 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Learning Hyperspectral and Multispectral Image Fusion via Adaptive Residual Guided Subspace Diffusion Model
May 17, 2025Hyperspectral and multispectral image (HSI-MSI) fusion involves combining a low-resolution hyperspectral image (LR-HSI) with a high-resolution multispectral image (HR-MSI) to generate a high-resolution hyperspectral image (HR-HSI). Most deep learning-based methods for HSI-MSI fusion rely on large amounts of hyperspectral data for supervised training, which is often scarce in practical applications. In this paper, we propose a self-learning Adaptive Residual Guided Subspace Diffusion Model (ARGS-Diff), which only utilizes the observed images without any extra training data. Specifically, as the LR-HSI contains spectral information and the HR-MSI contains spatial information, we design two lightweight spectral and spatial diffusion models to separately learn the spectral and spatial distributions from them. Then, we use these two models to reconstruct HR-HSI from two low-dimensional components, i.e, the spectral basis and the reduced coefficient, during the reverse diffusion process. Furthermore, we introduce an Adaptive Residual Guided Module (ARGM), which refines the two components through a residual guided function at each sampling step, thereby stabilizing the sampling process. Extensive experimental results demonstrate that ARGS-Diff outperforms existing state-of-the-art methods in terms of both performance and computational efficiency in the field of HSI-MSI fusion. Code is available at https://github.com/Zhu1116/ARGS-Diff.
A Spectral Diffusion Prior for Hyperspectral Image Super-Resolution
Nov 15, 2023



Fusion-based hyperspectral image (HSI) super-resolution aims to produce a high-spatial-resolution HSI by fusing a low-spatial-resolution HSI and a high-spatial-resolution multispectral image. Such a HSI super-resolution process can be modeled as an inverse problem, where the prior knowledge is essential for obtaining the desired solution. Motivated by the success of diffusion models, we propose a novel spectral diffusion prior for fusion-based HSI super-resolution. Specifically, we first investigate the spectrum generation problem and design a spectral diffusion model to model the spectral data distribution. Then, in the framework of maximum a posteriori, we keep the transition information between every two neighboring states during the reverse generative process, and thereby embed the knowledge of trained spectral diffusion model into the fusion problem in the form of a regularization term. At last, we treat each generation step of the final optimization problem as its subproblem, and employ the Adam to solve these subproblems in a reverse sequence. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach. The code of the proposed approach will be available on https://github.com/liuofficial/SDP.
Explicit Change Relation Learning for Change Detection in VHR Remote Sensing Images
Nov 14, 2023



Change detection has always been a concerned task in the interpretation of remote sensing images. It is essentially a unique binary classification task with two inputs, and there is a change relationship between these two inputs. At present, the mining of change relationship features is usually implicit in the network architectures that contain single-branch or two-branch encoders. However, due to the lack of artificial prior design for change relationship features, these networks cannot learn enough change semantic information and lose more accurate change detection performance. So we propose a network architecture NAME for the explicit mining of change relation features. In our opinion, the change features of change detection should be divided into pre-changed image features, post-changed image features and change relation features. In order to fully mine these three kinds of change features, we propose the triple branch network combining the transformer and convolutional neural network (CNN) to extract and fuse these change features from two perspectives of global information and local information, respectively. In addition, we design the continuous change relation (CCR) branch to further obtain the continuous and detail change relation features to improve the change discrimination capability of the model. The experimental results show that our network performs better, in terms of F1, IoU, and OA, than those of the existing advanced networks for change detection on four public very high-resolution (VHR) remote sensing datasets. Our source code is available at https://github.com/DalongZ/NAME.
SwinV2DNet: Pyramid and Self-Supervision Compounded Feature Learning for Remote Sensing Images Change Detection
Aug 22, 2023



Among the current mainstream change detection networks, transformer is deficient in the ability to capture accurate low-level details, while convolutional neural network (CNN) is wanting in the capacity to understand global information and establish remote spatial relationships. Meanwhile, both of the widely used early fusion and late fusion frameworks are not able to well learn complete change features. Therefore, based on swin transformer V2 (Swin V2) and VGG16, we propose an end-to-end compounded dense network SwinV2DNet to inherit the advantages of both transformer and CNN and overcome the shortcomings of existing networks in feature learning. Firstly, it captures the change relationship features through the densely connected Swin V2 backbone, and provides the low-level pre-changed and post-changed features through a CNN branch. Based on these three change features, we accomplish accurate change detection results. Secondly, combined with transformer and CNN, we propose mixed feature pyramid (MFP) which provides inter-layer interaction information and intra-layer multi-scale information for complete feature learning. MFP is a plug and play module which is experimentally proven to be also effective in other change detection networks. Further more, we impose a self-supervision strategy to guide a new CNN branch, which solves the untrainable problem of the CNN branch and provides the semantic change information for the features of encoder. The state-of-the-art (SOTA) change detection scores and fine-grained change maps were obtained compared with other advanced methods on four commonly used public remote sensing datasets. The code is available at https://github.com/DalongZ/SwinV2DNet.
ReAFFPN: Rotation-equivariant Attention Feature Fusion Pyramid Networks for Aerial Object Detection
Oct 17, 2022

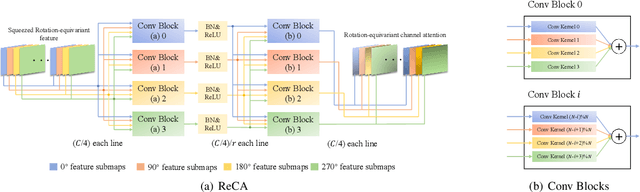

This paper proposes a Rotation-equivariant Attention Feature Fusion Pyramid Networks for Aerial Object Detection named ReAFFPN. ReAFFPN aims at improving the effect of rotation-equivariant features fusion between adjacent layers which suffers from the semantic and scale discontinuity. Due to the particularity of rotational equivariant convolution, general methods are unable to achieve their original effect while ensuring rotation equivariance of the network. To solve this problem, we design a new Rotation-equivariant Channel Attention which has the ability to both generate channel attention and keep rotation equivariance. Then we embed a new channel attention function into Iterative Attentional Feature Fusion (iAFF) module to realize Rotation-equivariant Attention Feature Fusion. Experimental results demonstrate that ReAFFPN achieves a better rotation-equivariant feature fusion ability and significantly improve the accuracy of the Rotation-equivariant Convolutional Networks.
Model Inspired Autoencoder for Unsupervised Hyperspectral Image Super-Resolution
Oct 22, 2021
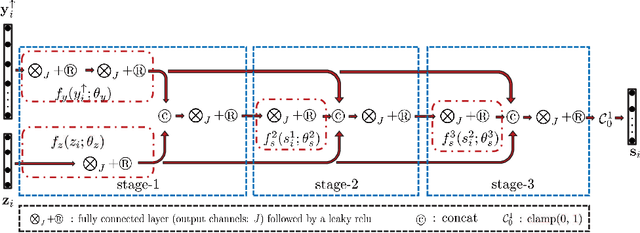
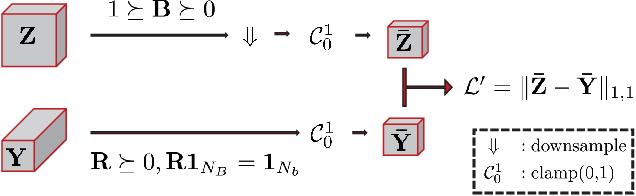
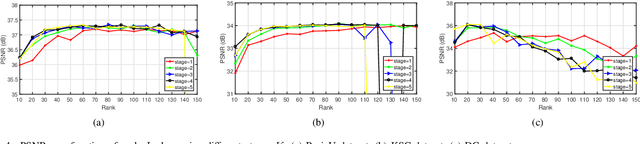
This paper focuses on hyperspectral image (HSI) super-resolution that aims to fuse a low-spatial-resolution HSI and a high-spatial-resolution multispectral image to form a high-spatial-resolution HSI (HR-HSI). Existing deep learning-based approaches are mostly supervised that rely on a large number of labeled training samples, which is unrealistic. The commonly used model-based approaches are unsupervised and flexible but rely on hand-craft priors. Inspired by the specific properties of model, we make the first attempt to design a model inspired deep network for HSI super-resolution in an unsupervised manner. This approach consists of an implicit autoencoder network built on the target HR-HSI that treats each pixel as an individual sample. The nonnegative matrix factorization (NMF) of the target HR-HSI is integrated into the autoencoder network, where the two NMF parts, spectral and spatial matrices, are treated as decoder parameters and hidden outputs respectively. In the encoding stage, we present a pixel-wise fusion model to estimate hidden outputs directly, and then reformulate and unfold the model's algorithm to form the encoder network. With the specific architecture, the proposed network is similar to a manifold prior-based model, and can be trained patch by patch rather than the entire image. Moreover, we propose an additional unsupervised network to estimate the point spread function and spectral response function. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach.