 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$π$-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
May 14, 2026The rise of personal assistant agents, e.g., OpenClaw, highlights the growing potential of large language models to support users across everyday life and work. A core challenge in these settings is proactive assistance, since users often begin with underspecified requests and leave important needs, constraints, or preferences unstated. However, existing benchmarks rarely evaluate whether agents can identify and act on such hidden intents before they are explicitly stated, especially in sustained multi-turn interactions where user needs emerge gradually. To address this gap, we introduce $π$-Bench, a benchmark for proactive assistance comprising 100 multi-turn tasks across 5 domain-specific user personas. By incorporating hidden user intents, inter-task dependencies, and cross-session continuity, $π$-Bench evaluates agents' ability to anticipate and address user needs over extended interactions, jointly measuring proactivity and task completion in long-horizon trajectories that better reflect real-world use. Experiments show (1) proactive assistance remains challenging, (2) a clear distinction between task completion and proactivity, and (3) the value of prior interaction for proactive intent resolution in later tasks.
$S^3$: Stratified Scaling Search for Test-Time in Diffusion Language Models
Apr 07, 2026Test-time scaling investigates whether a fixed diffusion language model (DLM) can generate better outputs when given more inference compute, without additional training. However, naive best-of-$K$ sampling is fundamentally limited because it repeatedly draws from the same base diffusion distribution, whose high-probability regions are often misaligned with high-quality outputs. We propose $S^3$ (Stratified Scaling Search), a classical verifier-guided search method that improves generation by reallocating compute during the denoising process rather than only at the final output stage. At each denoising step, $S^3$ expands multiple candidate trajectories, evaluates them with a lightweight reference-free verifier, and selectively resamples promising candidates while preserving diversity within the search frontier. This procedure effectively approximates a reward-tilted sampling distribution that favors higher-quality outputs while remaining anchored to the model prior. Experiments with LLaDA-8B-Instruct on MATH-500, GSM8K, ARC-Challenge, and TruthfulQA demonstrate that $S^3$ consistently improves performance across benchmarks, achieving the largest gains on mathematical reasoning tasks while leaving the underlying model and decoding schedule unchanged. These results show that classical search over denoising trajectories provides a practical mechanism for test-time scaling in DLMs.
ViBe: Ultra-High-Resolution Video Synthesis Born from Pure Images
Mar 24, 2026Transformer-based video diffusion models rely on 3D attention over spatial and temporal tokens, which incurs quadratic time and memory complexity and makes end-to-end training for ultra-high-resolution videos prohibitively expensive. To overcome this bottleneck, we propose a pure image adaptation framework that upgrades a video Diffusion Transformer pre-trained at its native scale to synthesize higher-resolution videos. Unfortunately, naively fine-tuning with high-resolution images alone often introduces noticeable noise due to the image-video modality gap. To address this, we decouple the learning objective to separately handle modality alignment and spatial extrapolation. At the core of our approach is Relay LoRA, a two-stage adaptation strategy. In the first stage, the video diffusion model is adapted to the image domain using low-resolution images to bridge the modality gap. In the second stage, the model is further adapted with high-resolution images to acquire spatial extrapolation capability. During inference, only the high-resolution adaptation is retained to preserve the video generation modality while enabling high-resolution video synthesis. To enhance fine-grained detail synthesis, we further propose a High-Frequency-Awareness-Training-Objective, which explicitly encourages the model to recover high-frequency components from degraded latent representations via a dedicated reconstruction loss. Extensive experiments demonstrate that our method produces ultra-high-resolution videos with rich visual details without requiring any video training data, even outperforming previous state-of-the-art models trained on high-resolution videos by 0.8 on the VBench benchmark. Code will be available at https://github.com/WillWu111/ViBe.
Force Policy: Learning Hybrid Force-Position Control Policy under Interaction Frame for Contact-Rich Manipulation
Feb 25, 2026Contact-rich manipulation demands human-like integration of perception and force feedback: vision should guide task progress, while high-frequency interaction control must stabilize contact under uncertainty. Existing learning-based policies often entangle these roles in a monolithic network, trading off global generalization against stable local refinement, while control-centric approaches typically assume a known task structure or learn only controller parameters rather than the structure itself. In this paper, we formalize a physically grounded interaction frame, an instantaneous local basis that decouples force regulation from motion execution, and propose a method to recover it from demonstrations. Based on this, we address both issues by proposing Force Policy, a global-local vision-force policy in which a global policy guides free-space actions using vision, and upon contact, a high-frequency local policy with force feedback estimates the interaction frame and executes hybrid force-position control for stable interaction. Real-world experiments across diverse contact-rich tasks show consistent gains over strong baselines, with more robust contact establishment, more accurate force regulation, and reliable generalization to novel objects with varied geometries and physical properties, ultimately improving both contact stability and execution quality. Project page: https://force-policy.github.io/
Bi-Level Prompt Optimization for Multimodal LLM-as-a-Judge
Feb 11, 2026Large language models (LLMs) have become widely adopted as automated judges for evaluating AI-generated content. Despite their success, aligning LLM-based evaluations with human judgments remains challenging. While supervised fine-tuning on human-labeled data can improve alignment, it is costly and inflexible, requiring new training for each task or dataset. Recent progress in auto prompt optimization (APO) offers a more efficient alternative by automatically improving the instructions that guide LLM judges. However, existing APO methods primarily target text-only evaluations and remain underexplored in multimodal settings. In this work, we study auto prompt optimization for multimodal LLM-as-a-judge, particularly for evaluating AI-generated images. We identify a key bottleneck: multimodal models can only process a limited number of visual examples due to context window constraints, which hinders effective trial-and-error prompt refinement. To overcome this, we propose BLPO, a bi-level prompt optimization framework that converts images into textual representations while preserving evaluation-relevant visual cues. Our bi-level optimization approach jointly refines the judge prompt and the I2T prompt to maintain fidelity under limited context budgets. Experiments on four datasets and three LLM judges demonstrate the effectiveness of our method.
Continuous-Utility Direct Preference Optimization
Jan 31, 2026Large language model reasoning is often treated as a monolithic capability, relying on binary preference supervision that fails to capture partial progress or fine-grained reasoning quality. We introduce Continuous Utility Direct Preference Optimization (CU-DPO), a framework that aligns models to a portfolio of prompt-based cognitive strategies by replacing binary labels with continuous scores that capture fine-grained reasoning quality. We prove that learning with K strategies yields a Theta(K log K) improvement in sample complexity over binary preferences, and that DPO converges to the entropy-regularized utility-maximizing policy. To exploit this signal, we propose a two-stage training pipeline: (i) strategy selection, which optimizes the model to choose the best strategy for a given problem via best-vs-all comparisons, and (ii) execution refinement, which trains the model to correctly execute the selected strategy using margin-stratified pairs. On mathematical reasoning benchmarks, CU-DPO improves strategy selection accuracy from 35-46 percent to 68-78 percent across seven base models, yielding consistent downstream reasoning gains of up to 6.6 points on in-distribution datasets with effective transfer to out-of-distribution tasks.
FreeSwim: Revisiting Sliding-Window Attention Mechanisms for Training-Free Ultra-High-Resolution Video Generation
Nov 18, 2025The quadratic time and memory complexity of the attention mechanism in modern Transformer based video generators makes end-to-end training for ultra high resolution videos prohibitively expensive. Motivated by this limitation, we introduce a training-free approach that leverages video Diffusion Transformers pretrained at their native scale to synthesize higher resolution videos without any additional training or adaptation. At the core of our method lies an inward sliding window attention mechanism, which originates from a key observation: maintaining each query token's training scale receptive field is crucial for preserving visual fidelity and detail. However, naive local window attention, unfortunately, often leads to repetitive content and exhibits a lack of global coherence in the generated results. To overcome this challenge, we devise a dual-path pipeline that backs up window attention with a novel cross-attention override strategy, enabling the semantic content produced by local attention to be guided by another branch with a full receptive field and, therefore, ensuring holistic consistency. Furthermore, to improve efficiency, we incorporate a cross-attention caching strategy for this branch to avoid the frequent computation of full 3D attention. Extensive experiments demonstrate that our method delivers ultra-high-resolution videos with fine-grained visual details and high efficiency in a training-free paradigm. Meanwhile, it achieves superior performance on VBench, even compared to training-based alternatives, with competitive or improved efficiency. Codes are available at: https://github.com/WillWu111/FreeSwim
On the Fundamental Limits of LLMs at Scale
Nov 17, 2025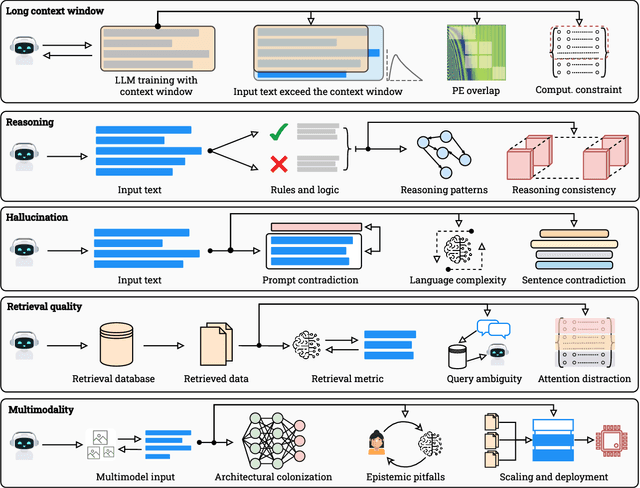
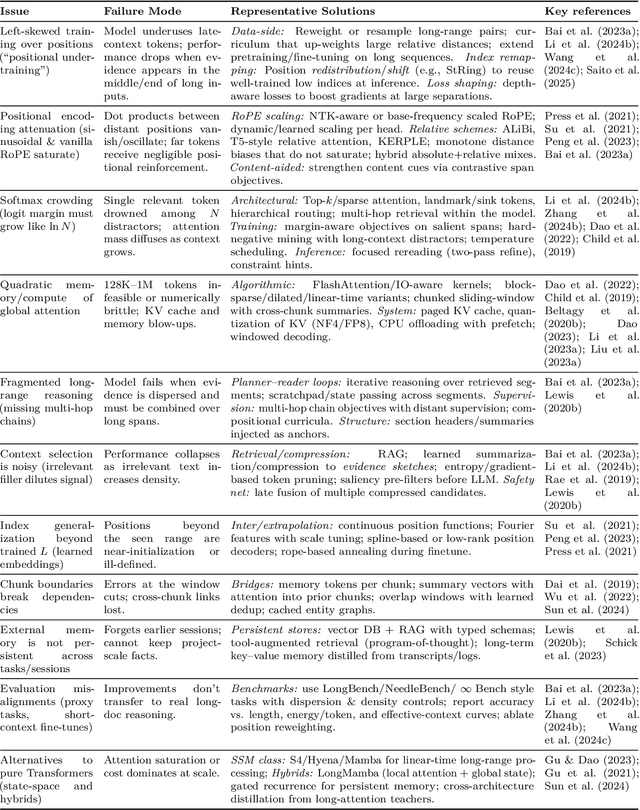
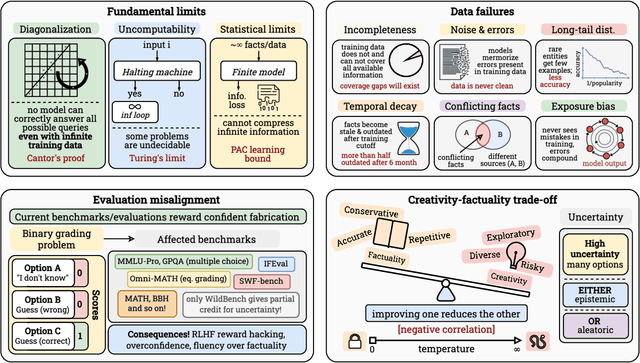
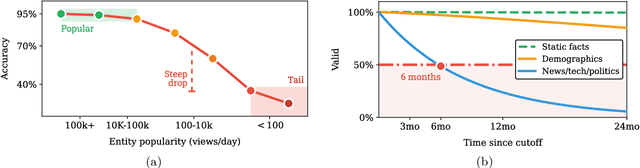
Large Language Models (LLMs) have benefited enormously from scaling, yet these gains are bounded by five fundamental limitations: (1) hallucination, (2) context compression, (3) reasoning degradation, (4) retrieval fragility, and (5) multimodal misalignment. While existing surveys describe these phenomena empirically, they lack a rigorous theoretical synthesis connecting them to the foundational limits of computation, information, and learning. This work closes that gap by presenting a unified, proof-informed framework that formalizes the innate theoretical ceilings of LLM scaling. First, computability and uncomputability imply an irreducible residue of error: for any computably enumerable model family, diagonalization guarantees inputs on which some model must fail, and undecidable queries (e.g., halting-style tasks) induce infinite failure sets for all computable predictors. Second, information-theoretic and statistical constraints bound attainable accuracy even on decidable tasks, finite description length enforces compression error, and long-tail factual knowledge requires prohibitive sample complexity. Third, geometric and computational effects compress long contexts far below their nominal size due to positional under-training, encoding attenuation, and softmax crowding. We further show how likelihood-based training favors pattern completion over inference, how retrieval under token limits suffers from semantic drift and coupling noise, and how multimodal scaling inherits shallow cross-modal alignment. Across sections, we pair theorems and empirical evidence to outline where scaling helps, where it saturates, and where it cannot progress, providing both theoretical foundations and practical mitigation paths like bounded-oracle retrieval, positional curricula, and sparse or hierarchical attention.
STEER-BENCH: A Benchmark for Evaluating the Steerability of Large Language Models
May 27, 2025Steerability, or the ability of large language models (LLMs) to adapt outputs to align with diverse community-specific norms, perspectives, and communication styles, is critical for real-world applications but remains under-evaluated. We introduce Steer-Bench, a benchmark for assessing population-specific steering using contrasting Reddit communities. Covering 30 contrasting subreddit pairs across 19 domains, Steer-Bench includes over 10,000 instruction-response pairs and validated 5,500 multiple-choice question with corresponding silver labels to test alignment with diverse community norms. Our evaluation of 13 popular LLMs using Steer-Bench reveals that while human experts achieve an accuracy of 81% with silver labels, the best-performing models reach only around 65% accuracy depending on the domain and configuration. Some models lag behind human-level alignment by over 15 percentage points, highlighting significant gaps in community-sensitive steerability. Steer-Bench is a benchmark to systematically assess how effectively LLMs understand community-specific instructions, their resilience to adversarial steering attempts, and their ability to accurately represent diverse cultural and ideological perspectives.
BUFF: Bayesian Uncertainty Guided Diffusion Probabilistic Model for Single Image Super-Resolution
Apr 04, 2025Super-resolution (SR) techniques are critical for enhancing image quality, particularly in scenarios where high-resolution imagery is essential yet limited by hardware constraints. Existing diffusion models for SR have relied predominantly on Gaussian models for noise generation, which often fall short when dealing with the complex and variable texture inherent in natural scenes. To address these deficiencies, we introduce the Bayesian Uncertainty Guided Diffusion Probabilistic Model (BUFF). BUFF distinguishes itself by incorporating a Bayesian network to generate high-resolution uncertainty masks. These masks guide the diffusion process, allowing for the adjustment of noise intensity in a manner that is both context-aware and adaptive. This novel approach not only enhances the fidelity of super-resolved images to their original high-resolution counterparts but also significantly mitigates artifacts and blurring in areas characterized by complex textures and fine details. The model demonstrates exceptional robustness against complex noise patterns and showcases superior adaptability in handling textures and edges within images. Empirical evidence, supported by visual results, illustrates the model's robustness, especially in challenging scenarios, and its effectiveness in addressing common SR issues such as blurring. Experimental evaluations conducted on the DIV2K dataset reveal that BUFF achieves a notable improvement, with a +0.61 increase compared to baseline in SSIM on BSD100, surpassing traditional diffusion approaches by an average additional +0.20dB PSNR gain. These findings underscore the potential of Bayesian methods in enhancing diffusion processes for SR, paving the way for future advancements in the field.