 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboPocket: Improve Robot Policies Instantly with Your Phone
Mar 05, 2026Scaling imitation learning is fundamentally constrained by the efficiency of data collection. While handheld interfaces have emerged as a scalable solution for in-the-wild data acquisition, they predominantly operate in an open-loop manner: operators blindly collect demonstrations without knowing the underlying policy's weaknesses, leading to inefficient coverage of critical state distributions. Conversely, interactive methods like DAgger effectively address covariate shift but rely on physical robot execution, which is costly and difficult to scale. To reconcile this trade-off, we introduce RoboPocket, a portable system that enables Robot-Free Instant Policy Iteration using single consumer smartphones. Its core innovation is a Remote Inference framework that visualizes the policy's predicted trajectory via Augmented Reality (AR) Visual Foresight. This immersive feedback allows collectors to proactively identify potential failures and focus data collection on the policy's weak regions without requiring a physical robot. Furthermore, we implement an asynchronous Online Finetuning pipeline that continuously updates the policy with incoming data, effectively closing the learning loop in minutes. Extensive experiments demonstrate that RoboPocket adheres to data scaling laws and doubles the data efficiency compared to offline scaling strategies, overcoming their long-standing efficiency bottleneck. Moreover, our instant iteration loop also boosts sample efficiency by up to 2$\times$ in distributed environments a small number of interactive corrections per person. Project page and videos: https://robo-pocket.github.io.
Rethinking Camera Choice: An Empirical Study on Fisheye Camera Properties in Robotic Manipulation
Mar 02, 2026The adoption of fisheye cameras in robotic manipulation, driven by their exceptionally wide Field of View (FoV), is rapidly outpacing a systematic understanding of their downstream effects on policy learning. This paper presents the first comprehensive empirical study to bridge this gap, rigorously analyzing the properties of wrist-mounted fisheye cameras for imitation learning. Through extensive experiments in both simulation and the real world, we investigate three critical research questions: spatial localization, scene generalization, and hardware generalization. Our investigation reveals that: (1) The wide FoV significantly enhances spatial localization, but this benefit is critically contingent on the visual complexity of the environment. (2) Fisheye-trained policies, while prone to overfitting in simple scenes, unlock superior scene generalization when trained with sufficient environmental diversity. (3) While naive cross-camera transfer leads to failures, we identify the root cause as scale overfitting and demonstrate that hardware generalization performance can be improved with a simple Random Scale Augmentation (RSA) strategy. Collectively, our findings provide concrete, actionable guidance for the large-scale collection and effective use of fisheye datasets in robotic learning. More results and videos are available on https://robo-fisheye.github.io/
ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning
Dec 11, 2025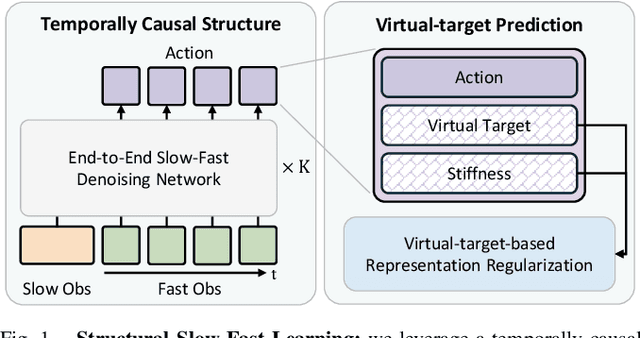
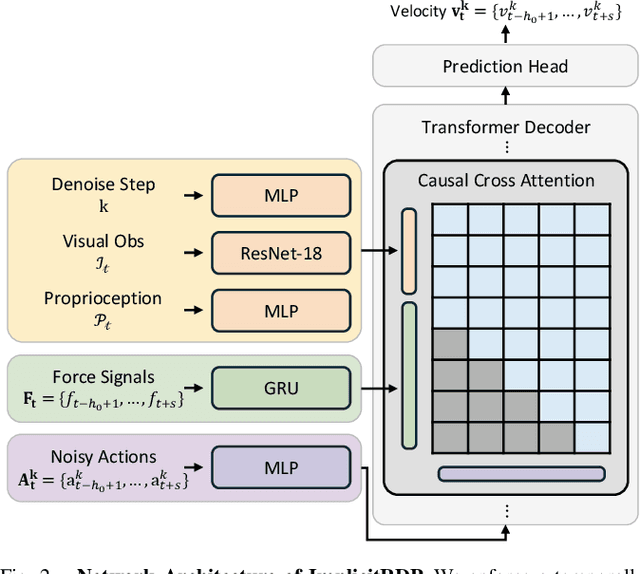


Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities. In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks. Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction. Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline. Code and videos will be publicly available at https://implicit-rdp.github.io.
ARMADA: Autonomous Online Failure Detection and Human Shared Control Empower Scalable Real-world Deployment and Adaptation
Oct 02, 2025Imitation learning has shown promise in learning from large-scale real-world datasets. However, pretrained policies usually perform poorly without sufficient in-domain data. Besides, human-collected demonstrations entail substantial labour and tend to encompass mixed-quality data and redundant information. As a workaround, human-in-the-loop systems gather domain-specific data for policy post-training, and exploit closed-loop policy feedback to offer informative guidance, but usually require full-time human surveillance during policy rollout. In this work, we devise ARMADA, a multi-robot deployment and adaptation system with human-in-the-loop shared control, featuring an autonomous online failure detection method named FLOAT. Thanks to FLOAT, ARMADA enables paralleled policy rollout and requests human intervention only when necessary, significantly reducing reliance on human supervision. Hence, ARMADA enables efficient acquisition of in-domain data, and leads to more scalable deployment and faster adaptation to new scenarios. We evaluate the performance of ARMADA on four real-world tasks. FLOAT achieves nearly 95% accuracy on average, surpassing prior state-of-the-art failure detection approaches by over 20%. Besides, ARMADA manifests more than 4$\times$ increase in success rate and greater than 2$\times$ reduction in human intervention rate over multiple rounds of policy rollout and post-training, compared to previous human-in-the-loop learning methods.
Generalizable Articulated Object Reconstruction from Casually Captured RGBD Videos
Jun 10, 2025Articulated objects are prevalent in daily life. Understanding their kinematic structure and reconstructing them have numerous applications in embodied AI and robotics. However, current methods require carefully captured data for training or inference, preventing practical, scalable, and generalizable reconstruction of articulated objects. We focus on reconstruction of an articulated object from a casually captured RGBD video shot with a hand-held camera. A casually captured video of an interaction with an articulated object is easy to acquire at scale using smartphones. However, this setting is quite challenging, as the object and camera move simultaneously and there are significant occlusions as the person interacts with the object. To tackle these challenges, we introduce a coarse-to-fine framework that infers joint parameters and segments movable parts of the object from a dynamic RGBD video. To evaluate our method under this new setting, we build a 20$\times$ larger synthetic dataset of 784 videos containing 284 objects across 11 categories. We compare our approach with existing methods that also take video as input. Experiments show that our method can reconstruct synthetic and real articulated objects across different categories from dynamic RGBD videos, outperforming existing methods significantly.
SIME: Enhancing Policy Self-Improvement with Modal-level Exploration
May 02, 2025Self-improvement requires robotic systems to initially learn from human-provided data and then gradually enhance their capabilities through interaction with the environment. This is similar to how humans improve their skills through continuous practice. However, achieving effective self-improvement is challenging, primarily because robots tend to repeat their existing abilities during interactions, often failing to generate new, valuable data for learning. In this paper, we identify the key to successful self-improvement: modal-level exploration and data selection. By incorporating a modal-level exploration mechanism during policy execution, the robot can produce more diverse and multi-modal interactions. At the same time, we select the most valuable trials and high-quality segments from these interactions for learning. We successfully demonstrate effective robot self-improvement on both simulation benchmarks and real-world experiments. The capability for self-improvement will enable us to develop more robust and high-success-rate robotic control strategies at a lower cost. Our code and experiment scripts are available at https://ericjin2002.github.io/SIME/
Novel Demonstration Generation with Gaussian Splatting Enables Robust One-Shot Manipulation
Apr 17, 2025


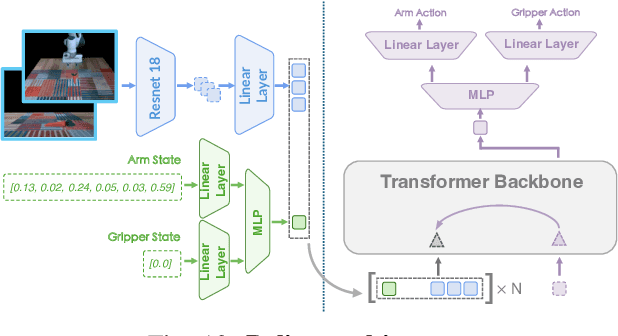
Visuomotor policies learned from teleoperated demonstrations face challenges such as lengthy data collection, high costs, and limited data diversity. Existing approaches address these issues by augmenting image observations in RGB space or employing Real-to-Sim-to-Real pipelines based on physical simulators. However, the former is constrained to 2D data augmentation, while the latter suffers from imprecise physical simulation caused by inaccurate geometric reconstruction. This paper introduces RoboSplat, a novel method that generates diverse, visually realistic demonstrations by directly manipulating 3D Gaussians. Specifically, we reconstruct the scene through 3D Gaussian Splatting (3DGS), directly edit the reconstructed scene, and augment data across six types of generalization with five techniques: 3D Gaussian replacement for varying object types, scene appearance, and robot embodiments; equivariant transformations for different object poses; visual attribute editing for various lighting conditions; novel view synthesis for new camera perspectives; and 3D content generation for diverse object types. Comprehensive real-world experiments demonstrate that RoboSplat significantly enhances the generalization of visuomotor policies under diverse disturbances. Notably, while policies trained on hundreds of real-world demonstrations with additional 2D data augmentation achieve an average success rate of 57.2%, RoboSplat attains 87.8% in one-shot settings across six types of generalization in the real world.
AirExo-2: Scaling up Generalizable Robotic Imitation Learning with Low-Cost Exoskeletons
Mar 05, 2025Scaling up imitation learning for real-world applications requires efficient and cost-effective demonstration collection methods. Current teleoperation approaches, though effective, are expensive and inefficient due to the dependency on physical robot platforms. Alternative data sources like in-the-wild demonstrations can eliminate the need for physical robots and offer more scalable solutions. However, existing in-the-wild data collection devices have limitations: handheld devices offer restricted in-hand camera observation, while whole-body devices often require fine-tuning with robot data due to action inaccuracies. In this paper, we propose AirExo-2, a low-cost exoskeleton system for large-scale in-the-wild demonstration collection. By introducing the demonstration adaptor to transform the collected in-the-wild demonstrations into pseudo-robot demonstrations, our system addresses key challenges in utilizing in-the-wild demonstrations for downstream imitation learning in real-world environments. Additionally, we present RISE-2, a generalizable policy that integrates 2D and 3D perceptions, outperforming previous imitation learning policies in both in-domain and out-of-domain tasks, even with limited demonstrations. By leveraging in-the-wild demonstrations collected and transformed by the AirExo-2 system, without the need for additional robot demonstrations, RISE-2 achieves comparable or superior performance to policies trained with teleoperated data, highlighting the potential of AirExo-2 for scalable and generalizable imitation learning. Project page: https://airexo.tech/airexo2
JoyGen: Audio-Driven 3D Depth-Aware Talking-Face Video Editing
Jan 03, 2025



Significant progress has been made in talking-face video generation research; however, precise lip-audio synchronization and high visual quality remain challenging in editing lip shapes based on input audio. This paper introduces JoyGen, a novel two-stage framework for talking-face generation, comprising audio-driven lip motion generation and visual appearance synthesis. In the first stage, a 3D reconstruction model and an audio2motion model predict identity and expression coefficients respectively. Next, by integrating audio features with a facial depth map, we provide comprehensive supervision for precise lip-audio synchronization in facial generation. Additionally, we constructed a Chinese talking-face dataset containing 130 hours of high-quality video. JoyGen is trained on the open-source HDTF dataset and our curated dataset. Experimental results demonstrate superior lip-audio synchronization and visual quality achieved by our method.
TieBot: Learning to Knot a Tie from Visual Demonstration through a Real-to-Sim-to-Real Approach
Jul 03, 2024



The tie-knotting task is highly challenging due to the tie's high deformation and long-horizon manipulation actions. This work presents TieBot, a Real-to-Sim-to-Real learning from visual demonstration system for the robots to learn to knot a tie. We introduce the Hierarchical Feature Matching approach to estimate a sequence of tie's meshes from the demonstration video. With these estimated meshes used as subgoals, we first learn a teacher policy using privileged information. Then, we learn a student policy with point cloud observation by imitating teacher policy. Lastly, our pipeline learns a residual policy when the learned policy is applied to real-world execution, mitigating the Sim2Real gap. We demonstrate the effectiveness of TieBot in simulation and the real world. In the real-world experiment, a dual-arm robot successfully knots a tie, achieving 50% success rate among 10 trials. Videos can be found on our $\href{https://tiebots.github.io/}{\text{website}}$.