 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V3 Technique Report
Jan 24, 2026Video generation serves as a cornerstone for building world models, where multimodal contextual inference stands as the defining test of capability. In this end, we present SkyReels-V3, a conditional video generation model, built upon a unified multimodal in-context learning framework with diffusion Transformers. SkyReels-V3 model supports three core generative paradigms within a single architecture: reference images-to-video synthesis, video-to-video extension and audio-guided video generation. (i) reference images-to-video model is designed to produce high-fidelity videos with strong subject identity preservation, temporal coherence, and narrative consistency. To enhance reference adherence and compositional stability, we design a comprehensive data processing pipeline that leverages cross frame pairing, image editing, and semantic rewriting, effectively mitigating copy paste artifacts. During training, an image video hybrid strategy combined with multi-resolution joint optimization is employed to improve generalization and robustness across diverse scenarios. (ii) video extension model integrates spatio-temporal consistency modeling with large-scale video understanding, enabling both seamless single-shot continuation and intelligent multi-shot switching with professional cinematographic patterns. (iii) Talking avatar model supports minute-level audio-conditioned video generation by training first-and-last frame insertion patterns and reconstructing key-frame inference paradigms. On the basis of ensuring visual quality, synchronization of audio and videos has been optimized. Extensive evaluations demonstrate that SkyReels-V3 achieves state-of-the-art or near state-of-the-art performance on key metrics including visual quality, instruction following, and specific aspect metrics, approaching leading closed-source systems. Github: https://github.com/SkyworkAI/SkyReels-V3.
SkyReels-V2: Infinite-length Film Generative Model
Apr 21, 2025Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs' inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
SkyScript-100M: 1,000,000,000 Pairs of Scripts and Shooting Scripts for Short Drama
Aug 18, 2024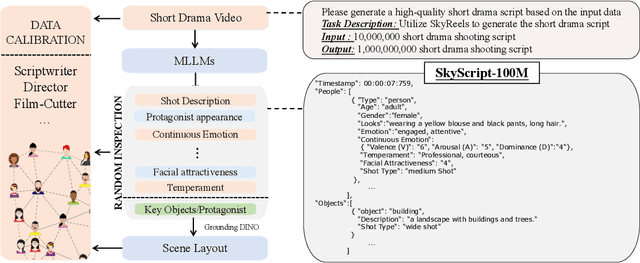
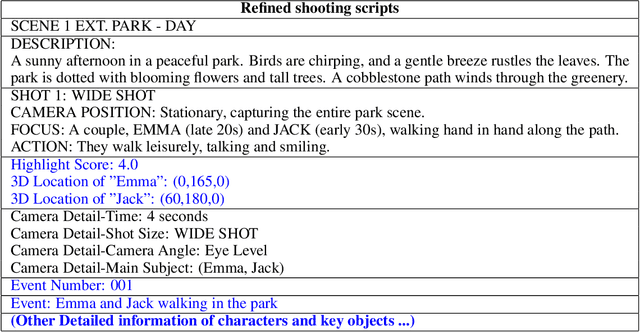
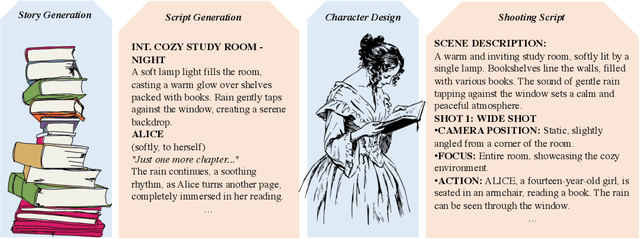
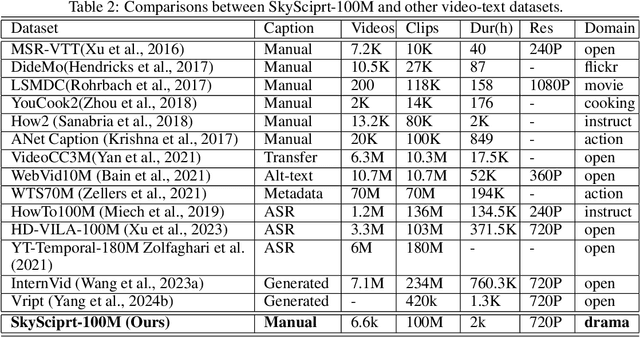
Generating high-quality shooting scripts containing information such as scene and shot language is essential for short drama script generation. We collect 6,660 popular short drama episodes from the Internet, each with an average of 100 short episodes, and the total number of short episodes is about 80,000, with a total duration of about 2,000 hours and totaling 10 terabytes (TB). We perform keyframe extraction and annotation on each episode to obtain about 10,000,000 shooting scripts. We perform 100 script restorations on the extracted shooting scripts based on our self-developed large short drama generation model SkyReels. This leads to a dataset containing 1,000,000,000 pairs of scripts and shooting scripts for short dramas, called SkyScript-100M. We compare SkyScript-100M with the existing dataset in detail and demonstrate some deeper insights that can be achieved based on SkyScript-100M. Based on SkyScript-100M, researchers can achieve several deeper and more far-reaching script optimization goals, which may drive a paradigm shift in the entire field of text-to-video and significantly advance the field of short drama video generation. The data and code are available at https://github.com/vaew/SkyScript-100M.