 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoL2S: Auto Long-Short Reasoning for Efficient Large Language Models
May 28, 2025The reasoning-capable large language models (LLMs) demonstrate strong performance on complex reasoning tasks but often suffer from overthinking, generating unnecessarily long chain-of-thought (CoT) reasoning paths for easy reasoning questions, thereby increasing inference cost and latency. Recent approaches attempt to address this challenge by manually deciding when to apply long or short reasoning. However, they lack the flexibility to adapt CoT length dynamically based on question complexity. In this paper, we propose Auto Long-Short Reasoning (AutoL2S), a dynamic and model-agnostic framework that enables LLMs to dynamically compress their generated reasoning path based on the complexity of the reasoning question. AutoL2S enables a learned paradigm, in which LLMs themselves can decide when longer reasoning is necessary and when shorter reasoning suffices, by training on data annotated with our proposed method, which includes both long and short CoT paths and a special <EASY> token. We then use <EASY> token to indicate when the model can skip generating lengthy CoT reasoning. This proposed annotation strategy can enhance the LLMs' ability to generate shorter CoT reasoning paths with improved quality after training. Extensive evaluation results show that AutoL2S reduces the length of reasoning generation by up to 57% without compromising performance, demonstrating the effectiveness of AutoL2S for scalable and efficient LLM reasoning.
100-LongBench: Are de facto Long-Context Benchmarks Literally Evaluating Long-Context Ability?
May 25, 2025



Long-context capability is considered one of the most important abilities of LLMs, as a truly long context-capable LLM enables users to effortlessly process many originally exhausting tasks -- e.g., digesting a long-form document to find answers vs. directly asking an LLM about it. However, existing real-task-based long-context evaluation benchmarks have two major shortcomings. First, benchmarks like LongBench often do not provide proper metrics to separate long-context performance from the model's baseline ability, making cross-model comparison unclear. Second, such benchmarks are usually constructed with fixed input lengths, which limits their applicability across different models and fails to reveal when a model begins to break down. To address these issues, we introduce a length-controllable long-context benchmark and a novel metric that disentangles baseline knowledge from true long-context capabilities. Experiments demonstrate the superiority of our approach in effectively evaluating LLMs.
70% Size, 100% Accuracy: Lossless LLM Compression for Efficient GPU Inference via Dynamic-Length Float
Apr 15, 2025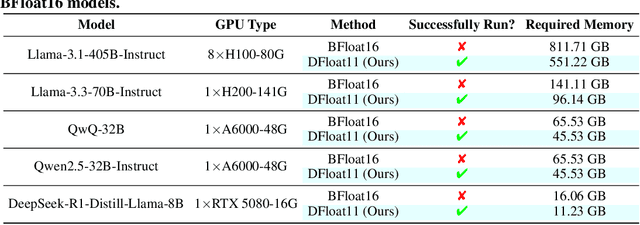
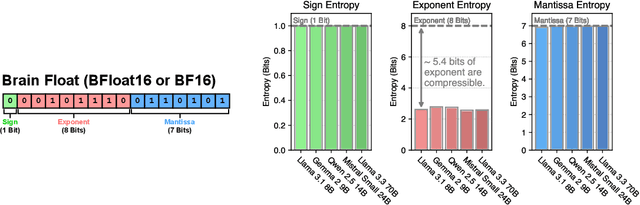
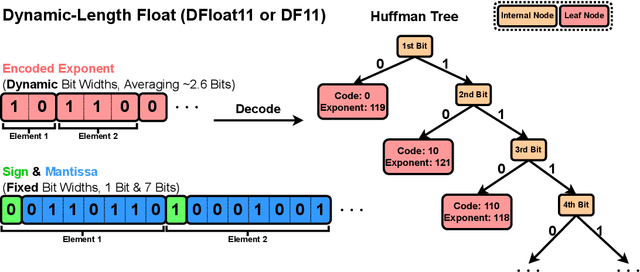
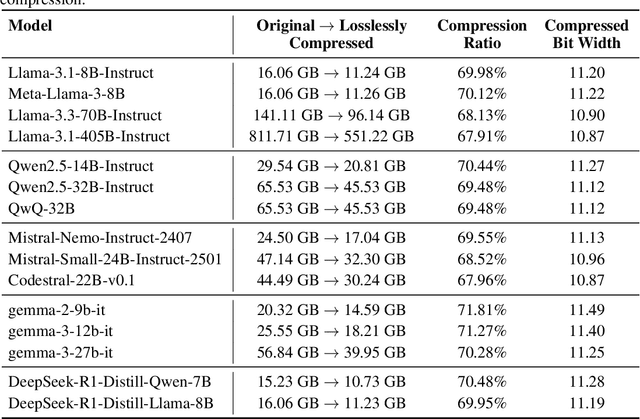
Large Language Models (LLMs) have grown rapidly in size, creating significant challenges for efficient deployment on resource-constrained hardware. In this paper, we introduce Dynamic-Length Float (DFloat11), a lossless compression framework that reduces LLM size by 30% while preserving outputs that are bit-for-bit identical to the original model. DFloat11 is motivated by the low entropy in the BFloat16 weight representation of LLMs, which reveals significant inefficiency in existing storage format. By applying entropy coding, DFloat11 assigns dynamic-length encodings to weights based on frequency, achieving near information-optimal compression without any loss of precision. To facilitate efficient inference with dynamic-length encodings, we develop a custom GPU kernel for fast online decompression. Our design incorporates the following: (i) decomposition of memory-intensive lookup tables (LUTs) into compact LUTs that fit in GPU SRAM, (ii) a two-phase kernel for coordinating thread read/write positions using lightweight auxiliary variables, and (iii) transformer-block-level decompression to minimize latency. Experiments on recent models, including Llama-3.1, Qwen-2.5, and Gemma-3, validates our hypothesis that DFloat11 achieves around 30% model size reduction while preserving bit-for-bit exact outputs. Compared to a potential alternative of offloading parts of an uncompressed model to the CPU to meet memory constraints, DFloat11 achieves 1.9-38.8x higher throughput in token generation. With a fixed GPU memory budget, DFloat11 enables 5.3-13.17x longer context lengths than uncompressed models. Notably, our method enables lossless inference of Llama-3.1-405B, an 810GB model, on a single node equipped with 8x80GB GPUs. Our code and models are available at https://github.com/LeanModels/DFloat11.
More for Keys, Less for Values: Adaptive KV Cache Quantization
Feb 20, 2025This paper introduces an information-aware quantization framework that adaptively compresses the key-value (KV) cache in large language models (LLMs). Although prior work has underscored the distinct roles of key and value cache during inference, our systematic analysis -- examining singular value distributions, spectral norms, and Frobenius norms -- reveals, for the first time, that key matrices consistently exhibit higher norm values and are more sensitive to quantization than value matrices. Furthermore, our theoretical analysis shows that matrices with higher spectral norms amplify quantization errors more significantly. Motivated by these insights, we propose a mixed-precision quantization strategy, KV-AdaQuant, which allocates more bit-width for keys and fewer for values since key matrices have higher norm values. With the same total KV bit budget, this approach effectively mitigates error propagation across transformer layers while achieving significant memory savings. Our extensive experiments on multiple LLMs (1B--70B) demonstrate that our mixed-precision quantization scheme maintains high model accuracy even under aggressive compression. For instance, using 4-bit for Key and 2-bit for Value achieves an accuracy of 75.2%, whereas reversing the assignment (2-bit for Key and 4-bit for Value) yields only 54.7% accuracy. The code is available at https://tinyurl.com/kv-adaquant
Taylor Unswift: Secured Weight Release for Large Language Models via Taylor Expansion
Oct 06, 2024
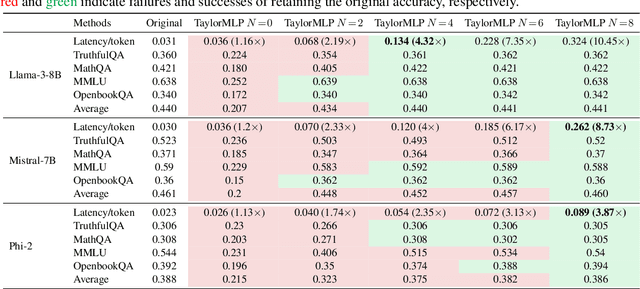
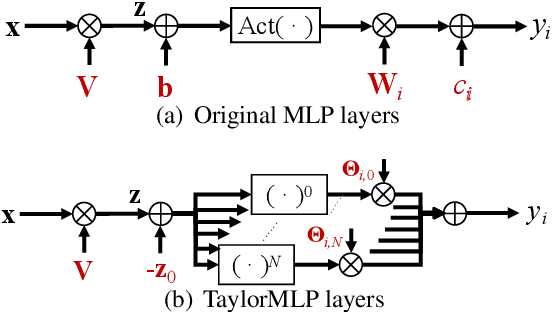

Ensuring the security of released large language models (LLMs) poses a significant dilemma, as existing mechanisms either compromise ownership rights or raise data privacy concerns. To address this dilemma, we introduce TaylorMLP to protect the ownership of released LLMs and prevent their abuse. Specifically, TaylorMLP preserves the ownership of LLMs by transforming the weights of LLMs into parameters of Taylor-series. Instead of releasing the original weights, developers can release the Taylor-series parameters with users, thereby ensuring the security of LLMs. Moreover, TaylorMLP can prevent abuse of LLMs by adjusting the generation speed. It can induce low-speed token generation for the protected LLMs by increasing the terms in the Taylor-series. This intentional delay helps LLM developers prevent potential large-scale unauthorized uses of their models. Empirical experiments across five datasets and three LLM architectures demonstrate that TaylorMLP induces over 4x increase in latency, producing the tokens precisely matched with original LLMs. Subsequent defensive experiments further confirm that TaylorMLP effectively prevents users from reconstructing the weight values based on downstream datasets.
Retrieval-Enhanced Knowledge Editing for Multi-Hop Question Answering in Language Models
Mar 28, 2024



Large Language Models (LLMs) have shown proficiency in question-answering tasks but often struggle to integrate real-time knowledge updates, leading to potentially outdated or inaccurate responses. This problem becomes even more challenging when dealing with multi-hop questions since they require LLMs to update and integrate multiple knowledge pieces relevant to the questions. To tackle the problem, we propose the Retrieval-Augmented model Editing (RAE) framework tailored for multi-hop question answering. RAE first retrieves edited facts and then refines the language model through in-context learning. Specifically, our retrieval approach, based on mutual information maximization, leverages the reasoning abilities of LLMs to identify chain facts that na\"ive similarity-based searches might miss. Additionally, our framework incorporates a pruning strategy to eliminate redundant information from the retrieved facts, which enhances the editing accuracy and mitigates the hallucination problem. Our framework is supported by theoretical justification for its fact retrieval efficacy. Finally, comprehensive evaluation across various LLMs validates RAE's ability in providing accurate answers with updated knowledge.
LoRA-as-an-Attack! Piercing LLM Safety Under The Share-and-Play Scenario
Feb 29, 2024



Fine-tuning LLMs is crucial to enhancing their task-specific performance and ensuring model behaviors are aligned with human preferences. Among various fine-tuning methods, LoRA is popular for its efficiency and ease to use, allowing end-users to easily post and adopt lightweight LoRA modules on open-source platforms to tailor their model for different customization. However, such a handy share-and-play setting opens up new attack surfaces, that the attacker can render LoRA as an attacker, such as backdoor injection, and widely distribute the adversarial LoRA to the community easily. This can result in detrimental outcomes. Despite the huge potential risks of sharing LoRA modules, this aspect however has not been fully explored. To fill the gap, in this study we thoroughly investigate the attack opportunities enabled in the growing share-and-play scenario. Specifically, we study how to inject backdoor into the LoRA module and dive deeper into LoRA's infection mechanisms. We found that training-free mechanism is possible in LoRA backdoor injection. We also discover the impact of backdoor attacks with the presence of multiple LoRA adaptions concurrently as well as LoRA based backdoor transferability. Our aim is to raise awareness of the potential risks under the emerging share-and-play scenario, so as to proactively prevent potential consequences caused by LoRA-as-an-Attack. Warning: the paper contains potential offensive content generated by models.
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Feb 05, 2024



Efficiently serving large language models (LLMs) requires batching many requests together to reduce the cost per request. Yet, the key-value (KV) cache, which stores attention keys and values to avoid re-computations, significantly increases memory demands and becomes the new bottleneck in speed and memory usage. This memory demand increases with larger batch sizes and longer context lengths. Additionally, the inference speed is limited by the size of KV cache, as the GPU's SRAM must load the entire KV cache from the main GPU memory for each token generated, causing the computational core to be idle during this process. A straightforward and effective solution to reduce KV cache size is quantization, which decreases the total bytes taken by KV cache. However, there is a lack of in-depth studies that explore the element distribution of KV cache to understand the hardness and limitation of KV cache quantization. To fill the gap, we conducted a comprehensive study on the element distribution in KV cache of popular LLMs. Our findings indicate that the key cache should be quantized per-channel, i.e., group elements along the channel dimension and quantize them together. In contrast, the value cache should be quantized per-token. From this analysis, we developed a tuning-free 2bit KV cache quantization algorithm, named KIVI. With the hardware-friendly implementation, KIVI can enable Llama (Llama-2), Falcon, and Mistral models to maintain almost the same quality while using $\mathbf{2.6\times}$ less peak memory usage (including the model weight). This reduction in memory usage enables up to $\mathbf{4\times}$ larger batch size, bringing $\mathbf{2.35\times \sim 3.47\times}$ throughput on real LLM inference workload. The source code is available at https://github.com/jy-yuan/KIVI.
LETA: Learning Transferable Attribution for Generic Vision Explainer
Dec 23, 2023Explainable machine learning significantly improves the transparency of deep neural networks~(DNN). However, existing work is constrained to explaining the behavior of individual model predictions, and lacks the ability to transfer the explanation across various models and tasks. This limitation results in explaining various tasks being time- and resource-consuming. To address this problem, we develop a pre-trained, DNN-based, generic explainer on large-scale image datasets, and leverage its transferability to explain various vision models for downstream tasks. In particular, the pre-training of generic explainer focuses on LEarning Transferable Attribution (LETA). The transferable attribution takes advantage of the versatile output of the target backbone encoders to comprehensively encode the essential attribution for explaining various downstream tasks. LETA guides the pre-training of the generic explainer towards the transferable attribution, and introduces a rule-based adaptation of the transferable attribution for explaining downstream tasks, without the need for additional training on downstream data. Theoretical analysis demonstrates that the pre-training of LETA enables minimizing the explanation error bound aligned with the conditional $\mathcal{V}$-information on downstream tasks. Empirical studies involve explaining three different architectures of vision models across three diverse downstream datasets. The experiment results indicate LETA is effective in explaining these tasks without the need for additional training on the data of downstream tasks.
Editable Graph Neural Network for Node Classifications
May 24, 2023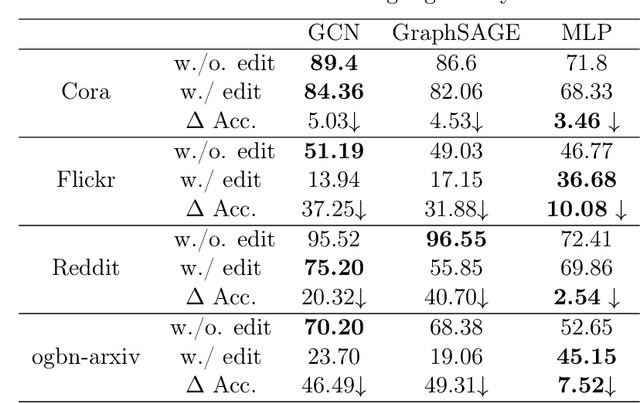

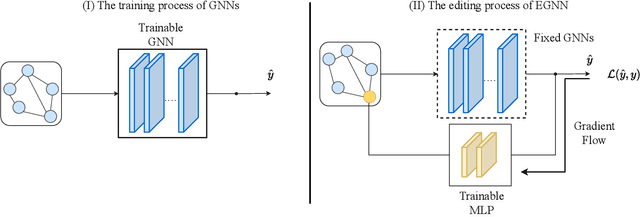

Despite Graph Neural Networks (GNNs) have achieved prominent success in many graph-based learning problem, such as credit risk assessment in financial networks and fake news detection in social networks. However, the trained GNNs still make errors and these errors may cause serious negative impact on society. \textit{Model editing}, which corrects the model behavior on wrongly predicted target samples while leaving model predictions unchanged on unrelated samples, has garnered significant interest in the fields of computer vision and natural language processing. However, model editing for graph neural networks (GNNs) is rarely explored, despite GNNs' widespread applicability. To fill the gap, we first observe that existing model editing methods significantly deteriorate prediction accuracy (up to $50\%$ accuracy drop) in GNNs while a slight accuracy drop in multi-layer perception (MLP). The rationale behind this observation is that the node aggregation in GNNs will spread the editing effect throughout the whole graph. This propagation pushes the node representation far from its original one. Motivated by this observation, we propose \underline{E}ditable \underline{G}raph \underline{N}eural \underline{N}etworks (EGNN), a neighbor propagation-free approach to correct the model prediction on misclassified nodes. Specifically, EGNN simply stitches an MLP to the underlying GNNs, where the weights of GNNs are frozen during model editing. In this way, EGNN disables the propagation during editing while still utilizing the neighbor propagation scheme for node prediction to obtain satisfactory results. Experiments demonstrate that EGNN outperforms existing baselines in terms of effectiveness (correcting wrong predictions with lower accuracy drop), generalizability (correcting wrong predictions for other similar nodes), and efficiency (low training time and memory) on various graph datasets.