 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditable Graph Neural Network for Node Classifications
May 24, 2023Despite Graph Neural Networks (GNNs) have achieved prominent success in many graph-based learning problem, such as credit risk assessment in financial networks and fake news detection in social networks. However, the trained GNNs still make errors and these errors may cause serious negative impact on society. \textit{Model editing}, which corrects the model behavior on wrongly predicted target samples while leaving model predictions unchanged on unrelated samples, has garnered significant interest in the fields of computer vision and natural language processing. However, model editing for graph neural networks (GNNs) is rarely explored, despite GNNs' widespread applicability. To fill the gap, we first observe that existing model editing methods significantly deteriorate prediction accuracy (up to $50\%$ accuracy drop) in GNNs while a slight accuracy drop in multi-layer perception (MLP). The rationale behind this observation is that the node aggregation in GNNs will spread the editing effect throughout the whole graph. This propagation pushes the node representation far from its original one. Motivated by this observation, we propose \underline{E}ditable \underline{G}raph \underline{N}eural \underline{N}etworks (EGNN), a neighbor propagation-free approach to correct the model prediction on misclassified nodes. Specifically, EGNN simply stitches an MLP to the underlying GNNs, where the weights of GNNs are frozen during model editing. In this way, EGNN disables the propagation during editing while still utilizing the neighbor propagation scheme for node prediction to obtain satisfactory results. Experiments demonstrate that EGNN outperforms existing baselines in terms of effectiveness (correcting wrong predictions with lower accuracy drop), generalizability (correcting wrong predictions for other similar nodes), and efficiency (low training time and memory) on various graph datasets.
Bring Your Own View: Graph Neural Networks for Link Prediction with Personalized Subgraph Selection
Dec 23, 2022



Graph neural networks (GNNs) have received remarkable success in link prediction (GNNLP) tasks. Existing efforts first predefine the subgraph for the whole dataset and then apply GNNs to encode edge representations by leveraging the neighborhood structure induced by the fixed subgraph. The prominence of GNNLP methods significantly relies on the adhoc subgraph. Since node connectivity in real-world graphs is complex, one shared subgraph is limited for all edges. Thus, the choices of subgraphs should be personalized to different edges. However, performing personalized subgraph selection is nontrivial since the potential selection space grows exponentially to the scale of edges. Besides, the inference edges are not available during training in link prediction scenarios, so the selection process needs to be inductive. To bridge the gap, we introduce a Personalized Subgraph Selector (PS2) as a plug-and-play framework to automatically, personally, and inductively identify optimal subgraphs for different edges when performing GNNLP. PS2 is instantiated as a bi-level optimization problem that can be efficiently solved differently. Coupling GNNLP models with PS2, we suggest a brand-new angle towards GNNLP training: by first identifying the optimal subgraphs for edges; and then focusing on training the inference model by using the sampled subgraphs. Comprehensive experiments endorse the effectiveness of our proposed method across various GNNLP backbones (GCN, GraphSage, NGCF, LightGCN, and SEAL) and diverse benchmarks (Planetoid, OGB, and Recommendation datasets). Our code is publicly available at \url{https://github.com/qiaoyu-tan/PS2}
MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs
Jan 07, 2022

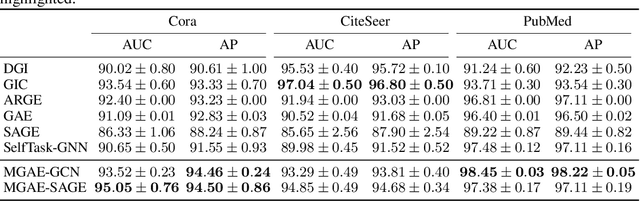
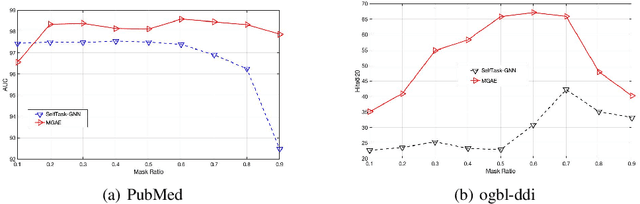
We introduce a novel masked graph autoencoder (MGAE) framework to perform effective learning on graph structure data. Taking insights from self-supervised learning, we randomly mask a large proportion of edges and try to reconstruct these missing edges during training. MGAE has two core designs. First, we find that masking a high ratio of the input graph structure, e.g., $70\%$, yields a nontrivial and meaningful self-supervisory task that benefits downstream applications. Second, we employ a graph neural network (GNN) as an encoder to perform message propagation on the partially-masked graph. To reconstruct the large number of masked edges, a tailored cross-correlation decoder is proposed. It could capture the cross-correlation between the head and tail nodes of anchor edge in multi-granularity. Coupling these two designs enables MGAE to be trained efficiently and effectively. Extensive experiments on multiple open datasets (Planetoid and OGB benchmarks) demonstrate that MGAE generally performs better than state-of-the-art unsupervised learning competitors on link prediction and node classification.
Adaptive Label Smoothing To Regularize Large-Scale Graph Training
Aug 30, 2021



Graph neural networks (GNNs), which learn the node representations by recursively aggregating information from its neighbors, have become a predominant computational tool in many domains. To handle large-scale graphs, most of the existing methods partition the input graph into multiple sub-graphs (e.g., through node clustering) and apply batch training to save memory cost. However, such batch training will lead to label bias within each batch, and then result in over-confidence in model predictions. Since the connected nodes with positively related labels tend to be assigned together, the traditional cross-entropy minimization process will attend on the predictions of biased classes in the batch, and may intensify the overfitting issue. To overcome the label bias problem, we propose the adaptive label smoothing (ALS) method to replace the one-hot hard labels with smoothed ones, which learns to allocate label confidences from the biased classes to the others. Specifically, ALS propagates node labels to aggregate the neighborhood label distribution in a pre-processing step, and then updates the optimal smoothed labels online to adapt to specific graph structure. Experiments on the real-world datasets demonstrate that ALS can be generally applied to the main scalable learning frameworks to calibrate the biased labels and improve generalization performances.
Dirichlet Energy Constrained Learning for Deep Graph Neural Networks
Jul 06, 2021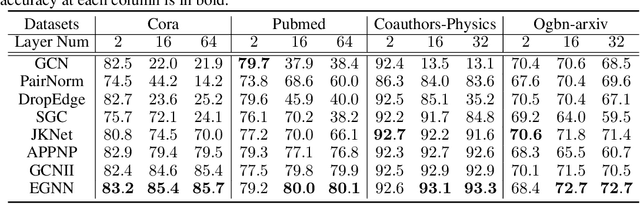
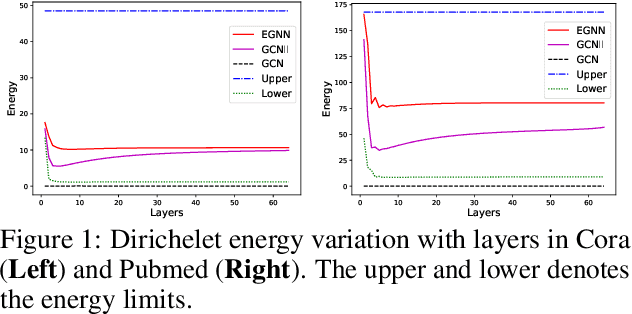

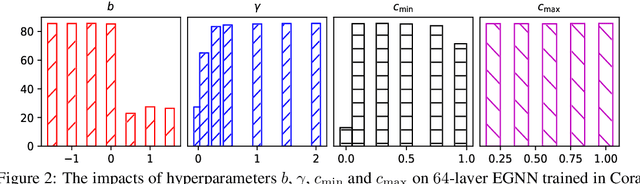
Graph neural networks (GNNs) integrate deep architectures and topological structure modeling in an effective way. However, the performance of existing GNNs would decrease significantly when they stack many layers, because of the over-smoothing issue. Node embeddings tend to converge to similar vectors when GNNs keep recursively aggregating the representations of neighbors. To enable deep GNNs, several methods have been explored recently. But they are developed from either techniques in convolutional neural networks or heuristic strategies. There is no generalizable and theoretical principle to guide the design of deep GNNs. To this end, we analyze the bottleneck of deep GNNs by leveraging the Dirichlet energy of node embeddings, and propose a generalizable principle to guide the training of deep GNNs. Based on it, a novel deep GNN framework -- EGNN is designed. It could provide lower and upper constraints in terms of Dirichlet energy at each layer to avoid over-smoothing. Experimental results demonstrate that EGNN achieves state-of-the-art performance by using deep layers.
Explainable Recommender Systems via Resolving Learning Representations
Aug 21, 2020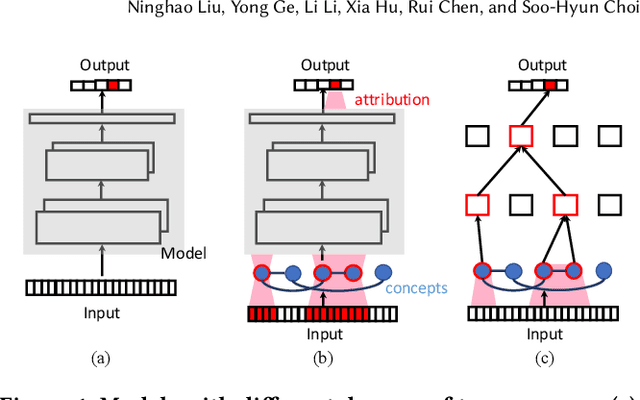


Recommender systems play a fundamental role in web applications in filtering massive information and matching user interests. While many efforts have been devoted to developing more effective models in various scenarios, the exploration on the explainability of recommender systems is running behind. Explanations could help improve user experience and discover system defects. In this paper, after formally introducing the elements that are related to model explainability, we propose a novel explainable recommendation model through improving the transparency of the representation learning process. Specifically, to overcome the representation entangling problem in traditional models, we revise traditional graph convolution to discriminate information from different layers. Also, each representation vector is factorized into several segments, where each segment relates to one semantic aspect in data. Different from previous work, in our model, factor discovery and representation learning are simultaneously conducted, and we are able to handle extra attribute information and knowledge. In this way, the proposed model can learn interpretable and meaningful representations for users and items. Unlike traditional methods that need to make a trade-off between explainability and effectiveness, the performance of our proposed explainable model is not negatively affected after considering explainability. Finally, comprehensive experiments are conducted to validate the performance of our model as well as explanation faithfulness.