 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMock Worlds, Real Skills: Building Small Agentic Language Models with Synthetic Tasks, Simulated Environments, and Rubric-Based Rewards
Jan 30, 2026Small LLMs often struggle to match the agentic capabilities of large, costly models. While reinforcement learning can help, progress has been limited by two structural bottlenecks: existing open-source agentic training data are narrow in task variety and easily solved; real-world APIs lack diversity and are unstable for large-scale reinforcement learning rollout processes. We address these challenges with SYNTHAGENT, a framework that jointly synthesizes diverse tool-use training data and simulates complete environments. Specifically, a strong teacher model creates novel tasks and tool ecosystems, then rewrites them into intentionally underspecified instructions. This compels agents to actively query users for missing details. When handling synthetic tasks, an LLM-based user simulator provides user-private information, while a mock tool system delivers stable tool responses. For rewards, task-level rubrics are constructed based on required subgoals, user-agent interactions, and forbidden behaviors. Across 14 challenging datasets in math, search, and tool use, models trained on our synthetic data achieve substantial gains, with small models outperforming larger baselines.
Token-level Collaborative Alignment for LLM-based Generative Recommendation
Jan 26, 2026Large Language Models (LLMs) have demonstrated strong potential for generative recommendation by leveraging rich semantic knowledge. However, existing LLM-based recommender systems struggle to effectively incorporate collaborative filtering (CF) signals, due to a fundamental mismatch between item-level preference modeling in CF and token-level next-token prediction (NTP) optimization in LLMs. Prior approaches typically treat CF as contextual hints or representation bias, and resort to multi-stage training to reduce behavioral semantic space discrepancies, leaving CF unable to explicitly regulate LLM generation. In this work, we propose Token-level Collaborative Alignment for Recommendation (TCA4Rec), a model-agnostic and plug-and-play framework that establishes an explicit optimization-level interface between CF supervision and LLM generation. TCA4Rec consists of (i) Collaborative Tokenizer, which projects raw item-level CF logits into token-level distributions aligned with the LLM token space, and (ii) Soft Label Alignment, which integrates these CF-informed distributions with one-hot supervision to optimize a soft NTP objective. This design preserves the generative nature of LLM training while enabling collaborative alignment with essential user preference of CF models. We highlight TCA4Rec is compatible with arbitrary traditional CF models and generalizes across a wide range of decoder-based LLM recommender architectures. Moreover, it provides an explicit mechanism to balance behavioral alignment and semantic fluency, yielding generative recommendations that are both accurate and controllable. Extensive experiments demonstrate that TCA4Rec consistently improves recommendation performance across a broad spectrum of CF models and LLM-based recommender systems.
From Tags to Trees: Structuring Fine-Grained Knowledge for Controllable Data Selection in LLM Instruction Tuning
Jan 20, 2026Effective and controllable data selection is critical for LLM instruction tuning, especially with massive open-source datasets. Existing approaches primarily rely on instance-level quality scores, or diversity metrics based on embedding clusters or semantic tags. However, constrained by the flatness of embedding spaces or the coarseness of tags, these approaches overlook fine-grained knowledge and its intrinsic hierarchical dependencies, consequently hindering precise data valuation and knowledge-aligned sampling. To address this challenge, we propose Tree-aware Aligned Global Sampling (TAGS), a unified framework that leverages a knowledge tree built from fine-grained tags, thereby enabling joint control of global quality, diversity, and target alignment. Using an LLM-based tagger, we extract atomic knowledge concepts, which are organized into a global tree through bottom-up hierarchical clustering. By grounding data instances onto this tree, a tree-aware metric then quantifies data quality and diversity, facilitating effective sampling. Our controllable sampling strategy maximizes tree-level information gain and enforces leaf-level alignment via KL-divergence for specific domains. Extensive experiments demonstrate that TAGS significantly outperforms state-of-the-art baselines. Notably, it surpasses the full-dataset model by \textbf{+5.84\%} using only \textbf{5\%} of the data, while our aligned sampling strategy further boosts average performance by \textbf{+4.24\%}.
DynaDebate: Breaking Homogeneity in Multi-Agent Debate with Dynamic Path Generation
Jan 09, 2026Recent years have witnessed the rapid development of Large Language Model-based Multi-Agent Systems (MAS), which excel at collaborative decision-making and complex problem-solving. Recently, researchers have further investigated Multi-Agent Debate (MAD) frameworks, which enhance the reasoning and collaboration capabilities of MAS through information exchange and debate among multiple agents. However, existing approaches often rely on unguided initialization, causing agents to adopt identical reasoning paths that lead to the same errors. As a result, effective debate among agents is hindered, and the final outcome frequently degenerates into simple majority voting. To solve the above problem, in this paper, we introduce Dynamic Multi-Agent Debate (DynaDebate), which enhances the effectiveness of multi-agent debate through three key mechanisms: (1) Dynamic Path Generation and Allocation, which employs a dedicated Path Generation Agent to generate diverse and logical solution paths with adaptive redundancy; (2) Process-Centric Debate, which shifts the focus from surface-level outcome voting to rigorous step-by-step logic critique to ensure process correctness; (3) A Trigger-Based Verification Agent, which is activated upon disagreement and uses external tools to objectively resolve deadlocks. Extensive experiments demonstrate that DynaDebate achieves superior performance across various benchmarks, surpassing existing state-of-the-art MAD methods.
VIGIL: Defending LLM Agents Against Tool Stream Injection via Verify-Before-Commit
Jan 09, 2026LLM agents operating in open environments face escalating risks from indirect prompt injection, particularly within the tool stream where manipulated metadata and runtime feedback hijack execution flow. Existing defenses encounter a critical dilemma as advanced models prioritize injected rules due to strict alignment while static protection mechanisms sever the feedback loop required for adaptive reasoning. To reconcile this conflict, we propose \textbf{VIGIL}, a framework that shifts the paradigm from restrictive isolation to a verify-before-commit protocol. By facilitating speculative hypothesis generation and enforcing safety through intent-grounded verification, \textbf{VIGIL} preserves reasoning flexibility while ensuring robust control. We further introduce \textbf{SIREN}, a benchmark comprising 959 tool stream injection cases designed to simulate pervasive threats characterized by dynamic dependencies. Extensive experiments demonstrate that \textbf{VIGIL} outperforms state-of-the-art dynamic defenses by reducing the attack success rate by over 22\% while more than doubling the utility under attack compared to static baselines, thereby achieving an optimal balance between security and utility. Code is available at https://anonymous.4open.science/r/VIGIL-378B/.
Look As You Think: Unifying Reasoning and Visual Evidence Attribution for Verifiable Document RAG via Reinforcement Learning
Nov 15, 2025Aiming to identify precise evidence sources from visual documents, visual evidence attribution for visual document retrieval-augmented generation (VD-RAG) ensures reliable and verifiable predictions from vision-language models (VLMs) in multimodal question answering. Most existing methods adopt end-to-end training to facilitate intuitive answer verification. However, they lack fine-grained supervision and progressive traceability throughout the reasoning process. In this paper, we introduce the Chain-of-Evidence (CoE) paradigm for VD-RAG. CoE unifies Chain-of-Thought (CoT) reasoning and visual evidence attribution by grounding reference elements in reasoning steps to specific regions with bounding boxes and page indexes. To enable VLMs to generate such evidence-grounded reasoning, we propose Look As You Think (LAT), a reinforcement learning framework that trains models to produce verifiable reasoning paths with consistent attribution. During training, LAT evaluates the attribution consistency of each evidence region and provides rewards only when the CoE trajectory yields correct answers, encouraging process-level self-verification. Experiments on vanilla Qwen2.5-VL-7B-Instruct with Paper- and Wiki-VISA benchmarks show that LAT consistently improves the vanilla model in both single- and multi-image settings, yielding average gains of 8.23% in soft exact match (EM) and 47.0% in IoU@0.5. Meanwhile, LAT not only outperforms the supervised fine-tuning baseline, which is trained to directly produce answers with attribution, but also exhibits stronger generalization across domains.
TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework
Nov 07, 2025Retrieval-Augmented Generation (RAG) utilizes external knowledge to augment Large Language Models' (LLMs) reliability. For flexibility, agentic RAG employs autonomous, multi-round retrieval and reasoning to resolve queries. Although recent agentic RAG has improved via reinforcement learning, they often incur substantial token overhead from search and reasoning processes. This trade-off prioritizes accuracy over efficiency. To address this issue, this work proposes TeaRAG, a token-efficient agentic RAG framework capable of compressing both retrieval content and reasoning steps. 1) First, the retrieved content is compressed by augmenting chunk-based semantic retrieval with a graph retrieval using concise triplets. A knowledge association graph is then built from semantic similarity and co-occurrence. Finally, Personalized PageRank is leveraged to highlight key knowledge within this graph, reducing the number of tokens per retrieval. 2) Besides, to reduce reasoning steps, Iterative Process-aware Direct Preference Optimization (IP-DPO) is proposed. Specifically, our reward function evaluates the knowledge sufficiency by a knowledge matching mechanism, while penalizing excessive reasoning steps. This design can produce high-quality preference-pair datasets, supporting iterative DPO to improve reasoning conciseness. Across six datasets, TeaRAG improves the average Exact Match by 4% and 2% while reducing output tokens by 61% and 59% on Llama3-8B-Instruct and Qwen2.5-14B-Instruct, respectively. Code is available at https://github.com/Applied-Machine-Learning-Lab/TeaRAG.
A2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning
Sep 26, 2025



Recent Large Reasoning Models have achieved significant improvements in complex task-solving capabilities by allocating more computation at the inference stage with a "thinking longer" paradigm. Even as the foundational reasoning capabilities of models advance rapidly, the persistent gap between a model's performance in a single attempt and its latent potential, often revealed only across multiple solution paths, starkly highlights the disparity between its realized and inherent capabilities. To address this, we present A2R, an Asymmetric Two-Stage Reasoning framework designed to explicitly bridge the gap between a model's potential and its actual performance. In this framework, an "explorer" model first generates potential solutions in parallel through repeated sampling. Subsequently,a "synthesizer" model integrates these references for a more refined, second stage of reasoning. This two-stage process allows computation to be scaled orthogonally to existing sequential methods. Our work makes two key innovations: First, we present A2R as a plug-and-play parallel reasoning framework that explicitly enhances a model's capabilities on complex questions. For example, using our framework, the Qwen3-8B-distill model achieves a 75% performance improvement compared to its self-consistency baseline. Second, through a systematic analysis of the explorer and synthesizer roles, we identify an effective asymmetric scaling paradigm. This insight leads to A2R-Efficient, a "small-to-big" variant that combines a Qwen3-4B explorer with a Qwen3-8B synthesizer. This configuration surpasses the average performance of a monolithic Qwen3-32B model at a nearly 30% lower cost. Collectively, these results show that A2R is not only a performance-boosting framework but also an efficient and practical solution for real-world applications.
Verti-Arena: A Controllable and Standardized Indoor Testbed for Multi-Terrain Off-Road Autonomy
Aug 11, 2025
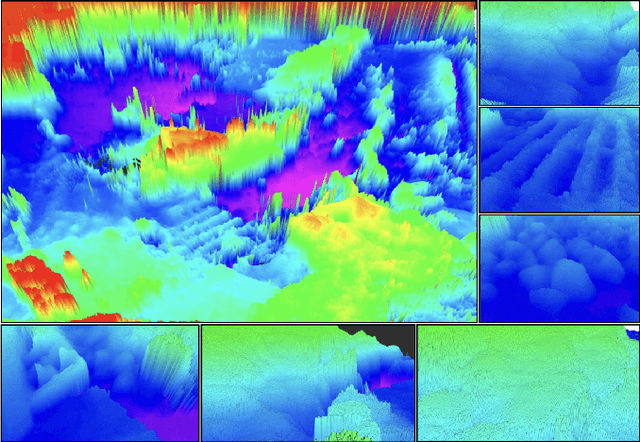
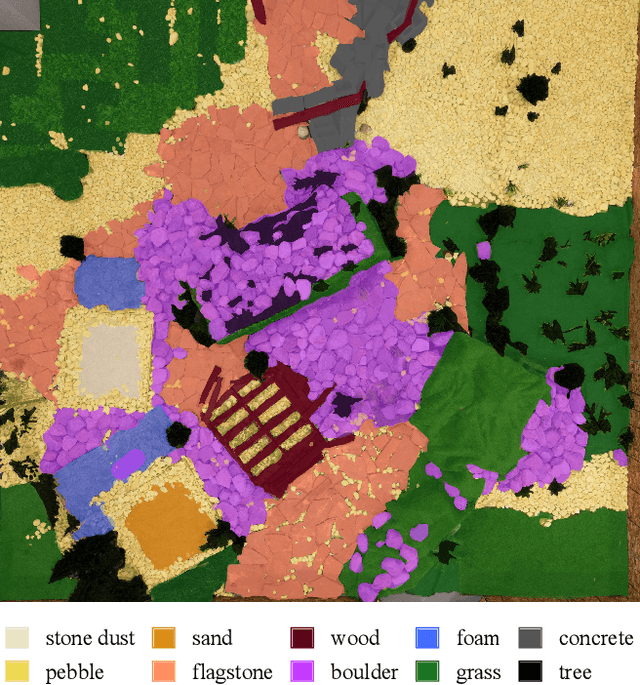
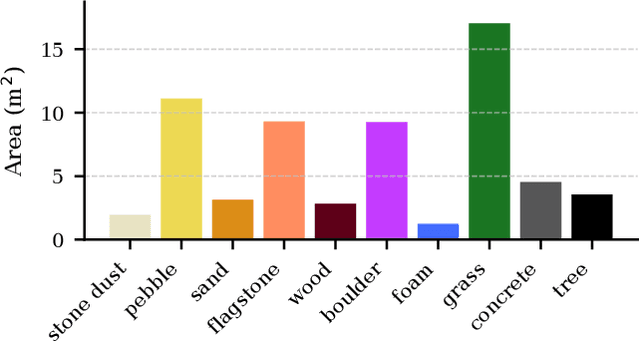
Off-road navigation is an important capability for mobile robots deployed in environments that are inaccessible or dangerous to humans, such as disaster response or planetary exploration. Progress is limited due to the lack of a controllable and standardized real-world testbed for systematic data collection and validation. To fill this gap, we introduce Verti-Arena, a reconfigurable indoor facility designed specifically for off-road autonomy. By providing a repeatable benchmark environment, Verti-Arena supports reproducible experiments across a variety of vertically challenging terrains and provides precise ground truth measurements through onboard sensors and a motion capture system. Verti-Arena also supports consistent data collection and comparative evaluation of algorithms in off-road autonomy research. We also develop a web-based interface that enables research groups worldwide to remotely conduct standardized off-road autonomy experiments on Verti-Arena.
Xiangqi-R1: Enhancing Spatial Strategic Reasoning in LLMs for Chinese Chess via Reinforcement Learning
Jul 16, 2025Game playing has long served as a fundamental benchmark for evaluating Artificial General Intelligence (AGI). While Large Language Models (LLMs) have demonstrated impressive capabilities in general reasoning, their effectiveness in spatial strategic reasoning, which is critical for complex and fully observable board games, remains insufficiently explored. In this work, we adopt Chinese Chess (Xiangqi) as a challenging and rich testbed due to its intricate rules and spatial complexity. To advance LLMs' strategic competence in such environments, we propose a training framework tailored to Xiangqi, built upon a large-scale dataset of five million board-move pairs enhanced with expert annotations and engine evaluations. Building on this foundation, we introduce Xiangqi-R1, a 7B-parameter model trained in multi-stage manner: (1) fine-tuning for legal move prediction to capture basic spatial rules, (2) incorporating strategic annotations to improve decision-making, and (3) applying reinforcement learning via Group Relative Policy Optimization (GRPO) with multi-dimensional reward signals to enhance reasoning stability. Our Experimental results indicate that, despite their size and power, general-purpose LLMs struggle to achieve satisfactory performance in these tasks. Compared to general-purpose LLMs, Xiangqi-R1 greatly advances with an 18% rise in move legality and a 22% boost in analysis accuracy. Our results point to a promising path for creating general strategic intelligence in spatially complex areas.