 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding
Jul 03, 2025The rapid growth of online video content, especially on short video platforms, has created a growing demand for efficient video editing techniques that can condense long-form videos into concise and engaging clips. Existing automatic editing methods predominantly rely on textual cues from ASR transcripts and end-to-end segment selection, often neglecting the rich visual context and leading to incoherent outputs. In this paper, we propose a human-inspired automatic video editing framework (HIVE) that leverages multimodal narrative understanding to address these limitations. Our approach incorporates character extraction, dialogue analysis, and narrative summarization through multimodal large language models, enabling a holistic understanding of the video content. To further enhance coherence, we apply scene-level segmentation and decompose the editing process into three subtasks: highlight detection, opening/ending selection, and pruning of irrelevant content. To facilitate research in this area, we introduce DramaAD, a novel benchmark dataset comprising over 800 short drama episodes and 500 professionally edited advertisement clips. Experimental results demonstrate that our framework consistently outperforms existing baselines across both general and advertisement-oriented editing tasks, significantly narrowing the quality gap between automatic and human-edited videos.
Learning towards Selective Data Augmentation for Dialogue Generation
Mar 17, 2023As it is cumbersome and expensive to acquire a huge amount of data for training neural dialog models, data augmentation is proposed to effectively utilize existing training samples. However, current data augmentation techniques on the dialog generation task mostly augment all cases in the training dataset without considering the intrinsic attributes between different cases. We argue that not all cases are beneficial for augmentation task, and the cases suitable for augmentation should obey the following two attributes: (1) low-quality (the dialog model cannot generate a high-quality response for the case), (2) representative (the case should represent the property of the whole dataset). Herein, we explore this idea by proposing a Selective Data Augmentation framework (SDA) for the response generation task. SDA employs a dual adversarial network to select the lowest quality and most representative data points for augmentation in one stage. Extensive experiments conducted on two publicly available datasets, i.e., DailyDialog and OpenSubtitles, show that our framework can improve the response generation performance with respect to various metrics.
Writing Polishment with Simile: Task, Dataset and A Neural Approach
Dec 15, 2020
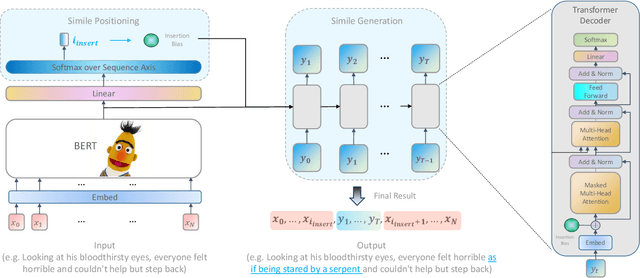
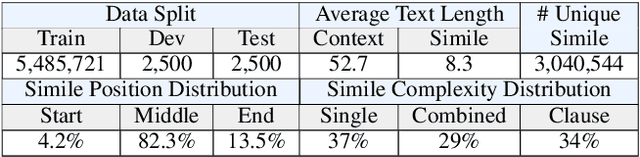

A simile is a figure of speech that directly makes a comparison, showing similarities between two different things, e.g. "Reading papers can be dull sometimes,like watching grass grow". Human writers often interpolate appropriate similes into proper locations of the plain text to vivify their writings. However, none of existing work has explored neural simile interpolation, including both locating and generation. In this paper, we propose a new task of Writing Polishment with Simile (WPS) to investigate whether machines are able to polish texts with similes as we human do. Accordingly, we design a two-staged Locate&Gen model based on transformer architecture. Our model firstly locates where the simile interpolation should happen, and then generates a location-specific simile. We also release a large-scale Chinese Simile (CS) dataset containing 5 million similes with context. The experimental results demonstrate the feasibility of WPS task and shed light on the future research directions towards better automatic text polishment.