 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration Data Trade-offs Across Capability Dimensions: Why Multi-Source Mixing Matters for High-Sparsity LLM Pruning
Jun 02, 2026Post-training pruning compresses large language models to high sparsity using a small unlabelled calibration set, and recent work has concluded that the choice of calibration source has only modest impact on averaged post-pruning accuracy. We ask whether this conclusion survives once calibration impact is evaluated separately across distinct capability dimensions rather than aggregated. Decomposing post-pruning capability into General, Commonsense, Code, and Math, and analysing $n{=}15$ calibration sources via Spearman correlations between OIT information metrics and per-dimension retention, we uncover an opposite-sign trade-off: calibration perplexity correlates positively with General retention ($ρ{=}{+}0.71$) but negatively with Math and Code retention ($ρ{=}{-}0.53,\,{-}0.59$; $p{<}0.05$), so no single source can preserve all capabilities. We respond with multi-source calibration mixing, and propose IGSP, an information-guided self-calibration protocol that automates multi-source construction without capability-aligned corpora by minimising 4-gram aggregation and balancing perplexity across dimensions. On LLaMA-3.1-8B at SparseGPT 60% sparsity, a uniform multi-source mix reaches 58.8% total retention, outperforming the best single source (MetaMath, 50.0%) by $+8.8$ and the C4 default (40.0%) by $+18.8$; IGSP improves over Self-Cal by $+2.4$ and SGS by $+4.8$.
LiWi: Layering in the Wild
May 14, 2026Recent advances in generative models have empowered impressive layered image generation, yet their success is largely confined to graphic design domains. The layering of in-the-wild images remains an underexplored problem, limiting fine-grained editing and applications of images in real-world scenarios. Specifically, challenges remain in scalable layered data and the modeling of object interaction in natural images, such as illumination effects and structural boundary. To address these bottlenecks, we propose a novel framework for high-fidelity natural image decomposition. First, we introduce an Agent-driven Data Decomposition (ADD) pipeline that orchestrates agents and tools to synthesize layered data without manual intervention. Utilizing this pipeline, we construct a large-scale dataset, named LiWi-100k, with over 100,000 high-quality layered in-the-wild images. Second, we present a novel framework that jointly improves photometric fidelity and alpha boundary accuracy. Specifically, shadow-guided learning explicitly models the illumination effects, and degradation-restoration objective provides boundary-correction supervision by recovering clean foreground image from degraded one. Extensive experiments demonstrate that our framework achieves state-of-the-art (SoTA) performance in natural image decomposition, outperforming existing models in RGB L1 and Alpha IoU metrics. We will soon release our code and dataset.
Fashion130K: An E-commerce Fashion Dataset for Outfit Generation with Unified Multi-modal Condition
May 11, 2026Recent research work on fashion outfit generation focuses on promoting visual consistency of garments by leveraging key information from reference image and text prompt. However, the potential of outfit generation remains underexplored, requiring comprehensive e-commercial dataset and elaborative utilization of multi-modal condition. In this paper, we propose a brand-new e-commerce dataset, named Fashion130k, with various occasions, models, and garment types. For the consistent generation of garment, we design a framework with Unified Multi-modal Condition (UMC) to align and integrate the text and visual prompts into generation model. Specifically, we explore an embedding refiner to extract the unified embeddings of multi-modal prompts, within which a Fusion Transformer is proposed to align the multi-modal embeddings by adjusting the modality gap between text and image. Based on unified embeddings, the attention in generation model is redesigned to emphasis the correlations between prompts and noise image, inducing that the noise image can select the pivotal tokens of prompts for consistent outfit generation. Our dataset and proposed framework offer a general and nuanced exploration of multi-modal prompts for generation models. Extensive experiments on real-world applications and benchmark demonstrate the effectiveness of UMC in visual consistency, achieving promising result than that of SoTA methods.
Meta-TTRL: A Metacognitive Framework for Self-Improving Test-Time Reinforcement Learning in Unified Multimodal Models
Mar 16, 2026Existing test-time scaling (TTS) methods for unified multimodal models (UMMs) in text-to-image (T2I) generation primarily rely on search or sampling strategies that produce only instance-level improvements, limiting the ability to learn from prior inferences and accumulate knowledge across similar prompts. To overcome these limitations, we propose Meta-TTRL, a metacognitive test-time reinforcement learning framework. Meta-TTRL performs test-time parameter optimization guided by model-intrinsic monitoring signals derived from the meta-knowledge of UMMs, achieving self-improvement and capability-level improvement at test time. Extensive experiments demonstrate that Meta-TTRL generalizes well across three representative UMMs, including Janus-Pro-7B, BAGEL, and Qwen-Image, achieving significant gains on compositional reasoning tasks and multiple T2I benchmarks with limited data. We provide the first comprehensive analysis to investigate the potential of test-time reinforcement learning (TTRL) for T2I generation in UMMs. Our analysis further reveals a key insight underlying effective TTRL: metacognitive synergy, where monitoring signals align with the model's optimization regime to enable self-improvement.
UM-Text: A Unified Multimodal Model for Image Understanding
Jan 13, 2026With the rapid advancement of image generation, visual text editing using natural language instructions has received increasing attention. The main challenge of this task is to fully understand the instruction and reference image, and thus generate visual text that is style-consistent with the image. Previous methods often involve complex steps of specifying the text content and attributes, such as font size, color, and layout, without considering the stylistic consistency with the reference image. To address this, we propose UM-Text, a unified multimodal model for context understanding and visual text editing by natural language instructions. Specifically, we introduce a Visual Language Model (VLM) to process the instruction and reference image, so that the text content and layout can be elaborately designed according to the context information. To generate an accurate and harmonious visual text image, we further propose the UM-Encoder to combine the embeddings of various condition information, where the combination is automatically configured by VLM according to the input instruction. During training, we propose a regional consistency loss to offer more effective supervision for glyph generation on both latent and RGB space, and design a tailored three-stage training strategy to further enhance model performance. In addition, we contribute the UM-DATA-200K, a large-scale visual text image dataset on diverse scenes for model training. Extensive qualitative and quantitative results on multiple public benchmarks demonstrate that our method achieves state-of-the-art performance.
RePainter: Empowering E-commerce Object Removal via Spatial-matting Reinforcement Learning
Oct 09, 2025In web data, product images are central to boosting user engagement and advertising efficacy on e-commerce platforms, yet the intrusive elements such as watermarks and promotional text remain major obstacles to delivering clear and appealing product visuals. Although diffusion-based inpainting methods have advanced, they still face challenges in commercial settings due to unreliable object removal and limited domain-specific adaptation. To tackle these challenges, we propose Repainter, a reinforcement learning framework that integrates spatial-matting trajectory refinement with Group Relative Policy Optimization (GRPO). Our approach modulates attention mechanisms to emphasize background context, generating higher-reward samples and reducing unwanted object insertion. We also introduce a composite reward mechanism that balances global, local, and semantic constraints, effectively reducing visual artifacts and reward hacking. Additionally, we contribute EcomPaint-100K, a high-quality, large-scale e-commerce inpainting dataset, and a standardized benchmark EcomPaint-Bench for fair evaluation. Extensive experiments demonstrate that Repainter significantly outperforms state-of-the-art methods, especially in challenging scenes with intricate compositions. We will release our code and weights upon acceptance.
JoyGen: Audio-Driven 3D Depth-Aware Talking-Face Video Editing
Jan 03, 2025



Significant progress has been made in talking-face video generation research; however, precise lip-audio synchronization and high visual quality remain challenging in editing lip shapes based on input audio. This paper introduces JoyGen, a novel two-stage framework for talking-face generation, comprising audio-driven lip motion generation and visual appearance synthesis. In the first stage, a 3D reconstruction model and an audio2motion model predict identity and expression coefficients respectively. Next, by integrating audio features with a facial depth map, we provide comprehensive supervision for precise lip-audio synchronization in facial generation. Additionally, we constructed a Chinese talking-face dataset containing 130 hours of high-quality video. JoyGen is trained on the open-source HDTF dataset and our curated dataset. Experimental results demonstrate superior lip-audio synchronization and visual quality achieved by our method.
FLUX that Plays Music
Sep 01, 2024


This paper explores a simple extension of diffusion-based rectified flow Transformers for text-to-music generation, termed as FluxMusic. Generally, along with design in advanced Flux\footnote{https://github.com/black-forest-labs/flux} model, we transfers it into a latent VAE space of mel-spectrum. It involves first applying a sequence of independent attention to the double text-music stream, followed by a stacked single music stream for denoised patch prediction. We employ multiple pre-trained text encoders to sufficiently capture caption semantic information as well as inference flexibility. In between, coarse textual information, in conjunction with time step embeddings, is utilized in a modulation mechanism, while fine-grained textual details are concatenated with the music patch sequence as inputs. Through an in-depth study, we demonstrate that rectified flow training with an optimized architecture significantly outperforms established diffusion methods for the text-to-music task, as evidenced by various automatic metrics and human preference evaluations. Our experimental data, code, and model weights are made publicly available at: \url{https://github.com/feizc/FluxMusic}.
Scaling Diffusion Transformers to 16 Billion Parameters
Jul 16, 2024

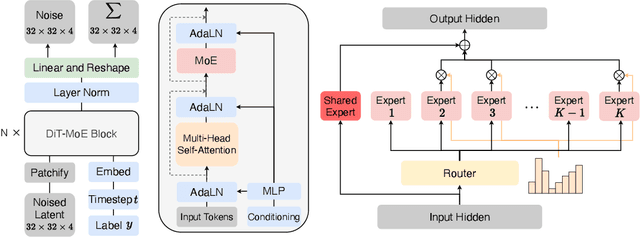

In this paper, we present DiT-MoE, a sparse version of the diffusion Transformer, that is scalable and competitive with dense networks while exhibiting highly optimized inference. The DiT-MoE includes two simple designs: shared expert routing and expert-level balance loss, thereby capturing common knowledge and reducing redundancy among the different routed experts. When applied to conditional image generation, a deep analysis of experts specialization gains some interesting observations: (i) Expert selection shows preference with spatial position and denoising time step, while insensitive with different class-conditional information; (ii) As the MoE layers go deeper, the selection of experts gradually shifts from specific spacial position to dispersion and balance. (iii) Expert specialization tends to be more concentrated at the early time step and then gradually uniform after half. We attribute it to the diffusion process that first models the low-frequency spatial information and then high-frequency complex information. Based on the above guidance, a series of DiT-MoE experimentally achieves performance on par with dense networks yet requires much less computational load during inference. More encouragingly, we demonstrate the potential of DiT-MoE with synthesized image data, scaling diffusion model at a 16.5B parameter that attains a new SoTA FID-50K score of 1.80 in 512$\times$512 resolution settings. The project page: https://github.com/feizc/DiT-MoE.
Dimba: Transformer-Mamba Diffusion Models
Jun 03, 2024



This paper unveils Dimba, a new text-to-image diffusion model that employs a distinctive hybrid architecture combining Transformer and Mamba elements. Specifically, Dimba sequentially stacked blocks alternate between Transformer and Mamba layers, and integrate conditional information through the cross-attention layer, thus capitalizing on the advantages of both architectural paradigms. We investigate several optimization strategies, including quality tuning, resolution adaption, and identify critical configurations necessary for large-scale image generation. The model's flexible design supports scenarios that cater to specific resource constraints and objectives. When scaled appropriately, Dimba offers substantial throughput and a reduced memory footprint relative to conventional pure Transformers-based benchmarks. Extensive experiments indicate that Dimba achieves comparable performance compared with benchmarks in terms of image quality, artistic rendering, and semantic control. We also report several intriguing properties of architecture discovered during evaluation and release checkpoints in experiments. Our findings emphasize the promise of large-scale hybrid Transformer-Mamba architectures in the foundational stage of diffusion models, suggesting a bright future for text-to-image generation.