 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeelings about Bodies: Emotions on Diet and Fitness Forums Reveal Gendered Stereotypes and Body Image Concerns
Jul 04, 2024
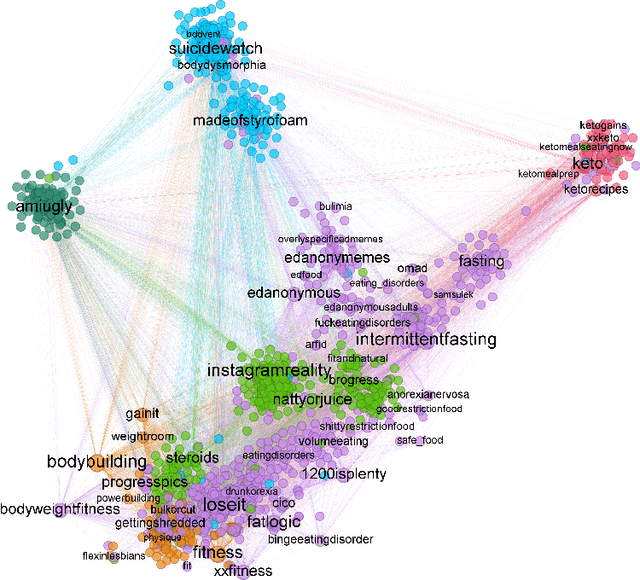
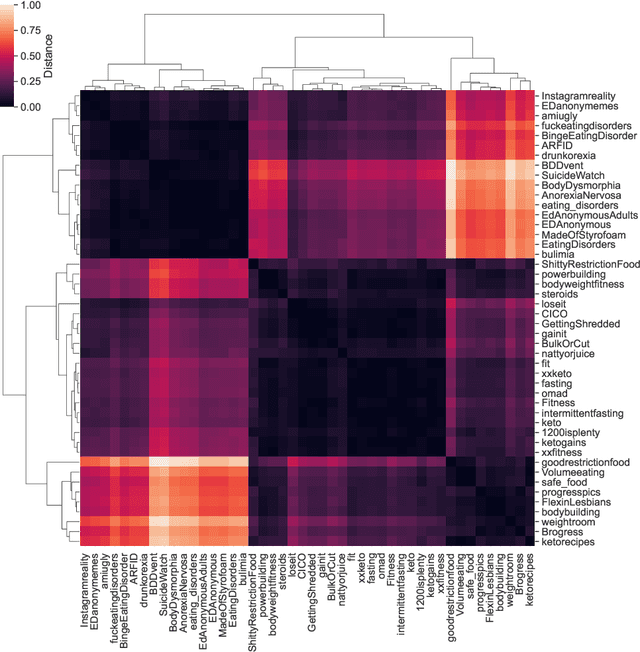
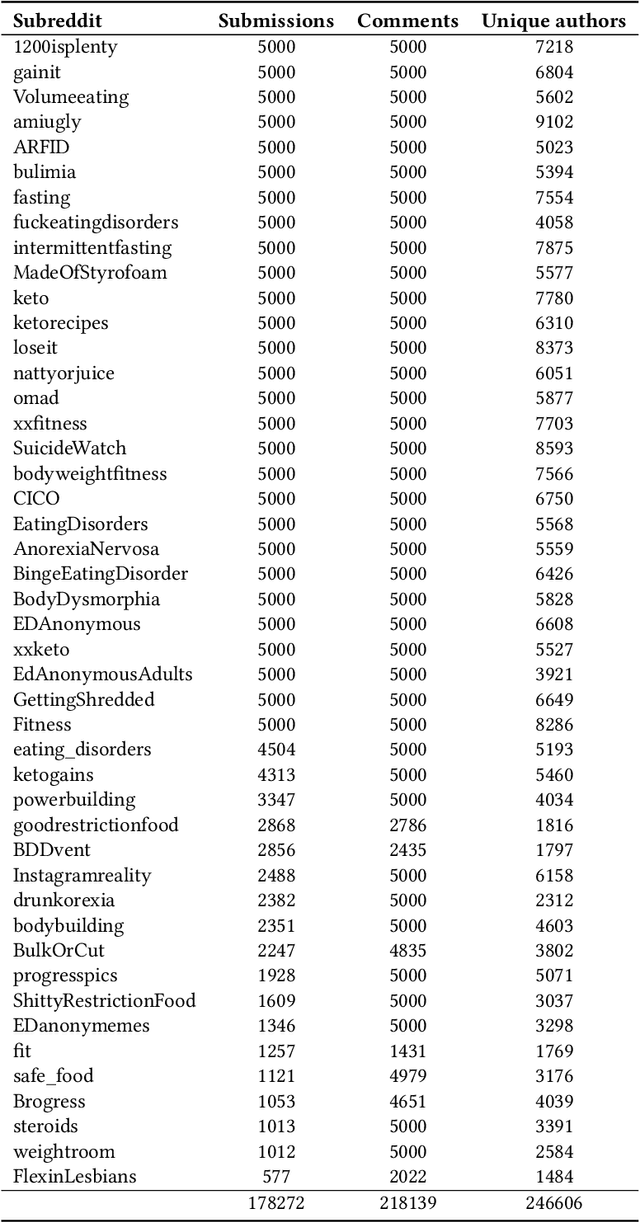
The gendered expectations about ideal body types can lead to body image concerns, dissatisfaction, and in extreme cases, disordered eating and other psychopathologies across the gender spectrum. While research has focused on pro-anorexia online communities that glorify the 'thin ideal', less attention has been given to the broader spectrum of body image concerns or how emerging disorders like muscle dysmorphia ('bigorexia') present in online discussions. To address these gaps, we analyze 46 Reddit discussion forums related to diet, fitness, and associated mental health challenges. Using membership structure analysis and transformer-based language models, we project these communities along gender and body ideal axes, revealing complex interactions between gender, body ideals, and emotional expression. Our findings show that feminine-oriented communities generally express more negative emotions, particularly in thinness-promoting forums. Conversely, communities focused on the muscular ideal exhibit less negativity, regardless of gender orientation. We also uncover a gendered pattern in emotional indicators of mental health challenges, with communities discussing serious issues aligning more closely with thinness-oriented, predominantly feminine-leaning communities. By revealing the gendered emotional dynamics of online communities, our findings can inform the development of more effective content moderation approaches that facilitate supportive interactions, while minimizing exposure to potentially harmful content.
Cross-Lingual and Cross-Domain Crisis Classification for Low-Resource Scenarios
Sep 05, 2022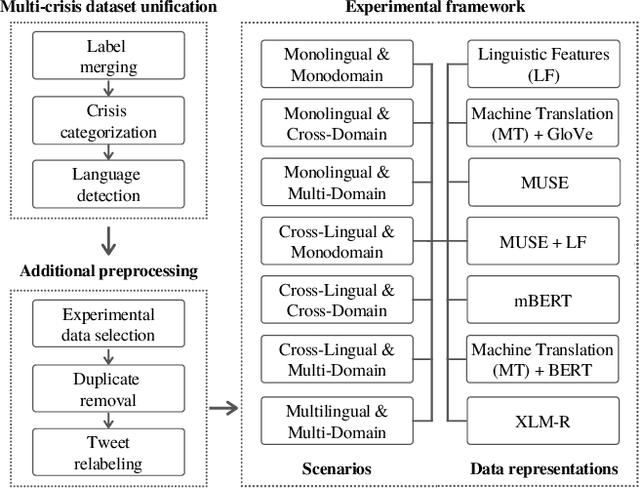
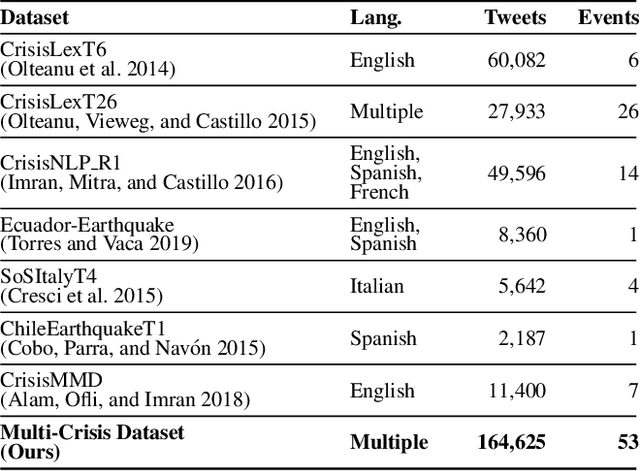
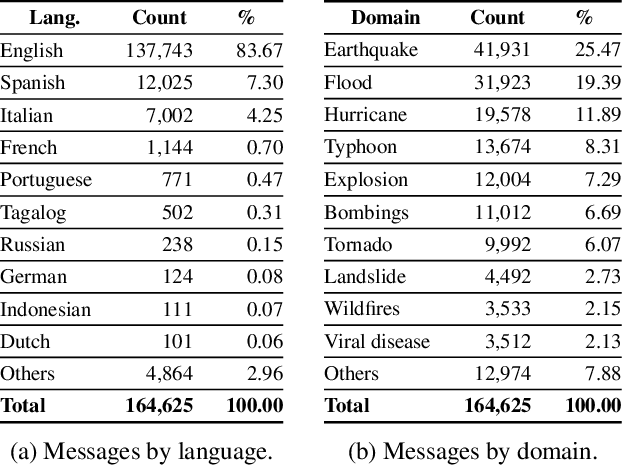
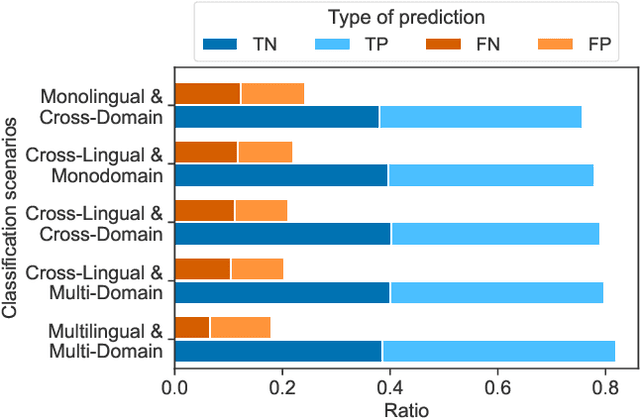
Social media data has emerged as a useful source of timely information about real-world crisis events. One of the main tasks related to the use of social media for disaster management is the automatic identification of crisis-related messages. Most of the studies on this topic have focused on the analysis of data for a particular type of event in a specific language. This limits the possibility of generalizing existing approaches because models cannot be directly applied to new types of events or other languages. In this work, we study the task of automatically classifying messages that are related to crisis events by leveraging cross-language and cross-domain labeled data. Our goal is to make use of labeled data from high-resource languages to classify messages from other (low-resource) languages and/or of new (previously unseen) types of crisis situations. For our study we consolidated from the literature a large unified dataset containing multiple crisis events and languages. Our empirical findings show that it is indeed possible to leverage data from crisis events in English to classify the same type of event in other languages, such as Spanish and Italian (80.0% F1-score). Furthermore, we achieve good performance for the cross-domain task (80.0% F1-score) in a cross-lingual setting. Overall, our work contributes to improving the data scarcity problem that is so important for multilingual crisis classification. In particular, mitigating cold-start situations in emergency events, when time is of essence.