 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Probability Estimation with LLMs via Shapley Reconstruction
Jan 14, 2026Large Language Models (LLMs) demonstrate potential to estimate the probability of uncertain events, by leveraging their extensive knowledge and reasoning capabilities. This ability can be applied to support intelligent decision-making across diverse fields, such as financial forecasting and preventive healthcare. However, directly prompting LLMs for probability estimation faces significant challenges: their outputs are often noisy, and the underlying predicting process is opaque. In this paper, we propose PRISM: Probability Reconstruction via Shapley Measures, a framework that brings transparency and precision to LLM-based probability estimation. PRISM decomposes an LLM's prediction by quantifying the marginal contribution of each input factor using Shapley values. These factor-level contributions are then aggregated to reconstruct a calibrated final estimate. In our experiments, we demonstrate PRISM improves predictive accuracy over direct prompting and other baselines, across multiple domains including finance, healthcare, and agriculture. Beyond performance, PRISM provides a transparent prediction pipeline: our case studies visualize how individual factors shape the final estimate, helping build trust in LLM-based decision support systems.
Fairness in Survival Analysis: A Novel Conditional Mutual Information Augmentation Approach
Feb 04, 2025Survival analysis, a vital tool for predicting the time to event, has been used in many domains such as healthcare, criminal justice, and finance. Like classification tasks, survival analysis can exhibit bias against disadvantaged groups, often due to biases inherent in data or algorithms. Several studies in both the IS and CS communities have attempted to address fairness in survival analysis. However, existing methods often overlook the importance of prediction fairness at pre-defined evaluation time points, which is crucial in real-world applications where decision making often hinges on specific time frames. To address this critical research gap, we introduce a new fairness concept: equalized odds (EO) in survival analysis, which emphasizes prediction fairness at pre-defined time points. To achieve the EO fairness in survival analysis, we propose a Conditional Mutual Information Augmentation (CMIA) approach, which features a novel fairness regularization term based on conditional mutual information and an innovative censored data augmentation technique. Our CMIA approach can effectively balance prediction accuracy and fairness, and it is applicable to various survival models. We evaluate the CMIA approach against several state-of-the-art methods within three different application domains, and the results demonstrate that CMIA consistently reduces prediction disparity while maintaining good accuracy and significantly outperforms the other competing methods across multiple datasets and survival models (e.g., linear COX, deep AFT).
TTT4Rec: A Test-Time Training Approach for Rapid Adaption in Sequential Recommendation
Sep 27, 2024Sequential recommendation tasks, which aim to predict the next item a user will interact with, typically rely on models trained solely on historical data. However, in real-world scenarios, user behavior can fluctuate in the long interaction sequences, and training data may be limited to model this dynamics. To address this, Test-Time Training (TTT) offers a novel approach by using self-supervised learning during inference to dynamically update model parameters. This allows the model to adapt to new user interactions in real-time, leading to more accurate recommendations. In this paper, we propose TTT4Rec, a sequential recommendation framework that integrates TTT to better capture dynamic user behavior. By continuously updating model parameters during inference, TTT4Rec is particularly effective in scenarios where user interaction sequences are long, training data is limited, or user behavior is highly variable. We evaluate TTT4Rec on three widely-used recommendation datasets, demonstrating that it achieves performance on par with or exceeding state-of-the-art models. The codes are available at https://github.com/ZhaoqiZachYang/TTT4Rec.
Boosting Factorization Machines via Saliency-Guided Mixup
Jun 17, 2022

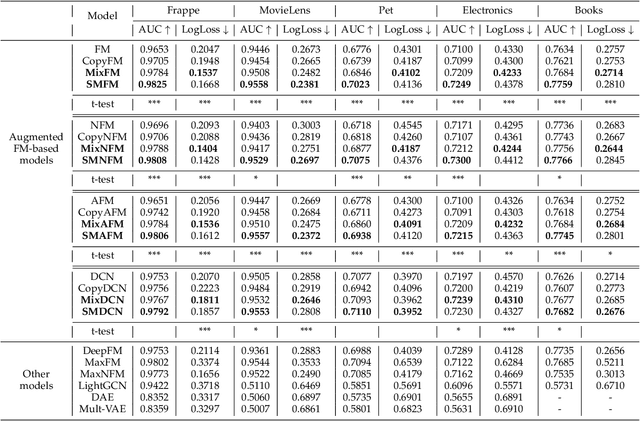

Factorization machines (FMs) are widely used in recommender systems due to their adaptability and ability to learn from sparse data. However, for the ubiquitous non-interactive features in sparse data, existing FMs can only estimate the parameters corresponding to these features via the inner product of their embeddings. Undeniably, they cannot learn the direct interactions of these features, which limits the model's expressive power. To this end, we first present MixFM, inspired by Mixup, to generate auxiliary training data to boost FMs. Unlike existing augmentation strategies that require labor costs and expertise to collect additional information such as position and fields, these extra data generated by MixFM only by the convex combination of the raw ones without any professional knowledge support. More importantly, if the parent samples to be mixed have non-interactive features, MixFM will establish their direct interactions. Second, considering that MixFM may generate redundant or even detrimental instances, we further put forward a novel Factorization Machine powered by Saliency-guided Mixup (denoted as SMFM). Guided by the customized saliency, SMFM can generate more informative neighbor data. Through theoretical analysis, we prove that the proposed methods minimize the upper bound of the generalization error, which hold a beneficial effect on enhancing FMs. Significantly, we give the first generalization bound of FM, implying the generalization requires more data and a smaller embedding size under the sufficient representation capability. Finally, extensive experiments on five datasets confirm that our approaches are superior to baselines. Besides, the results show that "poisoning" mixed data is likewise beneficial to the FM variants.
Offline Meta-level Model-based Reinforcement Learning Approach for Cold-Start Recommendation
Dec 04, 2020
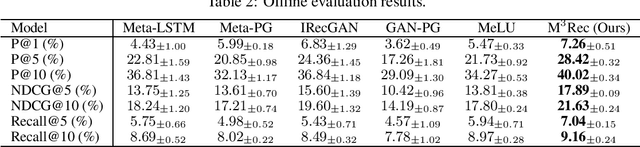
Reinforcement learning (RL) has shown great promise in optimizing long-term user interest in recommender systems. However, existing RL-based recommendation methods need a large number of interactions for each user to learn a robust recommendation policy. The challenge becomes more critical when recommending to new users who have a limited number of interactions. To that end, in this paper, we address the cold-start challenge in the RL-based recommender systems by proposing a meta-level model-based reinforcement learning approach for fast user adaptation. In our approach, we learn to infer each user's preference with a user context variable that enables recommendation systems to better adapt to new users with few interactions. To improve adaptation efficiency, we learn to recover the user policy and reward from only a few interactions via an inverse reinforcement learning method to assist a meta-level recommendation agent. Moreover, we model the interaction relationship between the user model and recommendation agent from an information-theoretic perspective. Empirical results show the effectiveness of the proposed method when adapting to new users with only a single interaction sequence. We further provide a theoretical analysis of the recommendation performance bound.
Interactive Reinforcement Learning for Feature Selection with Decision Tree in the Loop
Oct 02, 2020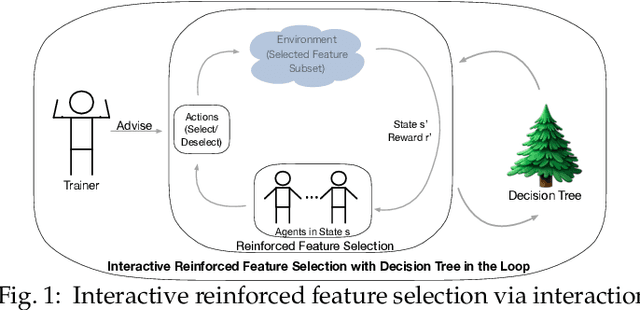



We study the problem of balancing effectiveness and efficiency in automated feature selection. After exploring many feature selection methods, we observe a computational dilemma: 1) traditional feature selection is mostly efficient, but difficult to identify the best subset; 2) the emerging reinforced feature selection automatically navigates to the best subset, but is usually inefficient. Can we bridge the gap between effectiveness and efficiency under automation? Motivated by this dilemma, we aim to develop a novel feature space navigation method. In our preliminary work, we leveraged interactive reinforcement learning to accelerate feature selection by external trainer-agent interaction. In this journal version, we propose a novel interactive and closed-loop architecture to simultaneously model interactive reinforcement learning (IRL) and decision tree feedback (DTF). Specifically, IRL is to create an interactive feature selection loop and DTF is to feed structured feature knowledge back to the loop. First, the tree-structured feature hierarchy from decision tree is leveraged to improve state representation. In particular, we represent the selected feature subset as an undirected graph of feature-feature correlations and a directed tree of decision features. We propose a new embedding method capable of empowering graph convolutional network to jointly learn state representation from both the graph and the tree. Second, the tree-structured feature hierarchy is exploited to develop a new reward scheme. In particular, we personalize reward assignment of agents based on decision tree feature importance. In addition, observing agents' actions can be feedback, we devise another reward scheme, to weigh and assign reward based on the feature selected frequency ratio in historical action records. Finally, we present extensive experiments on real-world datasets to show the improved performance.
AutoFS: Automated Feature Selection via Diversity-aware Interactive Reinforcement Learning
Sep 16, 2020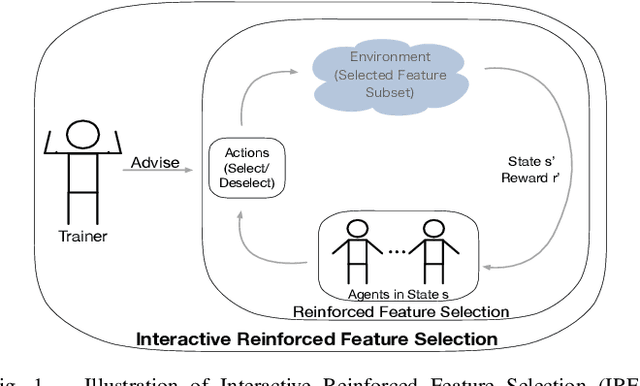

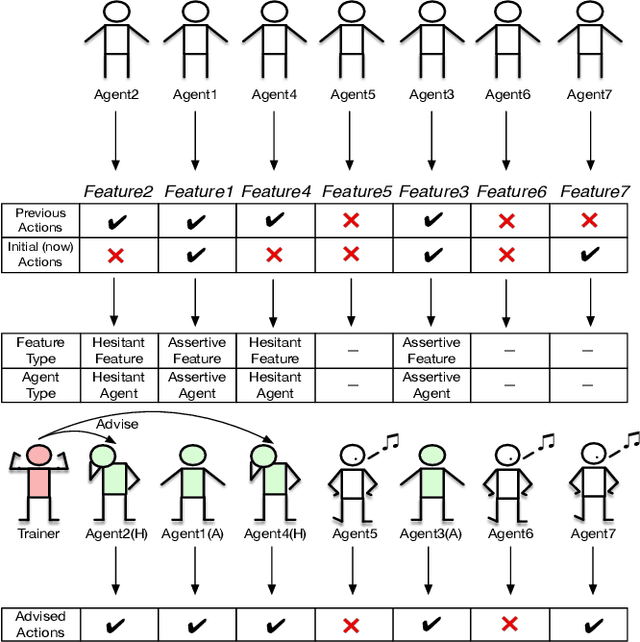
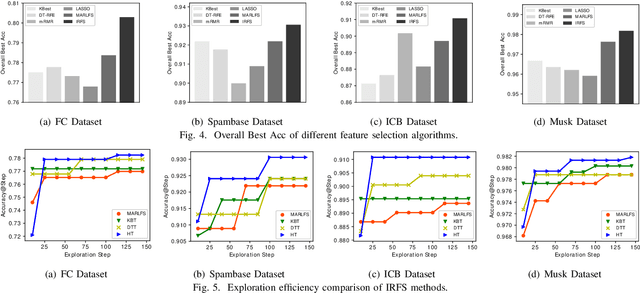
In this paper, we study the problem of balancing effectiveness and efficiency in automated feature selection. Feature selection is a fundamental intelligence for machine learning and predictive analysis. After exploring many feature selection methods, we observe a computational dilemma: 1) traditional feature selection methods (e.g., mRMR) are mostly efficient, but difficult to identify the best subset; 2) the emerging reinforced feature selection methods automatically navigate feature space to explore the best subset, but are usually inefficient. Are automation and efficiency always apart from each other? Can we bridge the gap between effectiveness and efficiency under automation? Motivated by such a computational dilemma, this study is to develop a novel feature space navigation method. To that end, we propose an Interactive Reinforced Feature Selection (IRFS) framework that guides agents by not just self-exploration experience, but also diverse external skilled trainers to accelerate learning for feature exploration. Specifically, we formulate the feature selection problem into an interactive reinforcement learning framework. In this framework, we first model two trainers skilled at different searching strategies: (1) KBest based trainer; (2) Decision Tree based trainer. We then develop two strategies: (1) to identify assertive and hesitant agents to diversify agent training, and (2) to enable the two trainers to take the teaching role in different stages to fuse the experiences of the trainers and diversify teaching process. Such a hybrid teaching strategy can help agents to learn broader knowledge, and, thereafter, be more effective. Finally, we present extensive experiments on real-world datasets to demonstrate the improved performances of our method: more efficient than existing reinforced selection and more effective than classic selection.
Explainable Recommender Systems via Resolving Learning Representations
Aug 21, 2020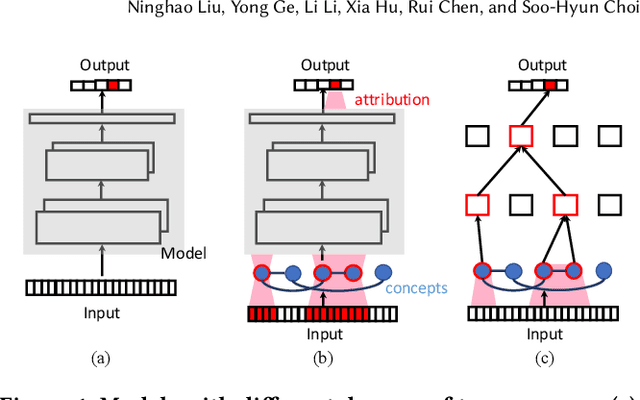


Recommender systems play a fundamental role in web applications in filtering massive information and matching user interests. While many efforts have been devoted to developing more effective models in various scenarios, the exploration on the explainability of recommender systems is running behind. Explanations could help improve user experience and discover system defects. In this paper, after formally introducing the elements that are related to model explainability, we propose a novel explainable recommendation model through improving the transparency of the representation learning process. Specifically, to overcome the representation entangling problem in traditional models, we revise traditional graph convolution to discriminate information from different layers. Also, each representation vector is factorized into several segments, where each segment relates to one semantic aspect in data. Different from previous work, in our model, factor discovery and representation learning are simultaneously conducted, and we are able to handle extra attribute information and knowledge. In this way, the proposed model can learn interpretable and meaningful representations for users and items. Unlike traditional methods that need to make a trade-off between explainability and effectiveness, the performance of our proposed explainable model is not negatively affected after considering explainability. Finally, comprehensive experiments are conducted to validate the performance of our model as well as explanation faithfulness.
DiffNet++: A Neural Influence and Interest Diffusion Network for Social Recommendation
Feb 22, 2020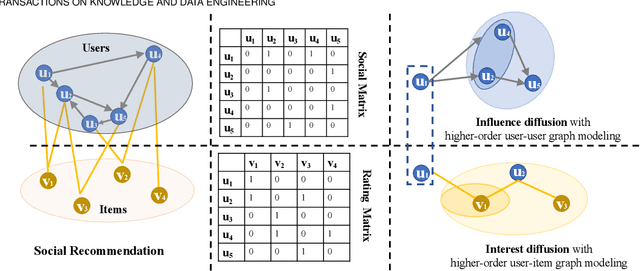
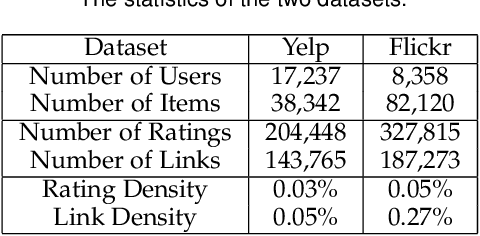
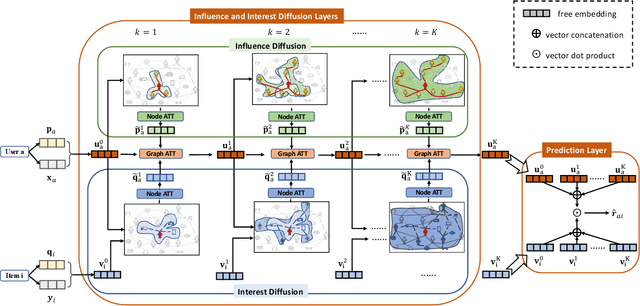
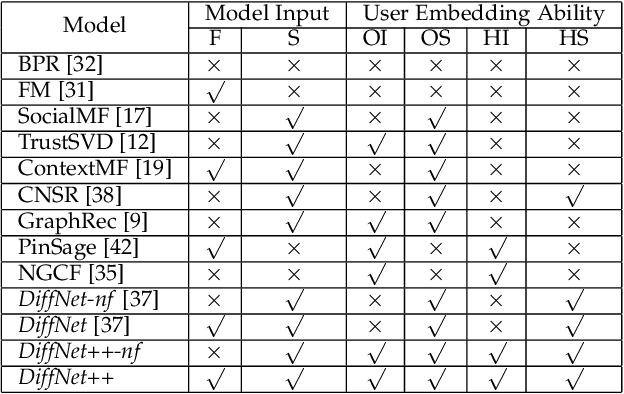
Social recommendation has emerged to leverage social connections among users for predicting users' unknown preferences, which could alleviate the data sparsity issue in collaborative filtering based recommendation. Early approaches relied on utilizing each user's first-order social neighbors' interests for better user modeling and failed to model the social influence diffusion process from the global social network structure. Recently, we propose a preliminary work of a neural influence diffusion network (i.e., DiffNet) for social recommendation (Diffnet), which models the recursive social diffusion process to capture the higher-order relationships for each user. However, we argue that, as users play a central role in both user-user social network and user-item interest network, only modeling the influence diffusion process in the social network would neglect the users' latent collaborative interests in the user-item interest network. In this paper, we propose DiffNet++, an improved algorithm of DiffNet that models the neural influence diffusion and interest diffusion in a unified framework. By reformulating the social recommendation as a heterogeneous graph with social network and interest network as input, DiffNet++ advances DiffNet by injecting these two network information for user embedding learning at the same time. This is achieved by iteratively aggregating each user's embedding from three aspects: the user's previous embedding, the influence aggregation of social neighbors from the social network, and the interest aggregation of item neighbors from the user-item interest network. Furthermore, we design a multi-level attention network that learns how to attentively aggregate user embeddings from these three aspects. Finally, extensive experimental results on two real-world datasets clearly show the effectiveness of our proposed model.
Developing Multi-Task Recommendations with Long-Term Rewards via Policy Distilled Reinforcement Learning
Jan 27, 2020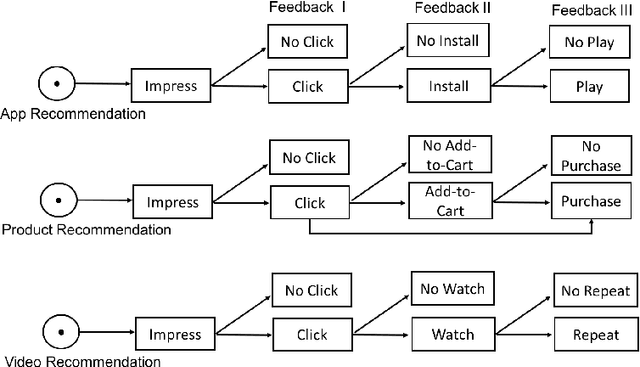

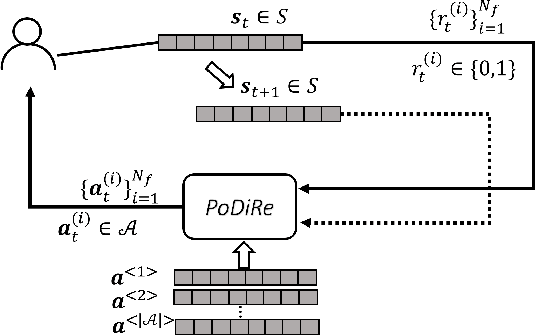
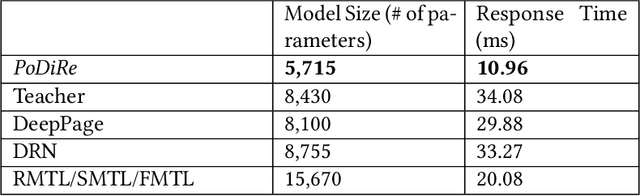
With the explosive growth of online products and content, recommendation techniques have been considered as an effective tool to overcome information overload, improve user experience, and boost business revenue. In recent years, we have observed a new desideratum of considering long-term rewards of multiple related recommendation tasks simultaneously. The consideration of long-term rewards is strongly tied to business revenue and growth. Learning multiple tasks simultaneously could generally improve the performance of individual task due to knowledge sharing in multi-task learning. While a few existing works have studied long-term rewards in recommendations, they mainly focus on a single recommendation task. In this paper, we propose {\it PoDiRe}: a \underline{po}licy \underline{di}stilled \underline{re}commender that can address long-term rewards of recommendations and simultaneously handle multiple recommendation tasks. This novel recommendation solution is based on a marriage of deep reinforcement learning and knowledge distillation techniques, which is able to establish knowledge sharing among different tasks and reduce the size of a learning model. The resulting model is expected to attain better performance and lower response latency for real-time recommendation services. In collaboration with Samsung Game Launcher, one of the world's largest commercial mobile game platforms, we conduct a comprehensive experimental study on large-scale real data with hundreds of millions of events and show that our solution outperforms many state-of-the-art methods in terms of several standard evaluation metrics.