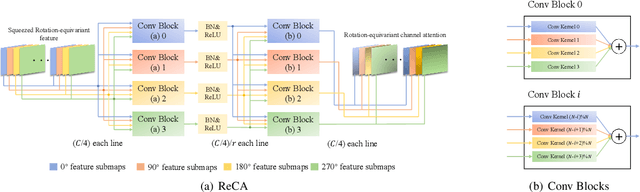

This paper proposes a Rotation-equivariant Attention Feature Fusion Pyramid Networks for Aerial Object Detection named ReAFFPN. ReAFFPN aims at improving the effect of rotation-equivariant features fusion between adjacent layers which suffers from the semantic and scale discontinuity. Due to the particularity of rotational equivariant convolution, general methods are unable to achieve their original effect while ensuring rotation equivariance of the network. To solve this problem, we design a new Rotation-equivariant Channel Attention which has the ability to both generate channel attention and keep rotation equivariance. Then we embed a new channel attention function into Iterative Attentional Feature Fusion (iAFF) module to realize Rotation-equivariant Attention Feature Fusion. Experimental results demonstrate that ReAFFPN achieves a better rotation-equivariant feature fusion ability and significantly improve the accuracy of the Rotation-equivariant Convolutional Networks.
Pyramidal Dense Attention Networks for Lightweight Image Super-Resolution
Jun 13, 2021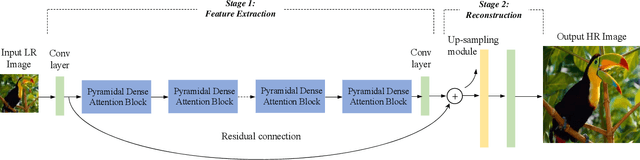
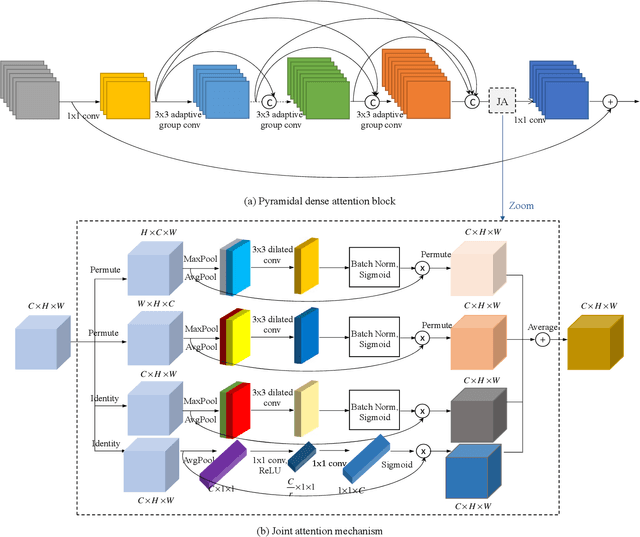

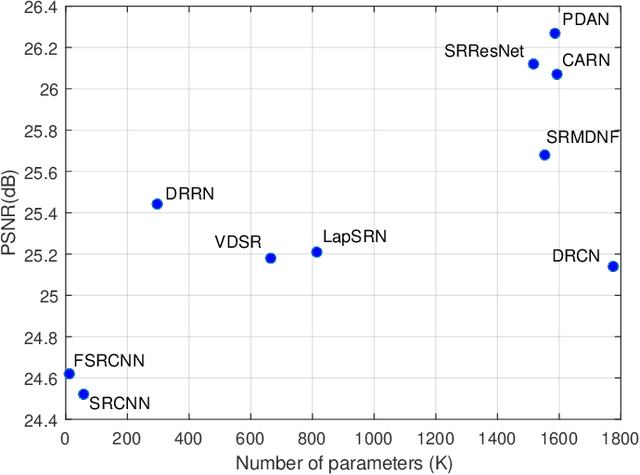
Recently, deep convolutional neural network methods have achieved an excellent performance in image superresolution (SR), but they can not be easily applied to embedded devices due to large memory cost. To solve this problem, we propose a pyramidal dense attention network (PDAN) for lightweight image super-resolution in this paper. In our method, the proposed pyramidal dense learning can gradually increase the width of the densely connected layer inside a pyramidal dense block to extract deep features efficiently. Meanwhile, the adaptive group convolution that the number of groups grows linearly with dense convolutional layers is introduced to relieve the parameter explosion. Besides, we also present a novel joint attention to capture cross-dimension interaction between the spatial dimensions and channel dimension in an efficient way for providing rich discriminative feature representations. Extensive experimental results show that our method achieves superior performance in comparison with the state-of-the-art lightweight SR methods.