 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyScript-100M: 1,000,000,000 Pairs of Scripts and Shooting Scripts for Short Drama
Aug 18, 2024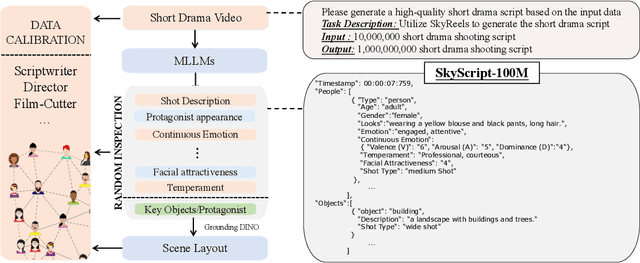
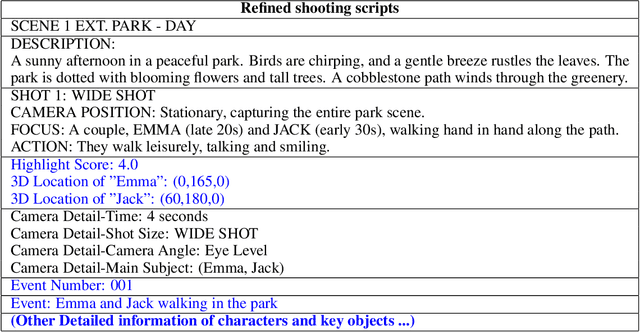
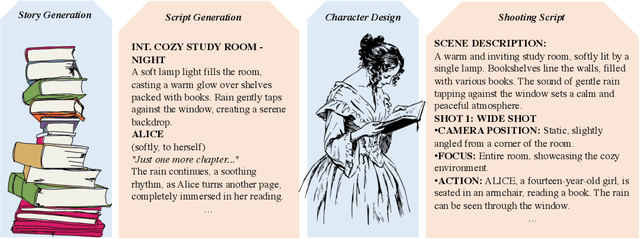
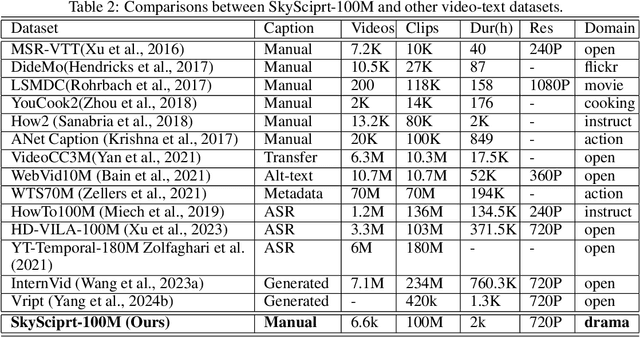
Generating high-quality shooting scripts containing information such as scene and shot language is essential for short drama script generation. We collect 6,660 popular short drama episodes from the Internet, each with an average of 100 short episodes, and the total number of short episodes is about 80,000, with a total duration of about 2,000 hours and totaling 10 terabytes (TB). We perform keyframe extraction and annotation on each episode to obtain about 10,000,000 shooting scripts. We perform 100 script restorations on the extracted shooting scripts based on our self-developed large short drama generation model SkyReels. This leads to a dataset containing 1,000,000,000 pairs of scripts and shooting scripts for short dramas, called SkyScript-100M. We compare SkyScript-100M with the existing dataset in detail and demonstrate some deeper insights that can be achieved based on SkyScript-100M. Based on SkyScript-100M, researchers can achieve several deeper and more far-reaching script optimization goals, which may drive a paradigm shift in the entire field of text-to-video and significantly advance the field of short drama video generation. The data and code are available at https://github.com/vaew/SkyScript-100M.
Towards an Online Empathetic Chatbot with Emotion Causes
May 11, 2021
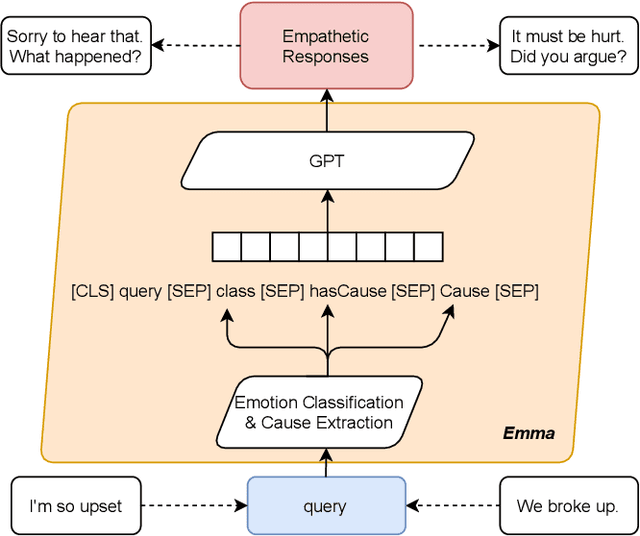

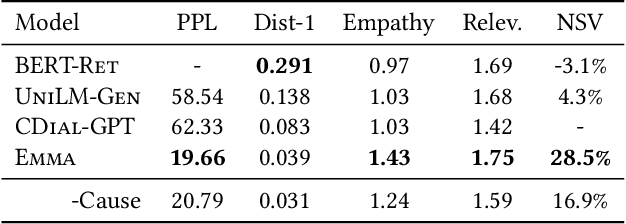
Existing emotion-aware conversational models usually focus on controlling the response contents to align with a specific emotion class, whereas empathy is the ability to understand and concern the feelings and experience of others. Hence, it is critical to learn the causes that evoke the users' emotion for empathetic responding, a.k.a. emotion causes. To gather emotion causes in online environments, we leverage counseling strategies and develop an empathetic chatbot to utilize the causal emotion information. On a real-world online dataset, we verify the effectiveness of the proposed approach by comparing our chatbot with several SOTA methods using automatic metrics, expert-based human judgements as well as user-based online evaluation.
Writing Polishment with Simile: Task, Dataset and A Neural Approach
Dec 15, 2020
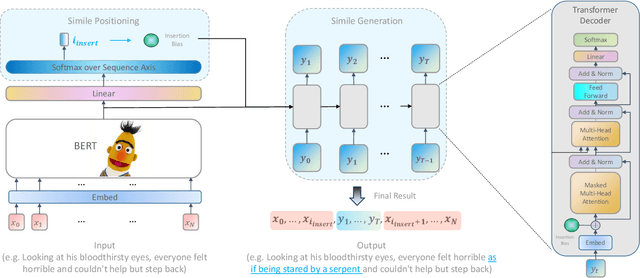
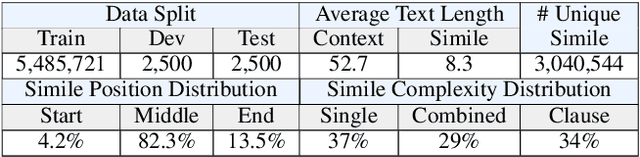

A simile is a figure of speech that directly makes a comparison, showing similarities between two different things, e.g. "Reading papers can be dull sometimes,like watching grass grow". Human writers often interpolate appropriate similes into proper locations of the plain text to vivify their writings. However, none of existing work has explored neural simile interpolation, including both locating and generation. In this paper, we propose a new task of Writing Polishment with Simile (WPS) to investigate whether machines are able to polish texts with similes as we human do. Accordingly, we design a two-staged Locate&Gen model based on transformer architecture. Our model firstly locates where the simile interpolation should happen, and then generates a location-specific simile. We also release a large-scale Chinese Simile (CS) dataset containing 5 million similes with context. The experimental results demonstrate the feasibility of WPS task and shed light on the future research directions towards better automatic text polishment.