 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionLane: Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks
Paper and Code

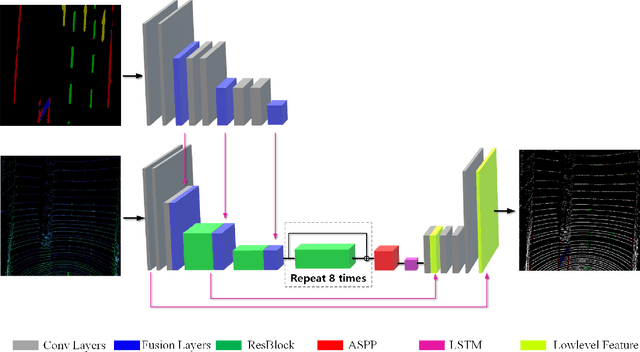

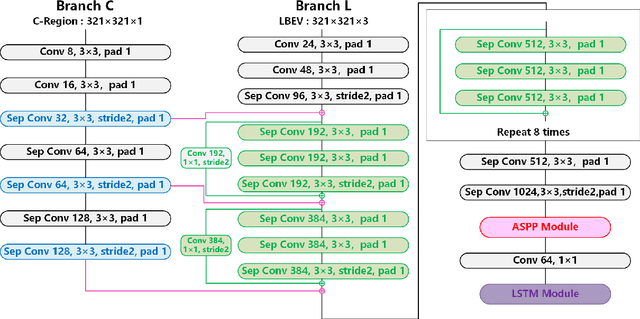
It is a crucial step to achieve effective semantic segmentation of lane marking during the construction of the lane level high-precision map. In recent years, many image semantic segmentation methods have been proposed. These methods mainly focus on the image from camera, due to the limitation of the sensor itself, the accurate three-dimensional spatial position of the lane marking cannot be obtained, so the demand for the lane level high-precision map construction cannot be met. This paper proposes a lane marking semantic segmentation method based on LIDAR and camera fusion deep neural network. Different from other methods, in order to obtain accurate position information of the segmentation results, the semantic segmentation object of this paper is a bird's eye view converted from a LIDAR points cloud instead of an image captured by a camera. This method first uses the deeplabv3+ [\ref{ref:1}] network to segment the image captured by the camera, and the segmentation result is merged with the point clouds collected by the LIDAR as the input of the proposed network. In this neural network, we also add a long short-term memory (LSTM) structure to assist the network for semantic segmentation of lane markings by using the the time series information. The experiments on more than 14,000 image datasets which we have manually labeled and expanded have shown the proposed method has better performance on the semantic segmentation of the points cloud bird's eye view. Therefore, the automation of high-precision map construction can be significantly improved. Our code is available at https://github.com/rolandying/FusionLane.