 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTS-UNMixers: Multivariate Time Series Forecasting via Channel-Time Dual Unmixing
Nov 26, 2024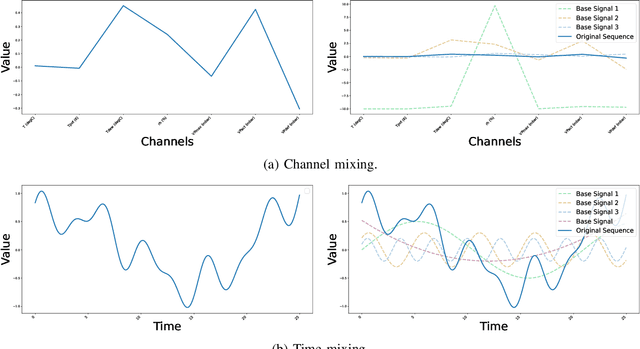
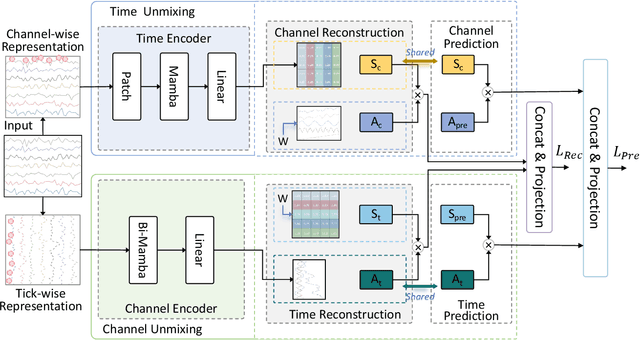
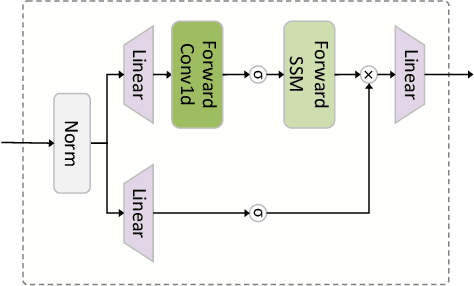
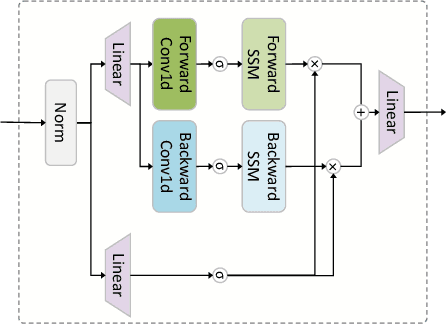
Multivariate time series data provide a robust framework for future predictions by leveraging information across multiple dimensions, ensuring broad applicability in practical scenarios. However, their high dimensionality and mixing patterns pose significant challenges in establishing an interpretable and explicit mapping between historical and future series, as well as extracting long-range feature dependencies. To address these challenges, we propose a channel-time dual unmixing network for multivariate time series forecasting (named MTS-UNMixer), which decomposes the entire series into critical bases and coefficients across both the time and channel dimensions. This approach establishes a robust sharing mechanism between historical and future series, enabling accurate representation and enhancing physical interpretability. Specifically, MTS-UNMixers represent sequences over time as a mixture of multiple trends and cycles, with the time-correlated representation coefficients shared across both historical and future time periods. In contrast, sequence over channels can be decomposed into multiple tick-wise bases, which characterize the channel correlations and are shared across the whole series. To estimate the shared time-dependent coefficients, a vanilla Mamba network is employed, leveraging its alignment with directional causality. Conversely, a bidirectional Mamba network is utilized to model the shared channel-correlated bases, accommodating noncausal relationships. Experimental results show that MTS-UNMixers significantly outperform existing methods on multiple benchmark datasets. The code is available at https://github.com/ZHU-0108/MTS-UNMixers.
HTD-Mamba: Efficient Hyperspectral Target Detection with Pyramid State Space Model
Jul 09, 2024



Hyperspectral target detection (HTD) identifies objects of interest from complex backgrounds at the pixel level, playing a vital role in Earth observation. However, HTD faces challenges due to limited prior knowledge and spectral variations, leading to underfitting models and unreliable performance. To address these challenges, this paper proposes an efficient self-supervised HTD method with a pyramid state space model (SSM), named HTD-Mamba, which employs spectrally contrastive learning to distinguish between target and background based on the similarity measurement of intrinsic features. Specifically, to obtain sufficient training samples and leverage spatial contextual information, we propose a spatial-encoded spectral augmentation technique that encodes all surrounding pixels within a patch into a transformed view of the central pixel. Additionally, to explore global band correlations, we divide pixels into continuous group-wise spectral embeddings and introduce Mamba to HTD for the first time to model long-range dependencies of the spectral sequence with linear complexity. Furthermore, to alleviate spectral variation and enhance robust representation, we propose a pyramid SSM as a backbone to capture and fuse multiresolution spectral-wise intrinsic features. Extensive experiments conducted on four public datasets demonstrate that the proposed method outperforms state-of-the-art methods in both quantitative and qualitative evaluations. Code is available at \url{https://github.com/shendb2022/HTD-Mamba}.
Hyperspectral Target Detection Based on Low-Rank Background Subspace Learning and Graph Laplacian Regularization
Jun 01, 2023



Hyperspectral target detection is good at finding dim and small objects based on spectral characteristics. However, existing representation-based methods are hindered by the problem of the unknown background dictionary and insufficient utilization of spatial information. To address these issues, this paper proposes an efficient optimizing approach based on low-rank representation (LRR) and graph Laplacian regularization (GLR). Firstly, to obtain a complete and pure background dictionary, we propose a LRR-based background subspace learning method by jointly mining the low-dimensional structure of all pixels. Secondly, to fully exploit local spatial relationships and capture the underlying geometric structure, a local region-based GLR is employed to estimate the coefficients. Finally, the desired detection map is generated by computing the ratio of representation errors from binary hypothesis testing. The experiments conducted on two benchmark datasets validate the effectiveness and superiority of the approach. For reproduction, the accompanying code is available at https://github.com/shendb2022/LRBSL-GLR.