 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaser Data Based Automatic Generation of Lane-Level Road Map for Intelligent Vehicles
Dec 11, 2020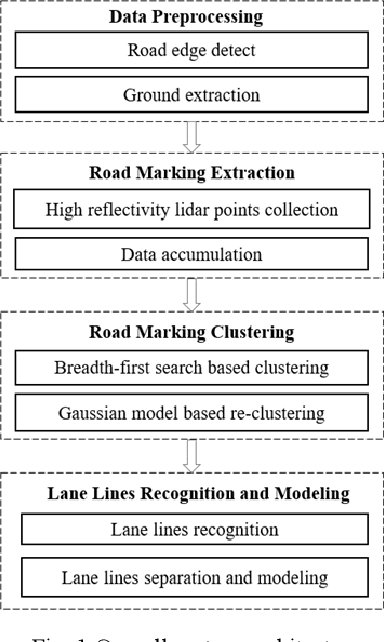

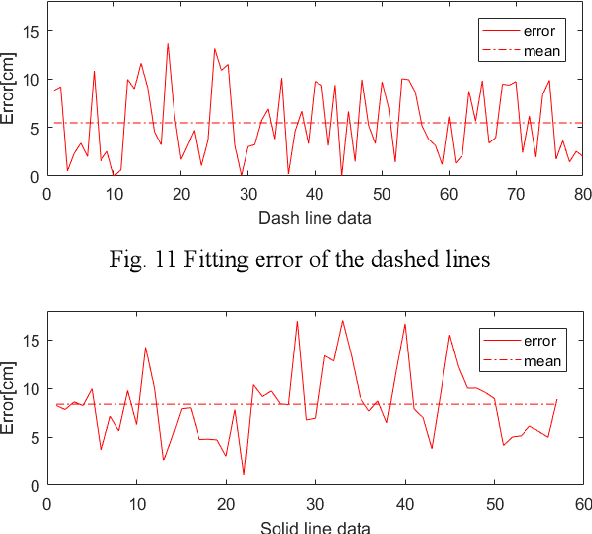

With the development of intelligent vehicle systems, a high-precision road map is increasingly needed in many aspects. The automatic lane lines extraction and modeling are the most essential steps for the generation of a precise lane-level road map. In this paper, an automatic lane-level road map generation system is proposed. To extract the road markings on the ground, the multi-region Otsu thresholding method is applied, which calculates the intensity value of laser data that maximizes the variance between background and road markings. The extracted road marking points are then projected to the raster image and clustered using a two-stage clustering algorithm. Lane lines are subsequently recognized from these clusters by the shape features of their minimum bounding rectangle. To ensure the storage efficiency of the map, the lane lines are approximated to cubic polynomial curves using a Bayesian estimation approach. The proposed lane-level road map generation system has been tested on urban and expressway conditions in Hefei, China. The experimental results on the datasets show that our method can achieve excellent extraction and clustering effect, and the fitted lines can reach a high position accuracy with an error of less than 10 cm
A Fast Point Cloud Ground Segmentation Approach Based on Coarse-To-Fine Markov Random Field
Nov 26, 2020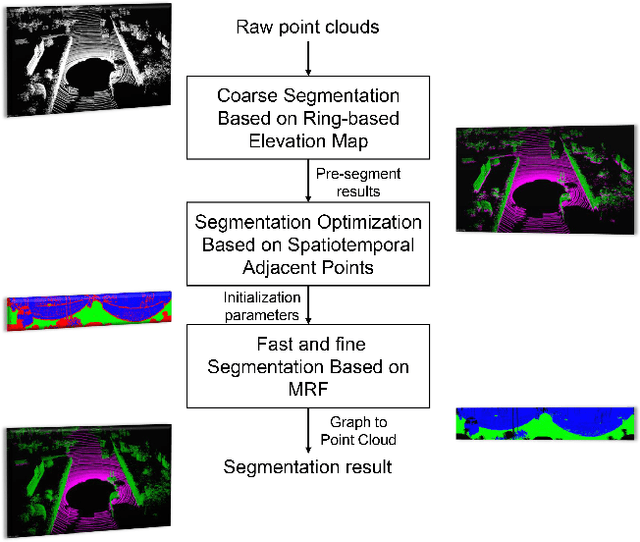
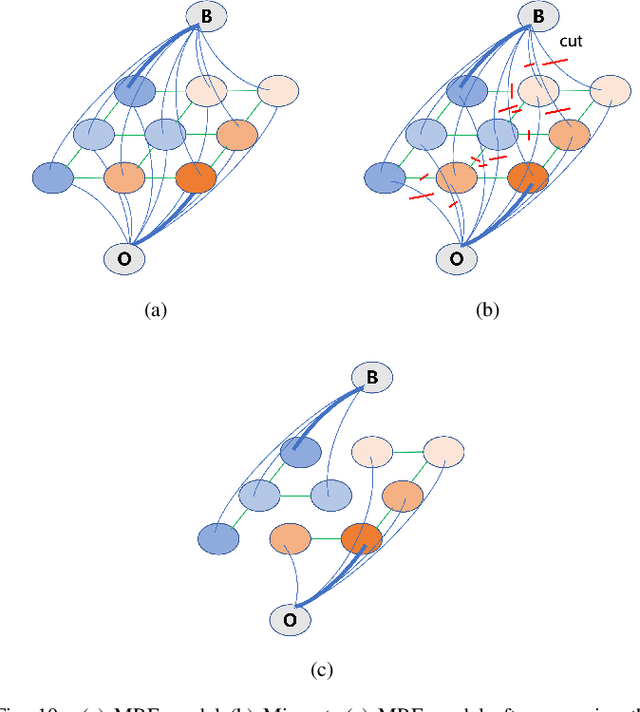
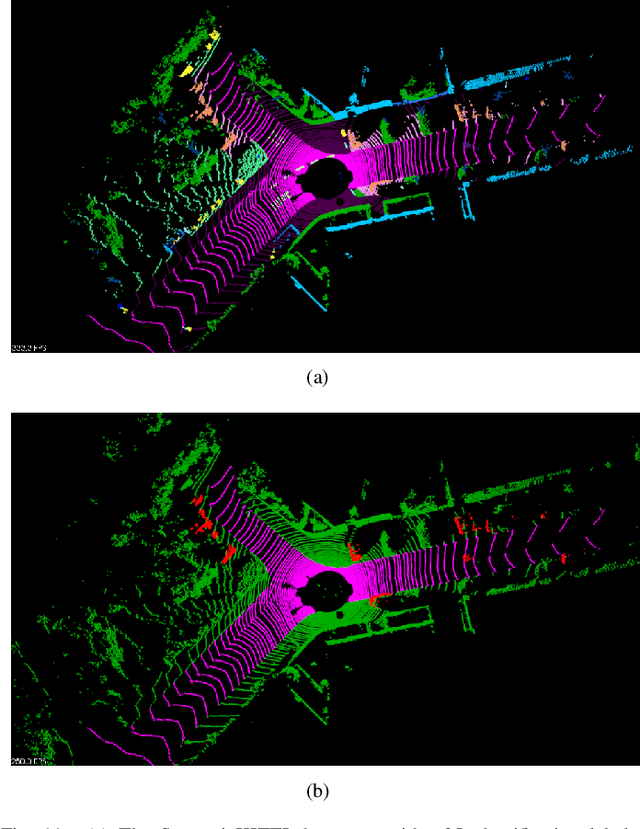
Ground segmentation is an important preprocessing task for autonomous vehicles (AVs) with 3D LiDARs. To solve the problem of existing ground segmentation methods being very difficult to balance accuracy and computational complexity, a fast point cloud ground segmentation approach based on a coarse-to-fine Markov random field (MRF) method is proposed. The method uses an improved elevation map for ground coarse segmentation, and then uses spatiotemporal adjacent points to optimize the segmentation results. The processed point cloud is classified into high-confidence obstacle points, ground points, and unknown classification points to initialize an MRF model. The graph cut method is then used to solve the model to achieve fine segmentation. Experiments on datasets showed that our method improves on other algorithms in terms of ground segmentation accuracy and is faster than other graph-based algorithms, which require only a single core of an I7-3770 CPU to process a frame of Velodyne HDL-64E data (in 39.77 ms, on average). Field tests were also conducted to demonstrate the effectiveness of the proposed method.
FusionLane: Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks
Mar 09, 2020
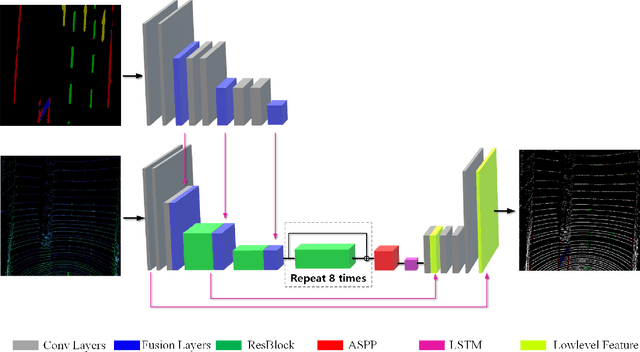

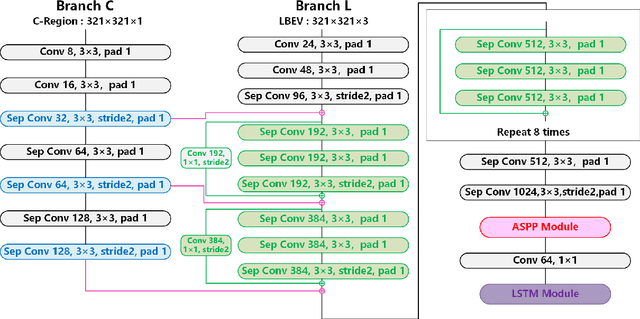
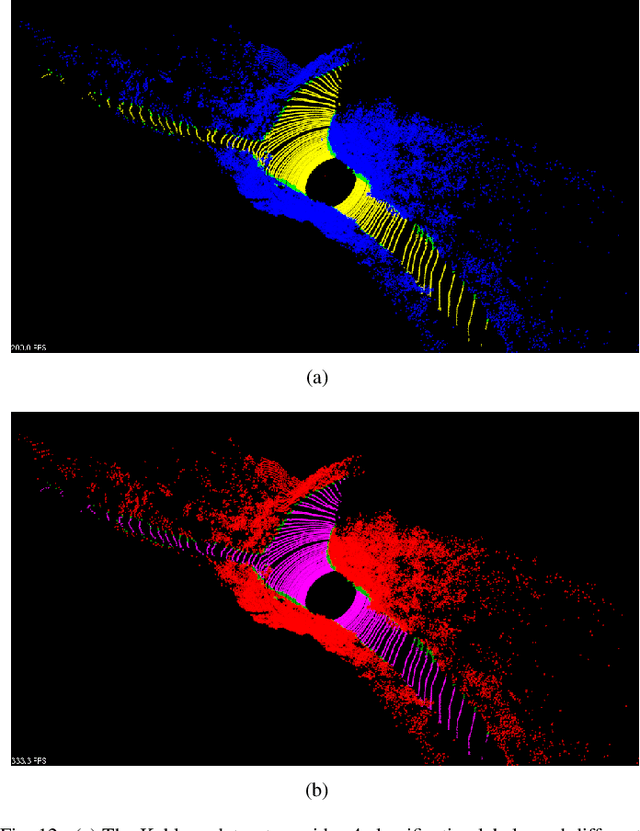
It is a crucial step to achieve effective semantic segmentation of lane marking during the construction of the lane level high-precision map. In recent years, many image semantic segmentation methods have been proposed. These methods mainly focus on the image from camera, due to the limitation of the sensor itself, the accurate three-dimensional spatial position of the lane marking cannot be obtained, so the demand for the lane level high-precision map construction cannot be met. This paper proposes a lane marking semantic segmentation method based on LIDAR and camera fusion deep neural network. Different from other methods, in order to obtain accurate position information of the segmentation results, the semantic segmentation object of this paper is a bird's eye view converted from a LIDAR points cloud instead of an image captured by a camera. This method first uses the deeplabv3+ [\ref{ref:1}] network to segment the image captured by the camera, and the segmentation result is merged with the point clouds collected by the LIDAR as the input of the proposed network. In this neural network, we also add a long short-term memory (LSTM) structure to assist the network for semantic segmentation of lane markings by using the the time series information. The experiments on more than 14,000 image datasets which we have manually labeled and expanded have shown the proposed method has better performance on the semantic segmentation of the points cloud bird's eye view. Therefore, the automation of high-precision map construction can be significantly improved. Our code is available at https://github.com/rolandying/FusionLane.