 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatMind: A Structure-Activity Knowledge-Driven Generative Foundation Model for Materials Science
Jun 05, 2026Progress in AI-driven crystal materials science has so far been carried by narrow architectures purpose-built for individual tasks -- graph neural networks for property prediction, diffusion and flow-matching models for crystal generation -- each excelling within its niche yet unable to act as a shared backbone across the full spectrum of materials problems. Generative large language models offer a fundamentally different paradigm, in which structural representation, quantitative prediction, and structure-activity reasoning can be unified within one model, but the materials community has yet to see this paradigm realized at a level competitive with established narrow specialists. Here we present MatMind, a generative foundation model purpose-built for crystal materials science under this paradigm, developed through the coordinated activation of structure-activity knowledge and physics-informed feedback within a progressive training framework -- combining structure-activity knowledge injection, a dual-head architecture that jointly trains language reasoning and numerical regression in a shared representation space, and multi-objective physics-informed reinforcement learning over stability, novelty, and structural diversity. Across three task families, MatMind attains the lowest mean absolute error on energy above hull, bulk modulus, and band gap -- surpassing graph neural network predictors purpose-built for these tasks -- reaches an S.U.N. rate of 65.3% on unconditional crystal generation, and achieves a comparable multiplicative improvement on magnetization-density-conditioned generation, where only 21 positive samples exist within over 600000 training entries. By matching or surpassing narrow specialists on their own ground while operating within a single unified model, MatMind shows that the LLM-based paradigm can serve as a viable backbone for crystal materials science going forward.
CT-Guided Spatially-varying Regularization for Voxel-Wise Deformable Whole-Body PET Registration
Apr 24, 2026Whole-body Positron Emission Tomography (PET) registration is essential for multi-parametric tumor characterization and assessment of metastatic disease progression. In deep learning-based deformable registration, the dense displacement field (DDF) regularizer is crucial for stabilizing optimization and preventing unrealistic deformations in large 3D volumes. A key challenge in whole-body deformable registration is anatomical heterogeneity, rigid structures (e.g., bones) should undergo stronger regularization, whereas soft tissues require more flexible deformation and weaker constraints. In this work, we propose a simple yet effective CT-guided spatially-varying regularization strategy for whole-body cross-tracer deformable PET registration. The key idea is to use the paired CT volume from the PET/CT acquisition to construct a voxel-wise regularization map for the DDF, replacing the conventional single global regularization weight. This yields anatomy-adaptive regularization strength across rigid and soft tissues. The proposed method is evaluated on a real clinical cross-tracer PET/CT dataset of 296 patients involving 18F-PSMA and 18F-FDG, showing that the proposed method achieves statistically significant improvements over weakly-supervised registration baseline in both whole-body registration performance and organ-wise alignment.
LLM-Assisted Automatic Dispatching Rule Design for Dynamic Flexible Assembly Flow Shop Scheduling
Jan 22, 2026Dynamic multi-product delivery environments demand rapid coordination of part completion and product-level kitting within hybrid processing and assembly systems to satisfy strict hierarchical supply constraints. The flexible assembly flow shop scheduling problem formally defines dependencies for multi-stage kitting, yet dynamic variants make designing integrated scheduling rules under multi-level time coupling highly challenging. Existing automated heuristic design methods, particularly genetic programming constrained to fixed terminal symbol sets, struggle to capture and leverage dynamic uncertainties and hierarchical dependency information under transient decision states. This study develops an LLM-assisted Dynamic Rule Design framework (LLM4DRD) that automatically evolves integrated online scheduling rules adapted to scheduling features. Firstly, multi-stage processing and assembly supply decisions are transformed into feasible directed edge orderings based on heterogeneous graph. Then, an elite knowledge guided initialization embeds advanced design expertise into initial rules to enhance initial quality. Additionally, a dual-expert mechanism is introduced in which LLM-A evolutionary code to generate candidate rules and LLM-S conducts scheduling evaluation, while dynamic feature-fitting rule evolution combined with hybrid evaluation enables continuous improvement and extracts adaptive rules with strong generalization capability. A series of experiments are conducted to validate the effectiveness of the method. The average tardiness of LLM4DRD is 3.17-12.39% higher than state-of-the-art methods in 20 practical instances used for training and testing, respectively. In 24 scenarios with different resource configurations, order loads, and disturbance levels totaling 480 instances, it achieves 11.10% higher performance than the second best competitor, exhibiting excellent robustness.
HTD-Mamba: Efficient Hyperspectral Target Detection with Pyramid State Space Model
Jul 09, 2024



Hyperspectral target detection (HTD) identifies objects of interest from complex backgrounds at the pixel level, playing a vital role in Earth observation. However, HTD faces challenges due to limited prior knowledge and spectral variations, leading to underfitting models and unreliable performance. To address these challenges, this paper proposes an efficient self-supervised HTD method with a pyramid state space model (SSM), named HTD-Mamba, which employs spectrally contrastive learning to distinguish between target and background based on the similarity measurement of intrinsic features. Specifically, to obtain sufficient training samples and leverage spatial contextual information, we propose a spatial-encoded spectral augmentation technique that encodes all surrounding pixels within a patch into a transformed view of the central pixel. Additionally, to explore global band correlations, we divide pixels into continuous group-wise spectral embeddings and introduce Mamba to HTD for the first time to model long-range dependencies of the spectral sequence with linear complexity. Furthermore, to alleviate spectral variation and enhance robust representation, we propose a pyramid SSM as a backbone to capture and fuse multiresolution spectral-wise intrinsic features. Extensive experiments conducted on four public datasets demonstrate that the proposed method outperforms state-of-the-art methods in both quantitative and qualitative evaluations. Code is available at \url{https://github.com/shendb2022/HTD-Mamba}.
A Spectral Diffusion Prior for Hyperspectral Image Super-Resolution
Nov 15, 2023



Fusion-based hyperspectral image (HSI) super-resolution aims to produce a high-spatial-resolution HSI by fusing a low-spatial-resolution HSI and a high-spatial-resolution multispectral image. Such a HSI super-resolution process can be modeled as an inverse problem, where the prior knowledge is essential for obtaining the desired solution. Motivated by the success of diffusion models, we propose a novel spectral diffusion prior for fusion-based HSI super-resolution. Specifically, we first investigate the spectrum generation problem and design a spectral diffusion model to model the spectral data distribution. Then, in the framework of maximum a posteriori, we keep the transition information between every two neighboring states during the reverse generative process, and thereby embed the knowledge of trained spectral diffusion model into the fusion problem in the form of a regularization term. At last, we treat each generation step of the final optimization problem as its subproblem, and employ the Adam to solve these subproblems in a reverse sequence. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach. The code of the proposed approach will be available on https://github.com/liuofficial/SDP.
Model Inspired Autoencoder for Unsupervised Hyperspectral Image Super-Resolution
Oct 22, 2021
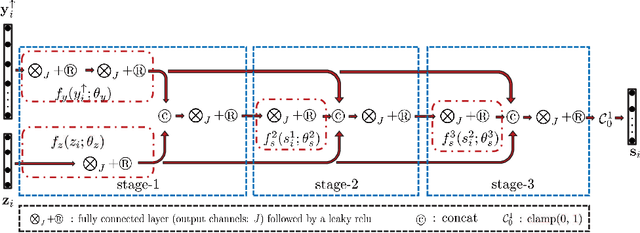
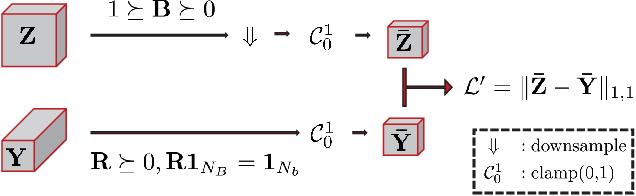
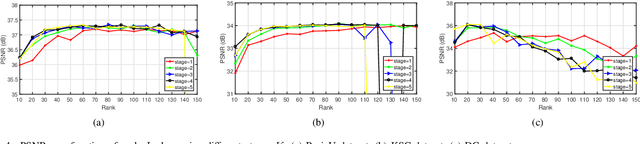
This paper focuses on hyperspectral image (HSI) super-resolution that aims to fuse a low-spatial-resolution HSI and a high-spatial-resolution multispectral image to form a high-spatial-resolution HSI (HR-HSI). Existing deep learning-based approaches are mostly supervised that rely on a large number of labeled training samples, which is unrealistic. The commonly used model-based approaches are unsupervised and flexible but rely on hand-craft priors. Inspired by the specific properties of model, we make the first attempt to design a model inspired deep network for HSI super-resolution in an unsupervised manner. This approach consists of an implicit autoencoder network built on the target HR-HSI that treats each pixel as an individual sample. The nonnegative matrix factorization (NMF) of the target HR-HSI is integrated into the autoencoder network, where the two NMF parts, spectral and spatial matrices, are treated as decoder parameters and hidden outputs respectively. In the encoding stage, we present a pixel-wise fusion model to estimate hidden outputs directly, and then reformulate and unfold the model's algorithm to form the encoder network. With the specific architecture, the proposed network is similar to a manifold prior-based model, and can be trained patch by patch rather than the entire image. Moreover, we propose an additional unsupervised network to estimate the point spread function and spectral response function. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach.