 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Autonomous Assembly in Fusion Application with Learning-by-doing: a Peg-in-hole Study
Aug 24, 2022



Robotic peg-in-hole assembly is an essential task in robotic automation research. Reinforcement learning (RL) combined with deep neural networks (DNNs) lead to extraordinary achievements in this area. However, current RL-based approaches could hardly perform well under the unique environmental and mission requirements of fusion applications. Therefore, we have proposed a new designed RL-based method. Furthermore, unlike other approaches, we focus on innovations in the structure of DNNs instead of the RL model. Data from the RGB camera and force/torque (F/T) sensor as the input are fed into a multi-input branch network, and the best action in the current state is output by the network. All training and experiments are carried out in a realistic environment, and from the experiment result, this multi-sensor fusion approach has been shown to work well in rigid peg-in-hole assembly tasks with 0.1mm precision in uncertain and unstable environments.
FusionLane: Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks
Mar 09, 2020
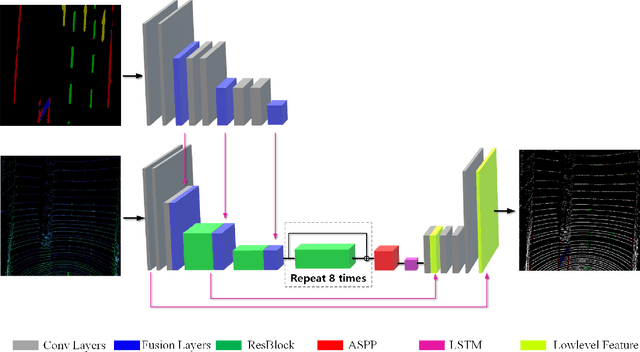

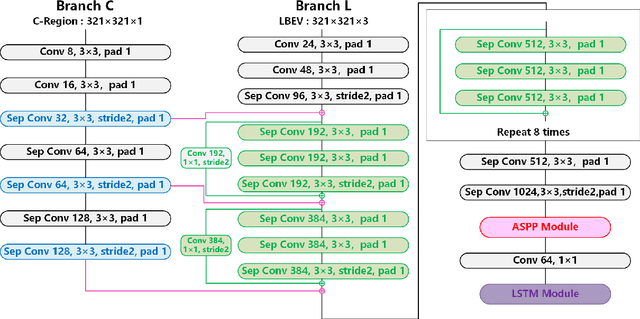
It is a crucial step to achieve effective semantic segmentation of lane marking during the construction of the lane level high-precision map. In recent years, many image semantic segmentation methods have been proposed. These methods mainly focus on the image from camera, due to the limitation of the sensor itself, the accurate three-dimensional spatial position of the lane marking cannot be obtained, so the demand for the lane level high-precision map construction cannot be met. This paper proposes a lane marking semantic segmentation method based on LIDAR and camera fusion deep neural network. Different from other methods, in order to obtain accurate position information of the segmentation results, the semantic segmentation object of this paper is a bird's eye view converted from a LIDAR points cloud instead of an image captured by a camera. This method first uses the deeplabv3+ [\ref{ref:1}] network to segment the image captured by the camera, and the segmentation result is merged with the point clouds collected by the LIDAR as the input of the proposed network. In this neural network, we also add a long short-term memory (LSTM) structure to assist the network for semantic segmentation of lane markings by using the the time series information. The experiments on more than 14,000 image datasets which we have manually labeled and expanded have shown the proposed method has better performance on the semantic segmentation of the points cloud bird's eye view. Therefore, the automation of high-precision map construction can be significantly improved. Our code is available at https://github.com/rolandying/FusionLane.