 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V3 Technique Report
Jan 24, 2026Video generation serves as a cornerstone for building world models, where multimodal contextual inference stands as the defining test of capability. In this end, we present SkyReels-V3, a conditional video generation model, built upon a unified multimodal in-context learning framework with diffusion Transformers. SkyReels-V3 model supports three core generative paradigms within a single architecture: reference images-to-video synthesis, video-to-video extension and audio-guided video generation. (i) reference images-to-video model is designed to produce high-fidelity videos with strong subject identity preservation, temporal coherence, and narrative consistency. To enhance reference adherence and compositional stability, we design a comprehensive data processing pipeline that leverages cross frame pairing, image editing, and semantic rewriting, effectively mitigating copy paste artifacts. During training, an image video hybrid strategy combined with multi-resolution joint optimization is employed to improve generalization and robustness across diverse scenarios. (ii) video extension model integrates spatio-temporal consistency modeling with large-scale video understanding, enabling both seamless single-shot continuation and intelligent multi-shot switching with professional cinematographic patterns. (iii) Talking avatar model supports minute-level audio-conditioned video generation by training first-and-last frame insertion patterns and reconstructing key-frame inference paradigms. On the basis of ensuring visual quality, synchronization of audio and videos has been optimized. Extensive evaluations demonstrate that SkyReels-V3 achieves state-of-the-art or near state-of-the-art performance on key metrics including visual quality, instruction following, and specific aspect metrics, approaching leading closed-source systems. Github: https://github.com/SkyworkAI/SkyReels-V3.
SkyReels-V2: Infinite-length Film Generative Model
Apr 21, 2025Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs' inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
SkyReels-A2: Compose Anything in Video Diffusion Transformers
Apr 03, 2025



This paper presents SkyReels-A2, a controllable video generation framework capable of assembling arbitrary visual elements (e.g., characters, objects, backgrounds) into synthesized videos based on textual prompts while maintaining strict consistency with reference images for each element. We term this task elements-to-video (E2V), whose primary challenges lie in preserving the fidelity of each reference element, ensuring coherent composition of the scene, and achieving natural outputs. To address these, we first design a comprehensive data pipeline to construct prompt-reference-video triplets for model training. Next, we propose a novel image-text joint embedding model to inject multi-element representations into the generative process, balancing element-specific consistency with global coherence and text alignment. We also optimize the inference pipeline for both speed and output stability. Moreover, we introduce a carefully curated benchmark for systematic evaluation, i.e, A2 Bench. Experiments demonstrate that our framework can generate diverse, high-quality videos with precise element control. SkyReels-A2 is the first open-source commercial grade model for the generation of E2V, performing favorably against advanced closed-source commercial models. We anticipate SkyReels-A2 will advance creative applications such as drama and virtual e-commerce, pushing the boundaries of controllable video generation.
Ingredients: Blending Custom Photos with Video Diffusion Transformers
Jan 03, 2025



This paper presents a powerful framework to customize video creations by incorporating multiple specific identity (ID) photos, with video diffusion Transformers, referred to as \texttt{Ingredients}. Generally, our method consists of three primary modules: (\textbf{i}) a facial extractor that captures versatile and precise facial features for each human ID from both global and local perspectives; (\textbf{ii}) a multi-scale projector that maps face embeddings into the contextual space of image query in video diffusion transformers; (\textbf{iii}) an ID router that dynamically combines and allocates multiple ID embedding to the corresponding space-time regions. Leveraging a meticulously curated text-video dataset and a multi-stage training protocol, \texttt{Ingredients} demonstrates superior performance in turning custom photos into dynamic and personalized video content. Qualitative evaluations highlight the advantages of proposed method, positioning it as a significant advancement toward more effective generative video control tools in Transformer-based architecture, compared to existing methods. The data, code, and model weights are publicly available at: \url{https://github.com/feizc/Ingredients}.
Video Diffusion Transformers are In-Context Learners
Dec 14, 2024


This paper investigates a solution for enabling in-context capabilities of video diffusion transformers, with minimal tuning required for activation. Specifically, we propose a simple pipeline to leverage in-context generation: ($\textbf{i}$) concatenate videos along spacial or time dimension, ($\textbf{ii}$) jointly caption multi-scene video clips from one source, and ($\textbf{iii}$) apply task-specific fine-tuning using carefully curated small datasets. Through a series of diverse controllable tasks, we demonstrate qualitatively that existing advanced text-to-video models can effectively perform in-context generation. Notably, it allows for the creation of consistent multi-scene videos exceeding 30 seconds in duration, without additional computational overhead. Importantly, this method requires no modifications to the original models, results in high-fidelity video outputs that better align with prompt specifications and maintain role consistency. Our framework presents a valuable tool for the research community and offers critical insights for advancing product-level controllable video generation systems. The data, code, and model weights are publicly available at: \url{https://github.com/feizc/Video-In-Context}.
FLUX that Plays Music
Sep 01, 2024

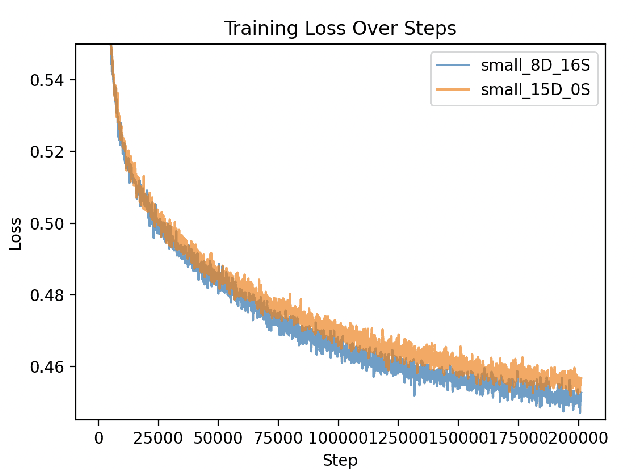

This paper explores a simple extension of diffusion-based rectified flow Transformers for text-to-music generation, termed as FluxMusic. Generally, along with design in advanced Flux\footnote{https://github.com/black-forest-labs/flux} model, we transfers it into a latent VAE space of mel-spectrum. It involves first applying a sequence of independent attention to the double text-music stream, followed by a stacked single music stream for denoised patch prediction. We employ multiple pre-trained text encoders to sufficiently capture caption semantic information as well as inference flexibility. In between, coarse textual information, in conjunction with time step embeddings, is utilized in a modulation mechanism, while fine-grained textual details are concatenated with the music patch sequence as inputs. Through an in-depth study, we demonstrate that rectified flow training with an optimized architecture significantly outperforms established diffusion methods for the text-to-music task, as evidenced by various automatic metrics and human preference evaluations. Our experimental data, code, and model weights are made publicly available at: \url{https://github.com/feizc/FluxMusic}.
Scaling Diffusion Transformers to 16 Billion Parameters
Jul 16, 2024In this paper, we present DiT-MoE, a sparse version of the diffusion Transformer, that is scalable and competitive with dense networks while exhibiting highly optimized inference. The DiT-MoE includes two simple designs: shared expert routing and expert-level balance loss, thereby capturing common knowledge and reducing redundancy among the different routed experts. When applied to conditional image generation, a deep analysis of experts specialization gains some interesting observations: (i) Expert selection shows preference with spatial position and denoising time step, while insensitive with different class-conditional information; (ii) As the MoE layers go deeper, the selection of experts gradually shifts from specific spacial position to dispersion and balance. (iii) Expert specialization tends to be more concentrated at the early time step and then gradually uniform after half. We attribute it to the diffusion process that first models the low-frequency spatial information and then high-frequency complex information. Based on the above guidance, a series of DiT-MoE experimentally achieves performance on par with dense networks yet requires much less computational load during inference. More encouragingly, we demonstrate the potential of DiT-MoE with synthesized image data, scaling diffusion model at a 16.5B parameter that attains a new SoTA FID-50K score of 1.80 in 512$\times$512 resolution settings. The project page: https://github.com/feizc/DiT-MoE.
Dimba: Transformer-Mamba Diffusion Models
Jun 03, 2024



This paper unveils Dimba, a new text-to-image diffusion model that employs a distinctive hybrid architecture combining Transformer and Mamba elements. Specifically, Dimba sequentially stacked blocks alternate between Transformer and Mamba layers, and integrate conditional information through the cross-attention layer, thus capitalizing on the advantages of both architectural paradigms. We investigate several optimization strategies, including quality tuning, resolution adaption, and identify critical configurations necessary for large-scale image generation. The model's flexible design supports scenarios that cater to specific resource constraints and objectives. When scaled appropriately, Dimba offers substantial throughput and a reduced memory footprint relative to conventional pure Transformers-based benchmarks. Extensive experiments indicate that Dimba achieves comparable performance compared with benchmarks in terms of image quality, artistic rendering, and semantic control. We also report several intriguing properties of architecture discovered during evaluation and release checkpoints in experiments. Our findings emphasize the promise of large-scale hybrid Transformer-Mamba architectures in the foundational stage of diffusion models, suggesting a bright future for text-to-image generation.
Music Consistency Models
Apr 20, 2024Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (\texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the \texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of computational efficiency, fidelity, and naturalness. Notable, \texttt{MusicCM} achieves seamless music synthesis with a mere four sampling steps, e.g., only one second per minute of the music clip, showcasing the potential for real-time application.
Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models
Apr 06, 2024



Transformers have catalyzed advancements in computer vision and natural language processing (NLP) fields. However, substantial computational complexity poses limitations for their application in long-context tasks, such as high-resolution image generation. This paper introduces a series of architectures adapted from the RWKV model used in the NLP, with requisite modifications tailored for diffusion model applied to image generation tasks, referred to as Diffusion-RWKV. Similar to the diffusion with Transformers, our model is designed to efficiently handle patchnified inputs in a sequence with extra conditions, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage manifests in its reduced spatial aggregation complexity, rendering it exceptionally adept at processing high-resolution images, thereby eliminating the necessity for windowing or group cached operations. Experimental results on both condition and unconditional image generation tasks demonstrate that Diffison-RWKV achieves performance on par with or surpasses existing CNN or Transformer-based diffusion models in FID and IS metrics while significantly reducing total computation FLOP usage.