 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Diffusion Transformers to 16 Billion Parameters
Paper and Code


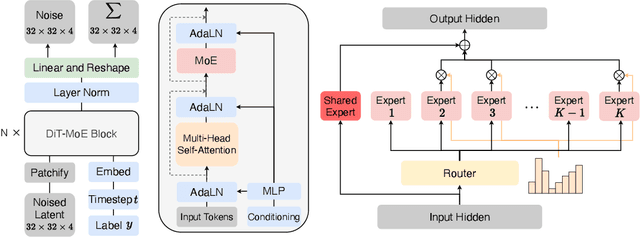

In this paper, we present DiT-MoE, a sparse version of the diffusion Transformer, that is scalable and competitive with dense networks while exhibiting highly optimized inference. The DiT-MoE includes two simple designs: shared expert routing and expert-level balance loss, thereby capturing common knowledge and reducing redundancy among the different routed experts. When applied to conditional image generation, a deep analysis of experts specialization gains some interesting observations: (i) Expert selection shows preference with spatial position and denoising time step, while insensitive with different class-conditional information; (ii) As the MoE layers go deeper, the selection of experts gradually shifts from specific spacial position to dispersion and balance. (iii) Expert specialization tends to be more concentrated at the early time step and then gradually uniform after half. We attribute it to the diffusion process that first models the low-frequency spatial information and then high-frequency complex information. Based on the above guidance, a series of DiT-MoE experimentally achieves performance on par with dense networks yet requires much less computational load during inference. More encouragingly, we demonstrate the potential of DiT-MoE with synthesized image data, scaling diffusion model at a 16.5B parameter that attains a new SoTA FID-50K score of 1.80 in 512$\times$512 resolution settings. The project page: https://github.com/feizc/DiT-MoE.