 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Autonomous Assembly in Fusion Application with Learning-by-doing: a Peg-in-hole Study
Aug 24, 2022



Robotic peg-in-hole assembly is an essential task in robotic automation research. Reinforcement learning (RL) combined with deep neural networks (DNNs) lead to extraordinary achievements in this area. However, current RL-based approaches could hardly perform well under the unique environmental and mission requirements of fusion applications. Therefore, we have proposed a new designed RL-based method. Furthermore, unlike other approaches, we focus on innovations in the structure of DNNs instead of the RL model. Data from the RGB camera and force/torque (F/T) sensor as the input are fed into a multi-input branch network, and the best action in the current state is output by the network. All training and experiments are carried out in a realistic environment, and from the experiment result, this multi-sensor fusion approach has been shown to work well in rigid peg-in-hole assembly tasks with 0.1mm precision in uncertain and unstable environments.
Pyramidal Dense Attention Networks for Lightweight Image Super-Resolution
Jun 13, 2021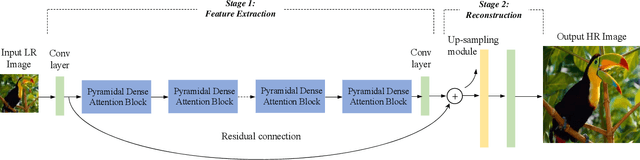
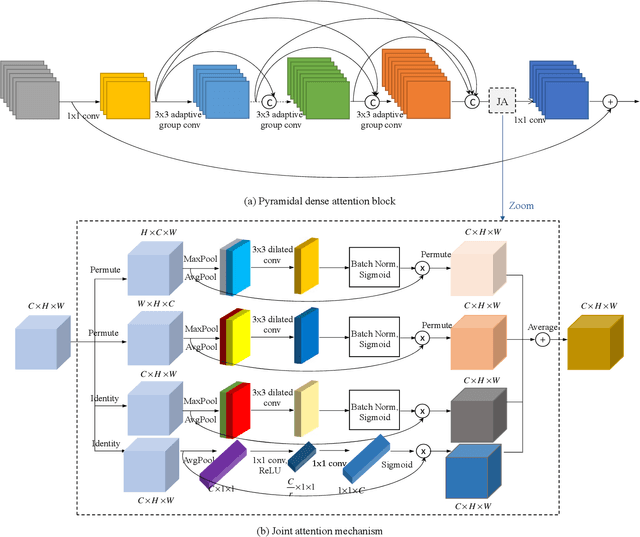

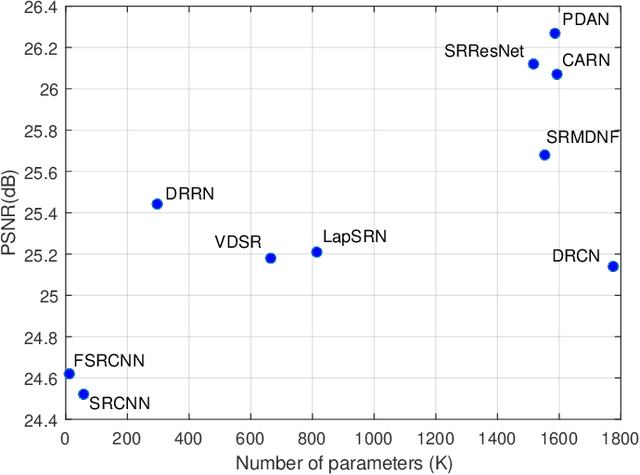
Recently, deep convolutional neural network methods have achieved an excellent performance in image superresolution (SR), but they can not be easily applied to embedded devices due to large memory cost. To solve this problem, we propose a pyramidal dense attention network (PDAN) for lightweight image super-resolution in this paper. In our method, the proposed pyramidal dense learning can gradually increase the width of the densely connected layer inside a pyramidal dense block to extract deep features efficiently. Meanwhile, the adaptive group convolution that the number of groups grows linearly with dense convolutional layers is introduced to relieve the parameter explosion. Besides, we also present a novel joint attention to capture cross-dimension interaction between the spatial dimensions and channel dimension in an efficient way for providing rich discriminative feature representations. Extensive experimental results show that our method achieves superior performance in comparison with the state-of-the-art lightweight SR methods.
Feedback Pyramid Attention Networks for Single Image Super-Resolution
Jun 13, 2021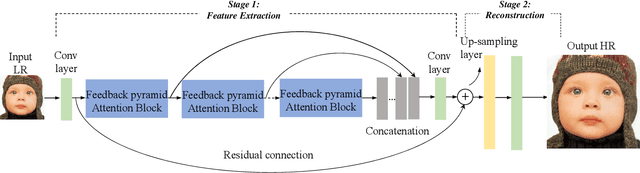
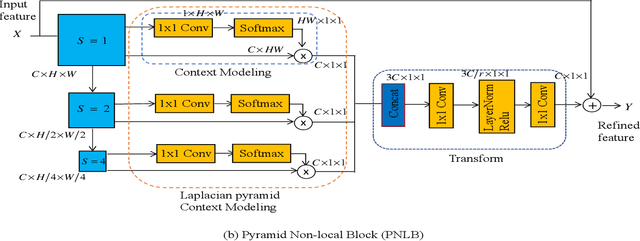
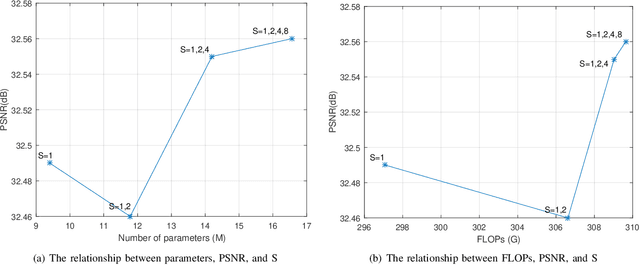

Recently, convolutional neural network (CNN) based image super-resolution (SR) methods have achieved significant performance improvement. However, most CNN-based methods mainly focus on feed-forward architecture design and neglect to explore the feedback mechanism, which usually exists in the human visual system. In this paper, we propose feedback pyramid attention networks (FPAN) to fully exploit the mutual dependencies of features. Specifically, a novel feedback connection structure is developed to enhance low-level feature expression with high-level information. In our method, the output of each layer in the first stage is also used as the input of the corresponding layer in the next state to re-update the previous low-level filters. Moreover, we introduce a pyramid non-local structure to model global contextual information in different scales and improve the discriminative representation of the network. Extensive experimental results on various datasets demonstrate the superiority of our FPAN in comparison with the state-of-the-art SR methods.
FusionLane: Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks
Mar 09, 2020
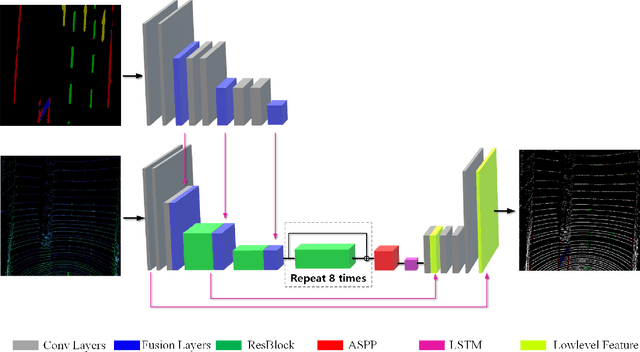

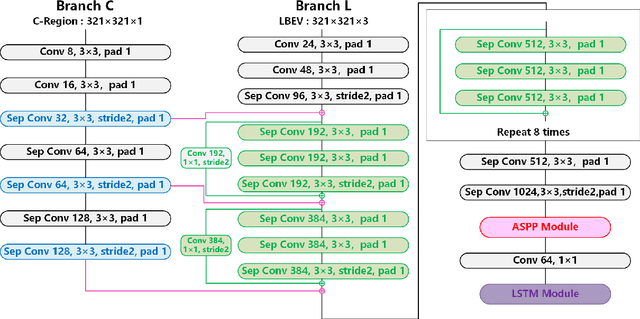
It is a crucial step to achieve effective semantic segmentation of lane marking during the construction of the lane level high-precision map. In recent years, many image semantic segmentation methods have been proposed. These methods mainly focus on the image from camera, due to the limitation of the sensor itself, the accurate three-dimensional spatial position of the lane marking cannot be obtained, so the demand for the lane level high-precision map construction cannot be met. This paper proposes a lane marking semantic segmentation method based on LIDAR and camera fusion deep neural network. Different from other methods, in order to obtain accurate position information of the segmentation results, the semantic segmentation object of this paper is a bird's eye view converted from a LIDAR points cloud instead of an image captured by a camera. This method first uses the deeplabv3+ [\ref{ref:1}] network to segment the image captured by the camera, and the segmentation result is merged with the point clouds collected by the LIDAR as the input of the proposed network. In this neural network, we also add a long short-term memory (LSTM) structure to assist the network for semantic segmentation of lane markings by using the the time series information. The experiments on more than 14,000 image datasets which we have manually labeled and expanded have shown the proposed method has better performance on the semantic segmentation of the points cloud bird's eye view. Therefore, the automation of high-precision map construction can be significantly improved. Our code is available at https://github.com/rolandying/FusionLane.
Multi-grained Attention Networks for Single Image Super-Resolution
Sep 29, 2019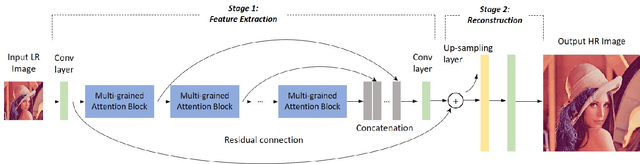



Deep Convolutional Neural Networks (CNN) have drawn great attention in image super-resolution (SR). Recently, visual attention mechanism, which exploits both of the feature importance and contextual cues, has been introduced to image SR and proves to be effective to improve CNN-based SR performance. In this paper, we make a thorough investigation on the attention mechanisms in a SR model and shed light on how simple and effective improvements on these ideas improve the state-of-the-arts. We further propose a unified approach called "multi-grained attention networks (MGAN)" which fully exploits the advantages of multi-scale and attention mechanisms in SR tasks. In our method, the importance of each neuron is computed according to its surrounding regions in a multi-grained fashion and then is used to adaptively re-scale the feature responses. More importantly, the "channel attention" and "spatial attention" strategies in previous methods can be essentially considered as two special cases of our method. We also introduce multi-scale dense connections to extract the image features at multiple scales and capture the features of different layers through dense skip connections. Ablation studies on benchmark datasets demonstrate the effectiveness of our method. In comparison with other state-of-the-art SR methods, our method shows the superiority in terms of both accuracy and model size.